
实时 Linux 内核调度器
许多市场领域,如金融交易、国防、工业自动化和游戏,长期以来一直需要低延迟和确定性的响应时间。传统上,定制构建的硬件和软件被用于满足这些实时需求。然而,对于一些软实时需求,其中响应时间的可预测性是有利的而非强制性的,这是一种昂贵的解决方案。随着由 Ingo Molnar 领导的 PREEMPT_RT 补丁集(以下简称 -rt)的出现,Linux 在“企业实时”应用的实时操作系统领域取得了巨大进展。对通用 Linux 内核进行了许多修改,使 Linux 成为实时的可行选择,例如调度器、中断处理、锁定机制等等。
实时系统是指为事件和事务提供有保证的系统响应时间的系统——也就是说,每个操作都应在某个严格的时间段内完成。如果错过截止日期会导致系统故障,则系统被归类为硬实时系统;如果系统可以容忍一些错过的时间约束,则系统被归类为软实时系统。
实时系统要求任务以严格的优先级顺序执行。这要求在任何给定时间点,只有 N 个最高优先级的任务在运行,其中 N 是 CPU 的数量。此要求的变体可以是给定 CPU 子集或调度域(在本文后面解释)中的严格优先级排序调度。在这两种情况下,当任务可运行时,调度器必须确保将其放置在可以立即运行的运行队列上——也就是说,实时调度器必须确保系统范围的严格实时优先级调度(SWSRPS)。与非实时系统(其中调度器只需要查看其任务运行队列即可做出调度决策)不同,实时调度器会做出全局调度决策,从而在任何给定时间考虑系统中的所有任务。还必须频繁执行实时任务平衡。任务平衡可能会导致缓存抖动和全局数据(例如运行队列锁)的争用,并可能降低吞吐量和可伸缩性。实时任务调度器会牺牲吞吐量以换取正确性,但同时,它必须确保最小的任务乒乓。
标准 Linux 内核提供两种实时调度策略,SCHED_FIFO 和 SCHED_RR。主要的实时策略是 SCHED_FIFO。它实现了先进先出调度算法。当 SCHED_FIFO 任务开始运行时,它将继续运行,直到它自愿让出处理器、阻塞或被更高优先级的实时任务抢占。它没有时间片。所有其他较低优先级的任务都不会被调度,直到它放弃 CPU。两个同等优先级的 SCHED_FIFO 任务不会互相抢占。SCHED_RR 类似于 SCHED_FIFO,不同之处在于此类任务会根据其优先级分配时间片,并运行直到它们耗尽其时间片。非实时任务使用 SCHED_NORMAL 调度策略(较旧的内核具有名为 SCHED_OTHER 的策略)。
在标准 Linux 内核中,实时优先级范围从零到 (MAX_RT_PRIO-1),包括在内。默认情况下,MAX_RT_PRIO 为 100。非实时任务的优先级范围为 MAX_RT_PRIO 到 (MAX_RT_PRIO + 40)。这构成了 SCHED_NORMAL 任务的 nice 值。默认情况下,-20 到 19 的 nice 范围直接映射到 100 到 139 的优先级范围。
本文假设读者了解任务调度器的基础知识。有关 Linux 完全公平调度器 (CFS) 的更多信息,请参阅资源。
-rt 补丁集的实时调度器采用 Steven Rostedt 和 Gregory Haskins 开发的主动推拉策略,用于跨 CPU 平衡任务。调度器必须解决以下几种情况
在唤醒时将任务最佳地放置在何处(即,预平衡)。
当较低优先级的任务唤醒但位于运行队列上运行较高优先级的任务时,该怎么办。
当同一运行队列上的较高优先级任务唤醒并抢占较低优先级任务时,该怎么办。
当任务降低其优先级,从而导致先前较低优先级的任务具有较高优先级时,该怎么办。
在上述情况 2 和 3 中启动推送操作。推送算法考虑其根域(稍后讨论)内的所有运行队列,以找到优先级低于要推送的任务的运行队列。
对于上述情况 4 执行拉取操作。每当运行队列即将调度优先级低于先前任务的任务时,它会检查是否可以从其他运行队列中拉取更高优先级的任务。
实时任务仅受推送和拉取操作的影响。CFS 负载平衡算法根本不处理实时任务,因为已观察到负载平衡会将实时任务从正确分配给它们的运行队列中拉走,从而导致不必要的延迟。
主要的每个 CPU 运行队列数据结构 struct rq,包含一个结构 struct rt_rq,它封装了有关放置在每个 CPU 运行队列上的实时任务的信息,如清单 1 所示。
清单 1. struct rt_rq
struct rt_rq {
struct rt_prio_array active;
...
unsigned long rt_nr_running;
unsigned long rt_nr_migratory;
unsigned long rt_nr_uninterruptible;
int highest_prio;
int overloaded;
};
实时任务的优先级范围为 0-99。这些任务在运行队列上以优先级索引数组 active(类型为 struct rt_prio_array)组织。rt_prio_array 由子队列数组组成。每个优先级级别都有一个子队列。每个子队列都包含相应优先级级别的可运行实时任务。还有一个与数组对应的位掩码,用于有效地确定运行队列上优先级最高的任务。
rt_nr_running 和 rt_nr_uninterruptible 分别是可运行实时任务的数量和 TASK_UNINTERRUPTIBLE 状态的任务数量的计数。
rt_nr_migratory 指示运行队列上可以迁移到其他运行队列的任务数量。某些实时任务绑定到特定的 CPU,例如内核线程 softirq-timer。很可能许多此类关联线程同时在 CPU 上唤醒。例如,softirq-timer 线程可能会导致 softirq-sched 内核线程变为活动状态,从而导致两个实时任务变为可运行状态。这会导致运行队列因实时任务而过载。当过载时,实时调度器通常会导致其他 CPU 拉取任务。但是,由于其 CPU 亲和性,这些任务无法被另一个 CPU 拉取。其他 CPU 无法在不增加锁定多个数据结构的开销的情况下确定这一点。可以通过维护运行队列上可以迁移到其他 CPU 的任务数量来避免这种情况。当任务添加到运行队列时,会查看 task->cpus_allowed 掩码的汉明权重(缓存在 task->rt.nr_cpus_allowed 中)。如果该值大于 1,则运行队列的 rt_nr_migratory 字段将递增 1。当运行队列包含多个实时任务并且至少其中一个任务可以迁移到另一个运行队列时,将设置 overloaded 字段。每当实时任务在运行队列上排队时,都会更新它。
highest_prio 字段指示运行队列上排队的最高优先级任务的优先级。这可能不是当前在运行队列上执行的任务的优先级(最高优先级任务可能刚刚在运行队列上排队,并且正在等待调度)。每当任务在运行队列上排队时,都会更新此变量。扫描每个运行队列以找到用于推送任务的最低优先级运行队列时,会使用 highest_prio 的值。如果目标运行队列的 highest_prio 小于要推送的任务,则该任务将被推送到该运行队列。
图 1 显示了示例场景中上述数据结构的值。
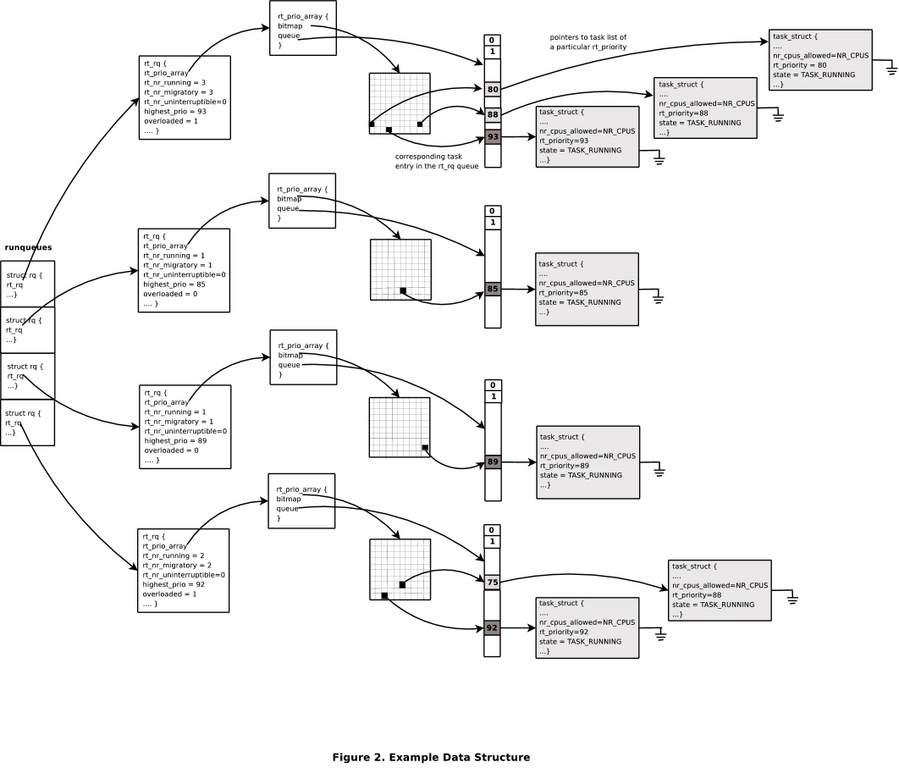
图 1. 示例运行队列
如前所述,由于实时调度器需要多个全局或系统范围的资源来做出调度决策,因此随着 CPU 数量的增加,可伸缩性瓶颈就会出现(由于保护这些资源的锁的争用增加)。例如,为了找出系统是否因实时任务而过载(即,具有比 CPU 数量更多的可运行实时任务),它需要查看所有运行队列的状态。在早期版本中,使用全局 rt_overload 变量来跟踪系统上所有运行队列的状态。然后,调度器会在每次调用 schedule() 例程时使用此变量,从而导致巨大的争用。
最近,对调度器进行了一些增强,以减少此类变量的争用,从而提高可伸缩性。Gregory Haskins 为此目的引入了根域的概念。cpusets 提供了一种将 CPU 分区为进程或进程组使用的子集的机制。多个 cpuset 可以重叠。如果没有任何其他 cpuset 包含重叠的 CPU,则 cpuset 称为独占 cpuset。每个独占 cpuset 定义一个与其他 cpuset 或 CPU 分区的隔离域(称为根域)。与每个根域相关的信息存储在 struct root_domain 中,如清单 2 所示。这些根域用于将全局变量的范围缩小到每个域的变量。每当创建独占 cpuset 时,都会创建一个新的根域对象,其中包含来自成员 CPU 的信息。默认情况下,会创建一个包含所有 CPU 作为成员的单个高级根域。通过重新调整 rt_overload 变量的范围,缓存行弹跳将仅影响特定域的成员,而不是整个系统。所有实时调度决策都仅在根域的范围内做出。
清单 2. struct root_domain
struct root_domain {
atomic_t refcount; /* reference count for the domain */
cpumask_t span; /* span of member cpus of the domain*/
cpumask_t online; /* number of online cpus in the domain*/
cpumask_t rto_mask; /* mask of overloaded cpus in the domain*/
atomic_t rto_count; /* number of overloaded cpus */
....
};
CPU 优先级管理也是 Gregory Haskins 引入的基础架构,旨在提高任务迁移决策的效率。此代码跟踪系统中每个 CPU 的优先级。每个 CPU 可以处于以下状态之一:INVALID、IDLE、NORMAL、RT1、... RT99。
处于 INVALID 状态的 CPU 没有资格进行任务路由。系统使用二维位图维护此状态:一个维度用于不同的优先级级别,第二个维度用于该优先级级别中的 CPU(CPU 的优先级等效于 rq->rt.highest_prio)。这是使用三个数组实现的,如清单 3 所示。
清单 3. struct cpupri
struct cpupri {
struct cpupri_vec pri_to_cpu[CPUPRI_NR_PRIORITIES];
long pri_active[CPUPRI_NR_PRI_WORDS];
int cpu_to_pri[NR_CPUS];
};
pri_active 位图跟踪包含一个或多个 CPU 的那些优先级级别。例如,如果优先级 49 处有一个 CPU,则 pri_active[49+2]=1(实时任务优先级在内部映射到 2-102,以便考虑优先级 INVALID 和 IDLE),查找此数组的第一个设置位将产生给定 cpuset 中的任何 CPU 所处的最低优先级。
字段 cpu_to_pri 指示 CPU 的优先级。
字段 pri_to_cpu 产生有关 cpuset 中处于特定优先级级别的所有 CPU 的信息。这封装在 struct cpupri_vec 中,如清单 4 所示。
与 rt_overload 一样,cpupri 的范围也限定在根域级别。每个构成根域的独占 cpuset 都包含一个 cpupri 数据值。
清单 4. struct cpupri_vec
struct cpupri_vec {
raw_spinlock_t lock;
int count; /* number of cpus at a priority level */
cpumask_t mask; /* mask of cpus at a priority level */
};
CPU 优先级管理基础架构用于查找要将任务推送到的 CPU,如清单 5 所示。应注意,执行搜索时未获取任何锁。
清单 5. 查找要将任务推送到的 CPU
int cpupri_find(struct cpupri *cp,
struct task_struct *p,
cpumask_t *lowest_mask)
{
...
for_each_cpupri_active(cp->pri_active, idx) {
struct cpupri_vec *vec = &cp->pri_to_cpu[idx];
cpumask_t mask;
if (idx >= task_pri)
break;
cpus_and(mask, p->cpus_allowed, vec->mask);
if (cpus_empty(mask))
continue;
*lowest_mask = mask;
return 1;
}
return 0;
}
如果优先级级别为非空且低于要推送的任务的优先级,则 lowest_mask 将设置为与所选优先级级别对应的掩码。然后,推送算法使用此掩码来计算最佳 CPU,以将任务推送到该 CPU,这基于亲和性、拓扑和缓存特性。
如前所述,为了确保 SWSRPS,当低优先级实时任务被较高优先级任务抢占,或者当任务在已经有较高优先级任务在其上运行的运行队列上唤醒时,调度器需要搜索合适的任务目标运行队列。搜索运行队列并将其中一个任务传输到另一个运行队列的此操作称为推送任务。
push_rt_task() 算法查看运行队列上优先级最高的非运行可运行实时任务,并考虑所有运行队列以找到它可以运行的 CPU。它搜索优先级较低的运行队列——也就是说,当前运行的任务可以被正在推送的任务抢占的运行队列。如前所述,CPU 优先级管理基础架构用于查找具有最低优先级运行队列的 CPU 掩码。从所有候选中仅选择最佳 CPU 非常重要。该算法将最高优先级赋予任务上次执行的 CPU,因为它很可能在该位置是缓存热的。如果不可能,则会考虑 sched_domain 映射以查找逻辑上最接近 last_cpu 的 CPU。如果这也失败,则从掩码中随机选择一个 CPU。
推送操作会一直执行,直到实时任务无法迁移或没有更多任务要推送。由于该算法始终选择优先级最高的非运行任务进行推送,因此假设是,如果它无法迁移它,那么很可能较低的实时任务也无法迁移,并且搜索将被中止。扫描最低优先级运行队列时,不会获取任何锁。当找到目标运行队列时,仅获取该运行队列的锁,然后检查以验证它是否仍然是要推送任务的候选对象(因为目标运行队列可能已被另一个 CPU 上的并行调度操作修改)。如果不是,则重复搜索最多三次,之后中止。
pull_rt_task() 算法查看根域中的所有过载运行队列,并检查它们是否具有可以在目标运行队列上运行的实时任务(即,目标 CPU 在 task->cpus_allowed_mask 中),并且优先级高于目标运行队列即将调度的任务。如果是这样,则任务将在目标运行队列上排队。仅在扫描完根域中的所有过载运行队列后,此搜索才会中止。因此,拉取操作可能会将多个任务拉取到目标运行队列。如果该算法仅在第一遍中选择要拉取的候选任务,然后在第二遍中执行实际拉取,则所选的最高优先级任务可能不再是候选任务(由于另一个 CPU 上的并行调度操作)。为了避免在查找最高优先级运行队列和在执行实际拉取时该运行队列仍然是最高优先级任务之间出现竞争,拉取操作会继续拉取任务。在最坏的情况下,这可能会导致大量任务被拉取到目标运行队列,这些任务稍后将被推送到其他 CPU,从而导致任务弹跳。已知任务弹跳是一种罕见的现象。
考虑图 2 中所示的场景。任务 T2 被在运行队列 0 上唤醒的任务 T3 抢占。同样,任务 T7 在运行队列 3 上自愿将 CPU 3 让给任务 T6。我们首先考虑 CPU 0 上的调度操作,然后考虑 CPU 3 上的调度操作。此外,假设所有 CPU 都位于同一根域中。此 CPU 系统的 pri_active 位图将如图 3 所示。括号中的数字表示实际优先级,该优先级偏移了两个(如前所述)。
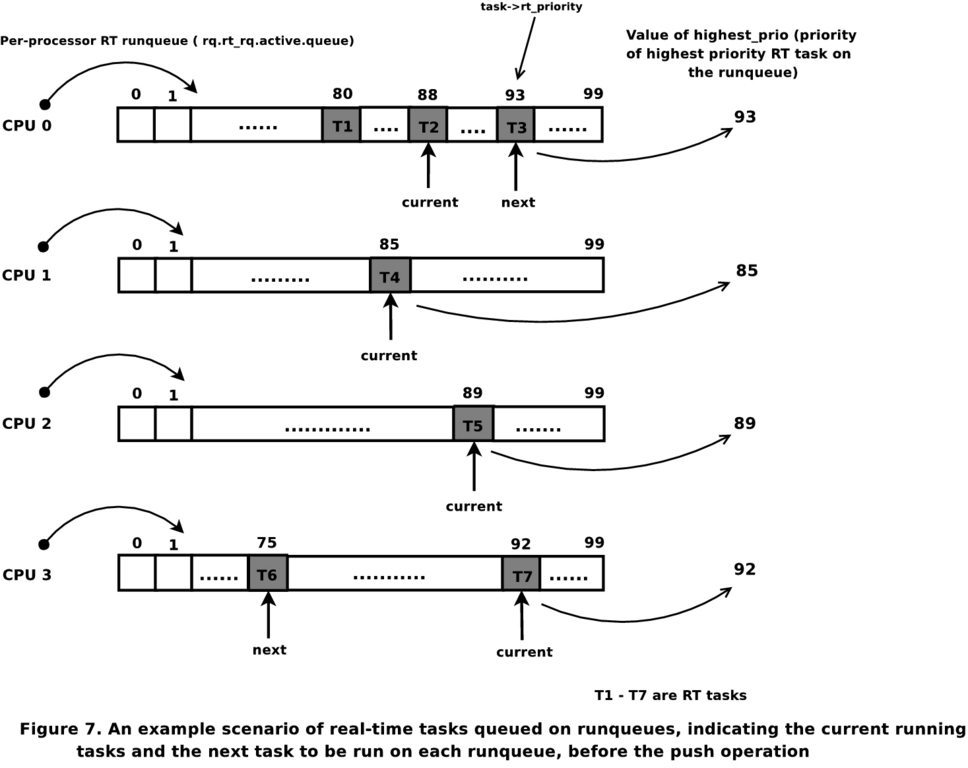
图 2. 运行队列显示推送操作之前正在运行的任务和要运行的下一个任务
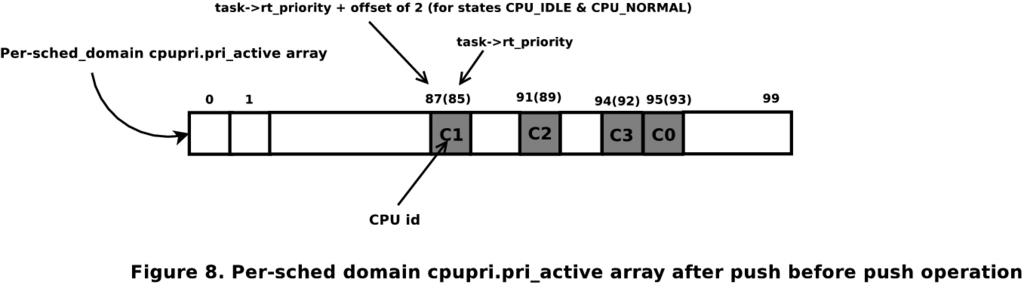
图 3. 推送操作之前的每个调度域 cpupri.pri_active 数组
在 CPU 0 上,后调度算法会发现实时过载下的运行队列。然后,它将启动推送操作。pri_active 的第一个设置位产生 CPU 1 的运行队列,作为适合将任务 T2 推送到的最低优先级运行队列(假设所有正在考虑的任务都没有关联到 CPU 子集)。一旦推送了 T2,推送算法将尝试推送 T1,因为在推送 T2 之后,运行队列仍将处于 RT 过载状态。第一次操作后的 pri_active 将如图 4 所示。由于最低优先级运行队列的优先级高于要推送的任务(优先级为 85 的 T1),因此推送中止。
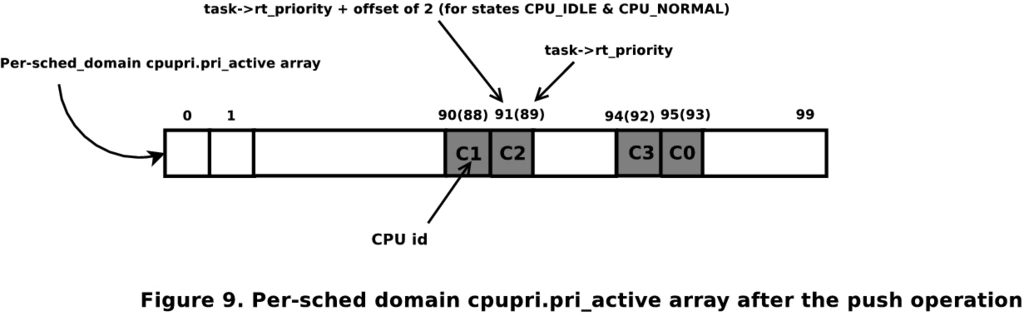
图 4. 推送操作之后的每个调度域 cpupri.pri_active 数组
现在,考虑在 CPU 3 处进行调度,其中优先级为 92 的当前任务自愿放弃 CPU。队列中的下一个任务是 T6。预调度例程将确定运行队列的优先级正在降低,从而触发拉取算法。拉取例程只会考虑处于实时过载状态的运行队列 0 和 1。从运行队列 0 开始,下一个最高优先级任务 T1 的优先级高于要调度的任务 T6,并且由于 T1 < T3 且 T6 < T3,因此 T1 被拉取到运行队列 3。拉取不会在此处中止,因为运行队列 1 仍处于过载状态,并且有可能拉取更高优先级的任务。运行队列 1 上的下一个最高优先级任务 T4 也可以被拉取,因为其优先级高于运行队列 3 上的最高优先级。现在拉取中止,因为没有更多过载的运行队列。所有运行队列的最终状态如图 5 所示,这符合实时系统的调度要求。
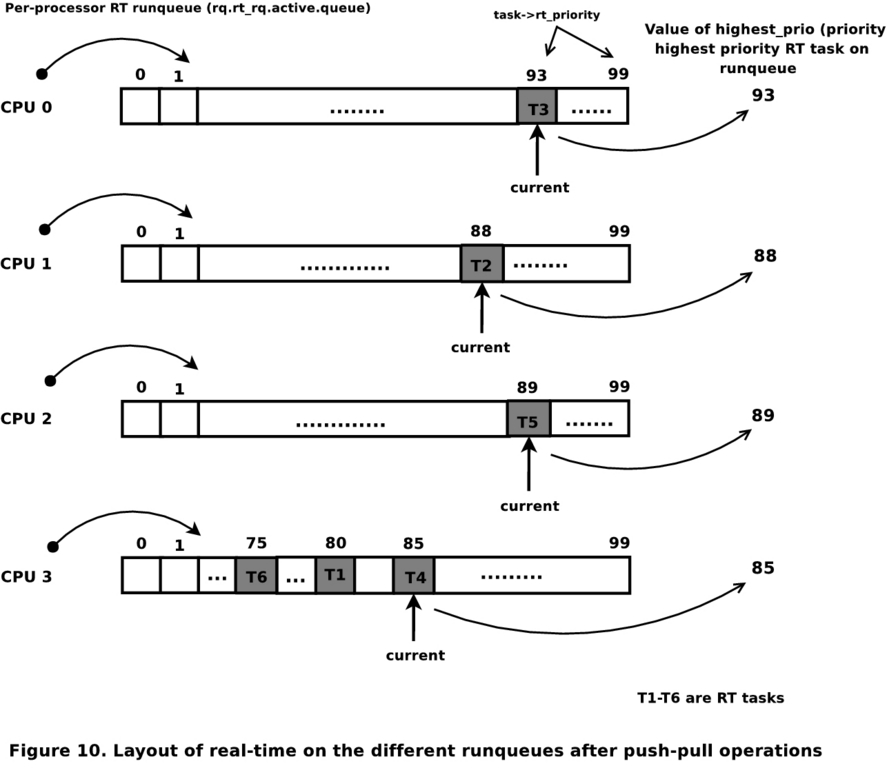
图 5. 推送和拉取操作后的运行队列
尽管已实现严格优先级调度,但运行队列 3 由于拉取操作而处于过载状态。这种情况非常罕见;但是,社区正在努力寻找解决方案。
调度器必须做出许多与锁定相关的决策。运行队列的状态会因上述示例而异,具体取决于何时在运行队列上执行调度操作。为了便于解释,上述示例已得到简化。
实时内核调度器最重要的目标是确保 SWSRPS。CONFIG_PREEMPT_RT 内核中的调度器使用推送和拉取算法来平衡和正确地跨系统分配实时任务。推送和拉取操作都试图确保实时任务尽快获得运行机会。此外,为了减少可能因全局变量争用增加而导致的性能和可伸缩性影响,调度器使用了根域和 CPU 优先级管理的概念。全局变量的范围缩小到 CPU 子集,而不是整个系统,从而显着减少了缓存惩罚并提高了性能。
资源
/pub/linux/kernel/projects/rt 索引(Ingo Molnar): www.kernel.org/pub/linux/kernel/projects/rt
[补丁] 模块化调度器核心和完全公平调度器 [CFS] (Ingo Molnar): lwn.net/Articles/230501
使用完全公平调度器的多处理,Linux CFS 简介: www.ibm.com/developerworks/linux/library/l-cfs/index.html
RT Wiki: rt.wiki.kernel.org
Ankita Garg,毕业于 P.E.S. 技术学院的计算机科学专业,目前在 IBM 印度 Linux 技术中心担任开发人员。她目前正在从事实时 Linux 内核项目。欢迎您将意见和建议发送至 ankita@in.ibm.com。
