
使用 NVIDIA CUDA 进行并行编程
长期以来,程序员们一直对利用显卡的高度并行处理能力来加速非图形性质的应用程序感兴趣。在这里,我将解释如何使用 NVIDIA 的 CUDA API 来做到这一点。如果您的 GPU 不是 NVIDIA 的,您也不必灰心,因为使用其他 API(如基于 ATI 的 Stream SDK 或 OpenCL)也可以实现相同的目标。
通过 GPGPU,通用应用程序直接在显卡的流处理器上执行。在流处理范例下,数据集被命名为流。您可以将其视为类似于操作系统管道功能提供的“文件流”。
流可以是任何独立的数据片段,例如业务事件流或一组科学数据。并行操作通过运算符应用于流,例如拆分、计算或合并。图 1 显示了几个并行的数据流和计算运算符。
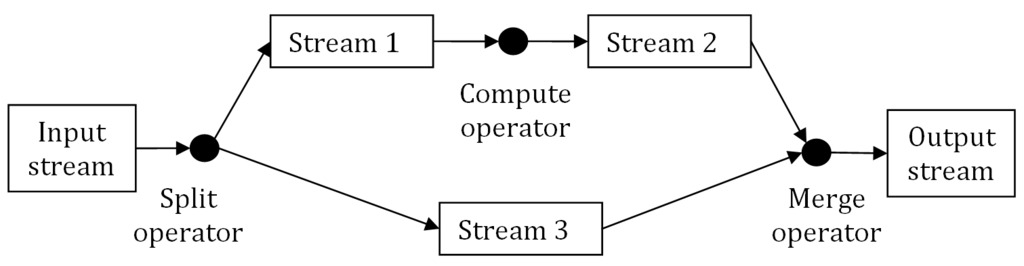
图 1. 流处理图
流处理已成功用于通用编程,包括数据流编程、金融计算和工业自动化,仅举几例。此外,系统工程师和供应商(如戴尔、华硕、Western Scientific 和 Microway)正在构建类似于超级计算机的显卡集群,并且它们的成本仅为基于 CPU 的同类产品的一小部分。
您可以在 NVIDIA 的网站 www.nvidia.com/cuda 上找到许多使用 CUDA 加速来加速真实应用程序的示例。
既然我已经简单介绍了 CUDA 和流处理是什么,让我们开始研究一些您可以用来试一试的计算密集型算法。
向量场是各种行业中使用的结构。在机器人技术中,向量场可以帮助移动机器人穿过房间。让我们定义一个目的地并添加一个或多个障碍物。测试 CUDA 的一个好场景是计算一系列向量,这些向量指示机器人应遵循的方向,以便在避开所有障碍物的同时到达目的地。机器人还应避免局部最小值(见下文)。图 2 显示了机器人和向量场(绿色箭头是“向量”)。

图 2. 移动机器人想要到达板子的中心。向量场显示了路径。
我将目标点称为吸引子,将障碍物称为排斥子——箭头指向吸引子,远离排斥子(图 3)。那么,如何计算向量场呢?向量场由一系列独立的场组成,每个吸引子和排斥子对应一个场。
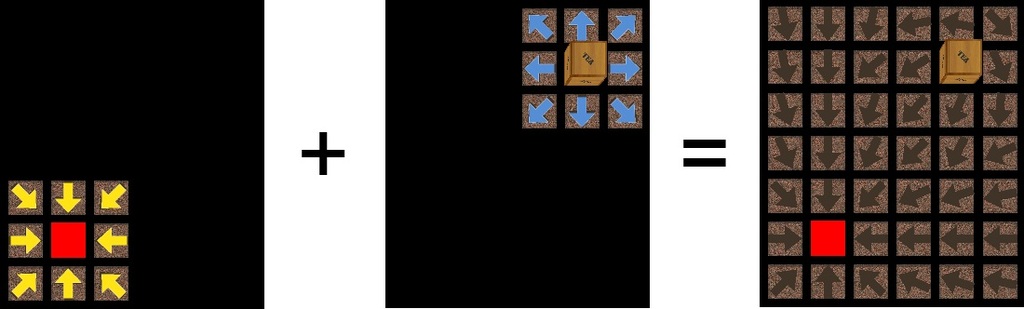
图 3. 吸引子和排斥子
每个独立的场都是通过计算房间中每个点朝向吸引子和远离排斥子的方向来计算的。一旦计算出所有向量,您就可以通过将它们加起来获得完整的向量场。
对于此示例,我将有三个流和两个计算运算符。吸引子和排斥子列表将用作输入流。然后,将对其应用一个计算运算符以获得第二个流:向量场。最后,第二个计算运算符将提供另一个流:局部最小值场。
为什么这是一个 CUDA 的好演示?在决定一个算法是否是并行化的好候选者时,您应该考虑以下标准
问题是否是计算密集型的?
问题可以建模为流处理吗?
代码是否独立于任何共享资源?
哪些代码序列独立于任何其他代码?
数据可以表示为 32 位对象的数组吗?
是否不可能对顺序算法进行优化?
在我的例子中,向量场可能很大,并且在评估整个场时可能需要很长时间。机器人应遵循的路径可以很容易地用流建模。没有对共享资源的访问,并且场中每个元素的计算都独立于所有其他元素。
就计算而言,机器人工程师通常限制他们的算法仅计算在给定时间需要的向量场部分,而从不评估整个向量场。接下来,我将向您展示如何使用流处理来实时计算整个向量场。让我们开始吧。
让我们开发一个向量场计算算法的顺序版本。输入流是吸引子列表和排斥子列表,如图 2 所示,没有障碍物(图 4)。输出流是一个名为 field 的矩阵。吸引子和排斥子是指示其位置的二维点列表。

图 4. 组合吸引子和排斥子
“field”矩阵将保存您的向量场数据结构。每个元素 field[y][x] 将保存一个二维向量,指示当机器人站在点 (x, y) 时应朝哪个方向移动。此向量将是与每个吸引子和排斥子相关的向量的总和(图 5)。

图 5. 向量加法
在处理每个吸引子时,相关的向量将从当前点 (x, y) 指向吸引子的位置。在处理每个排斥子时,相关的向量将指向远离排斥子的位置。请注意,加号和减号运算符正在执行向量加法和减法。顺序伪代码
In Parameters: a list of attractors, a list of repulsors
Out Parameters: a zero-initialized vector field
calculate_vector_field_cpu(in attractors, in repulsors, out field):
for (y = 0 to height):
for (x = 0 to width):
for (attractor in attractors):
vector = attractor - point(x,y)
field[y][x] = field[y][x] + vector
for (repulsor in repulsors):
vector = point(x,y) - repulsor
if norm(vector) <= 2:
field[y][x] = field[y][x] + vector
return
好的,顺序伪代码已准备就绪。现在,让我们划分问题,以便充分利用 GPU 上的处理核心。
每个向量场元素的计算独立于其他元素的计算。您可以利用此属性来并行化您的算法。您可以在自己的线程中计算向量场矩阵的每个元素,从而有效地将问题划分为更小的部分。
不必担心线程数。NVIDIA 鼓励在开发 CUDA 算法时生成尽可能多的线程。这将使算法能够跨多代设备扩展,随着 NVIDIA 向其显卡添加越来越多的处理核心,自动提高吞吐量。
考虑到这一点,让我们开发我们之前算法的并行版本。并行伪代码
In Parameters: list of attractors, list of repulsors
Out Parameters: a zero-initialized vector field
calculate_vector_field_gpu(in attractors, in repulsors, out field):
x = blockIdx.x * BLOCK_SIZE + threadIdx.x
y = blockIdx.y * BLOCK_SIZE + threadIdx.y
for (attractor in attractors):
vector = attractor - point(x,y)
field[y][x] = field[y][x] + vector
for (repulsor in repulsors):
vector = point(x,y) - repulsor
if norm(vector) <= 2:4444444444
field[y][x] = field[y][x] + vector
return
请注意,我取消了两个外部 for 循环,现在使用并行语句计算点 (x, y)。
新的伪代码被实现为一个内核。内核是一个同时在多个 GPU 核心上执行的函数。内核由主机程序启动,主机程序由常规 CPU 控制,该 CPU 配置执行环境并提供参数。
每个线程如何知道它必须计算向量场的哪个位置?这就是 blockIdx 和 threadIdx 内置 CUDA 变量发挥作用的地方。
当您查看此代码时,可能不清楚这如何是并行实现,但正是 blockIdx 和 threadIdx 以及与之关联的 CUDA 魔术使其成为并行的。当函数被调用时,它实际上是使用多个线程多次调用的,每个线程计算结果的一部分(请参阅下一节)。
当主机代码设置执行环境时,它必须确定如何将工作分配给处理核心。作为其职责的一部分,主机必须确定如何以逻辑方式排列线程。CUDA 允许开发人员以一维、二维或三维结构排列他们的线程。这有助于开发人员以自然的方式表达设计。
考虑一下示例算法。让我们使用 GPU 用数据填充一个二维矩阵。如果您可以以某种方式为每个线程分配一个二维坐标系统中的“位置”,那将非常方便,因为每个线程可以使用其分配的坐标来决定要计算哪个元素。
CUDA 提供了一种机制,开发人员可以通过该机制指定他们希望如何排列线程。编译器负责其余的工作。此功能通过所谓的线程块网格提供。在本例中,主机将使用二维网格。
您可能想知道,为什么是“线程块网格”而不是“线程网格”?
线程本身并不存在于网格内部,而是排列成线程块。每个线程在其块内被分配一个标识符。每个块又在网格内被分配一个标识符。内置的 blockIdx 和 threadIdx 变量有助于确定当前线程和块标识符。从内核内部,这些标识符可以简单地看作是一个 C 结构,包含线程的 x、y 和 z 坐标。
使用这种机制,您可以让每个线程计算一个全局线程 ID,并在您的并行伪代码中计算 x 和 y 变量。对 (x, y) 决定了必须计算矩阵的哪个元素。因为每个线程的 (x, y) 值都不同,所以理论上,如果您有足够的线程,矩阵的每个点都可以同时计算。
现在,让我们应用第二个操作,它检测计算出的向量场上的局部最小值。局部最小值是所有向量都收敛的地方(图 6)。标记出局部最小值将防止移动机器人在其中一个局部最小值处停止,而没有任何向量引导它出来。

图 6. 移动机器人应避免的三个局部最小值
在流处理模型下,运算符可以串联:第二个运算符消耗第一个运算符的输出,很像操作系统的管道运算符。在示例 CUDA 实现中,您将消耗存储在 GPU 内存中的向量场矩阵。顺序局部最小值检测伪代码
In Parameters: calculated vector field, a decimal threshold
Out Parameters: a boolean matrix called "minima"
detect_local_minima_cpu(in field, in threshold, out minima):
for (y=0 to h):
for (x=0 to w):
minima[y][x] =
(norm(field[y][x]) < threshold)? true : false
return
顺序算法将向量场作为输入,并用值“true”或“false”填充相同尺寸的布尔矩阵,具体取决于长度是否低于给定的阈值。相反,“minima”矩阵在位置 (x, y) 指示位于 (x, y) 的向量的范数是否小于给定的阈值。并行局部最小值检测
In Parameters: the calculated vector field, a decimal threshold
Out Parameters: a boolean matrix called "minima"
detect_local_minima_gpu(in field, in threshold, out minima):
x = blockIdx.x * BLOCK_SIZE + threadIdx.x
y = blockIdx.y * BLOCK_SIZE + threadIdx.y
minima[y][x] = (norm(field[y][x]) < threshold) ? true : false
输出是一个布尔值字段,指示给定点是否是局部最小值。
至此,我已经实现了四个算法。当然,您可以从我们的网站免费下载所有源代码并亲自尝试。
那么,CUDA 算法与它的 CPU 等效算法相比如何呢?接下来,我将并行版本与其顺序版本进行比较,以找出答案。用于基准测试实现的硬件包括
Intel Core 2 Duo E6320,运行频率为 1.6GHz,配备 4GB 内存。
NVIDIA GeForce 8600GT GPU。
Ubuntu Linux 8.10。
CUDA 版本 2.2。
我用一个 C++ 程序实现了所有四个算法,该程序可以动态地在算法的 CPU 版本和 CUDA 版本之间切换。这不仅使基准测试过程更容易,而且也是开发程序的良好技术,这些程序可以在不支持 CUDA 的计算机上回退到 CPU。
每个基准测试都使用不同的向量场配置,增加了场的大小以及排斥子的数量。吸引子的数量始终设置为仅一个。向量场的大小为:16x16、32x32、64x64、128x128 和 256x256。排斥子随机分布在场上,比例为每 32 个向量场点一个排斥子。因此,排斥子的数量为 8、32、128、512、2048 和 8192。
图 7 显示了基准测试的结果。我使用符号“WxH/R”,其中 WxH 表示向量场的尺寸,R 表示存在的排斥子数量。执行时间以毫秒为单位,采用对数刻度(因此,图表大小的微小差异实际上比视觉上看起来要快得多)。
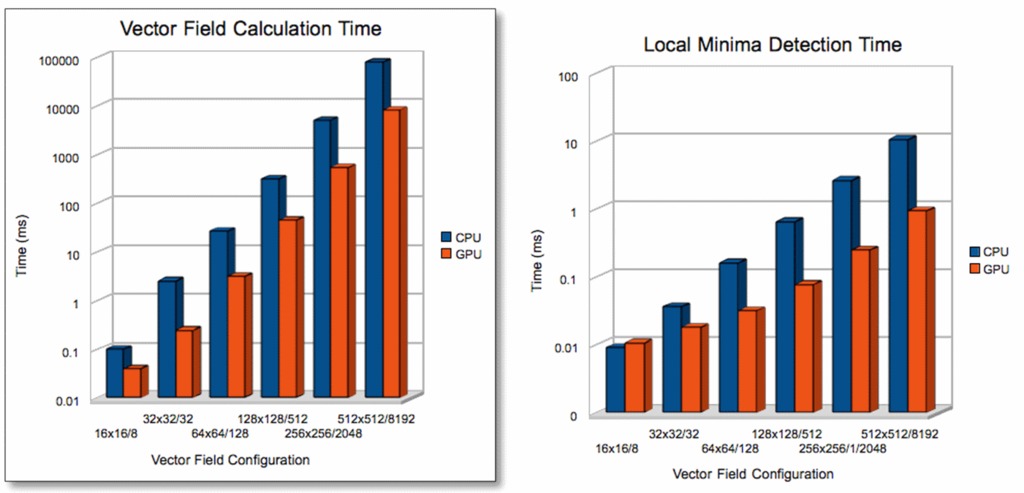
图 7. 计算时间
GPU 快多少?加速比是通过将顺序算法的执行时间除以并行算法的执行时间来计算的(图 8)。
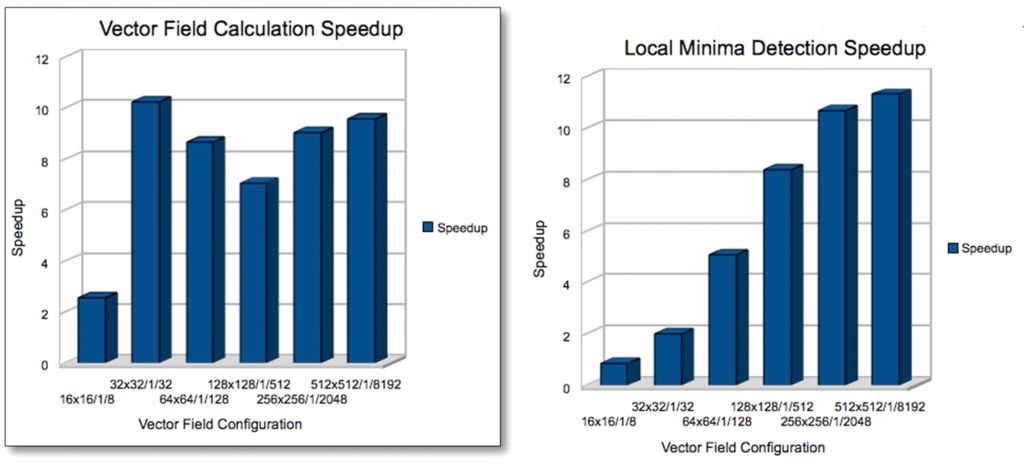
图 8. 加速比
在小向量场的情况下,计算时间最接近。然而,即使在这种情况下,仅通过切换到向量场计算的 CUDA 实现,我们也可以获得 2.5 倍的加速。局部最小值检测仅在处理比小型数据集更计算密集型且稍大的数据集时才变得值得并行化。
平均而言,我们的算法的加速比约为八倍。用外行的话来说,这意味着如果您的计算需要一个工作日才能完成,那么只需切换到 CUDA,您就可以在一个小时内获得结果。
这为需要用户多次运行计算并在每次更正参数的计算提供了显着的好处。这种迭代过程在金融模型中很常见。
如果您的算法可以并行化,那么使用 CUDA 将显着加快您的计算速度,使您能够充分利用您的硬件。
主要挑战在于决定如何将您的问题划分为适合并行执行的块。与并行编程中的许多其他方面一样,这正是经验和——为什么不呢——想象力发挥作用的地方。
其他技术为进一步改进提供了空间。特别是,每个计算节点的片上共享内存允许进一步加速计算过程。
资源
硬件加速计算:gpgpu.org
源代码和视频:www.coroware.com/streamprocessing
CUDA 入门:www.nvidia.com/cuda
基于 ATI 的 Stream SDK:developer.ati.com/gpu/atistreamsdk
OpenCL 官方网站:www.khronos.org/opencl
Alejandro Segovia 是 CoroWare 的并行编程顾问。他也是 RealityFrontier 的贡献合伙人。他从事 3D 图形开发和 GPU 加速工作。Alejandro 最近是特拉华大学的访问科学家,他在那里从学术角度研究了 CUDA。他的研究结果于 2009 年在 IEEE IPCCC 会议上发表。
