
大型强子对撞机
大型强子对撞机 (LHC) 实验的核心是什么? 开源软件是为人类有史以来最复杂的科学事业提供动力的要素之一,这应该不会让您感到惊讶。 我希望让您了解科学计算如何在 LHC 实验之一中拥抱开源软件和开源理念。
位于瑞士日内瓦附近的 LHC 几乎位于地下 100 米处,可提供有史以来能量最高的亚原子粒子束。 LHC 的目标是让物理学家能够了解宇宙在大爆炸之后的状态。 然而,当物理学家计算出要穿过那扇窗户所需的计算能力水平时,他们清楚地意识到,仅靠能够容纳在一个屋檐下的计算机是不可能实现的。
即使有摩尔定律的保证,实验也显然必须包括网格技术并分散计算。 分散化计划的一部分包括采用分层计算模型,该模型在全球范围内创建大型数据存储和分析中心。
紧凑型μ子螺线管 (CMS) 实验是位于 LHC 的大型对撞机实验之一。 CMS 的主要计算资源位于 LHC 实验室,称为 Tier-0。 Tier-0 的功能是记录来自探测器的数据,对其进行存档并将其传输到全球的 Tier-1 设施。 理想情况下,每个参与 CMS 的国家都有一个 Tier-1 设施。 在美国,Tier-1 位于伊利诺伊州巴达维亚的费米国家加速器实验室 (FNAL)。 每个 Tier-1 设施都负责额外的存档存储,以及物理重建和分析,并将数据传输到 Tier-2 中心。 Tier-2 中心是 CMS 资助的物理学家分析资源。 个人和大学可以自由构建 Tier-3 站点,这些站点不是通过 CMS 支付的。
目前,美国有八个 CMS Tier-2 中心。 它们在大学的位置使 CMS 能够利用这些机构的计算专业知识,并为学生的教育机会做出贡献。 我在内布拉斯加大学林肯分校的 CMS Tier-2 设施担任系统管理员。
按照大多数标准,Tier-2 中心都是大型计算资源。 目前,内布拉斯加大学 Tier-2 的功能包括大约 300 台服务器,其中 1,500 个 CPU 内核专用于计算,以及超过 800 TB 的磁盘存储空间。 我们与 FNAL 的 Tier-1 的网络连接速度为每秒 10 吉比特。
LHC? CMS? ATLAS? 我糊涂了。
很容易迷失在高能物理世界的实体中。 大型强子对撞机 (LHC) 是加速器,它提供高能粒子束,这些粒子束是质子。 它位于 CERN(欧洲核子研究中心)。 CERN 是实验室,LHC 是机器。 紧凑型μ子螺线管 (CMS) 是一种大型粒子探测器,旨在记录质子束碰撞产生的粒子(μ子是一种类似于电子的基本粒子)。 CMS 只是 CERN 的实验之一。 CMS 也用于指代分析来自 CMS 探测器记录的数据的大型科学家合作组织。 大多数参与 CMS 的美国物理学家都在一个名为 USCMS 的组织中。 LHC 的其他实验包括 ATLAS、ALICE、LHCb、TOTEM 和 LHCf。 这些实验使用自己的分析软件,但与 CMS 共享一些网格基础设施。
CMS 计算在技术上更困难的障碍之一是数据管理。 数据移动是使用名为 PhEDEx(物理实验数据导出)的自定义框架来管理的。 PhEDEx 实际上并不移动数据,而是充当启动站点之间传输的机制。 在每个站点运行的 PhEDEx 代理与位于 CERN 的数据库服务器连接,以确定该站点需要哪些数据。 X509 代理证书用于验证源站点和目标站点的 gridftp 端口之间的传输。 内布拉斯加大学的 Tier-2 有 12 个 gridftp 端口,持续传输速率高达每秒 800 兆字节。
应该注意的是,“数据”一词对于物理学家来说可能意味着几种不同的事物。 它可以指探测器的数字化读数、蒙特卡罗模拟输出,或者存储在硬盘和磁带上的位和字节。
内布拉斯加大学 Tier-2 站点提出的网络需求在计算机网络工程领域产生了有趣的研究。 内布拉斯加大学是第一所演示通过动态分配的 IP 路径进行大数据移动的大学。 当内布拉斯加大学的 Tier-2 从 FNAL 的 Tier-1 中提取大量数据时,会自动构建单独的 IP 路径,以防止流量对大学的一般互联网使用产生不利影响。
由于数据传输和管理对于 CMS 的成功至关重要,因此底层系统的开发已经持续多年。 蒙特卡罗样本和真实物理数据的传输量在全球范围内已超过 54 PB。 仅内布拉斯加大学在过去的一个日历年中就下载了 900 TB。 所有这些数据移动都是通过运行开源软件的商用服务器完成的。
一旦决定分散分析资源,就需要回答一个关键问题。 欧洲的物理学家如何在内布拉斯加大学使用存储的数据运行作业? 2004 年,CMS 的计算模型最终确定并采用了新兴的网格技术。 当时,技术实施方案保持灵活性,以便站点可以采用可能出现的任何网格中间件。 欧洲的分析站点采用了世界 LHC 计算网格 (WLCG) 软件堆栈来促进分析。 美国的站点选择开放科学网格 (OSG) 来提供远程部署作业的软件。 这两种解决方案是可互操作的。
OSG(www.opensciencegrid.org) 的使命是帮助共享计算资源。 虚拟组织 (VO) 可以通过提供计算资源和利用其他 VO 提供的额外计算资源来参与 OSG。 在过去的一年中,OSG 为参与的 VO 提供了 2.8 亿小时的计算时间。 图 1 显示了过去一年中按 VO 划分的这些小时数的细分。(VO 首字母缩略词的含义的互联网搜索留给读者自己练习。)其中 4000 万小时提供给了与粒子物理学无关的 VO。 参与 OSG 使内布拉斯加大学能够与其他科学家共享任何空闲的 CPU 周期。 此外,所有美国 Tier-2 站点的 CMS 运营模式是,我们平均计算能力的 20% 用于非 CMS VO。 这为非 CMS VO 加入 OSG 提供了激励。 非 CMS VO 的参与增加了对 OSG 软件的支持和开发,这使 CMS 可以从其他用户所做的改进中受益。 OSG 的模型应作为类似协作努力的榜样。
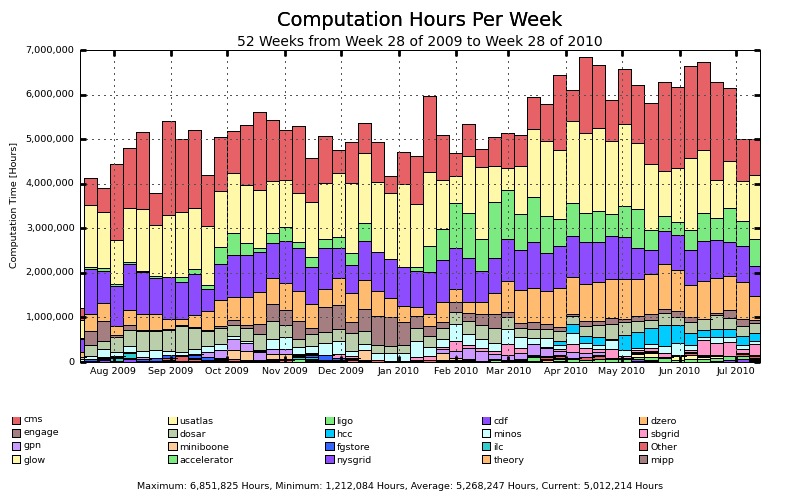
图 1. 过去一年中用户 VO 每周开放科学网格使用情况的统计。
OSG 为开源网格中间件提供集中式打包和支持。 OSG 还使管理员可以轻松安装证书颁发机构凭据。 证书和身份验证管理是 OSG 最有用的工具集之一。 此外,OSG 监控站点并管理票务系统,以提醒管理员注意问题。 OSG 提供站点利用率的完整核算,以便资助机构和高层管理人员拥有他们需要的工具来争取进一步的支出。 有关主要设施向 OSG 提供的 CPU 小时数,请参见图 2。
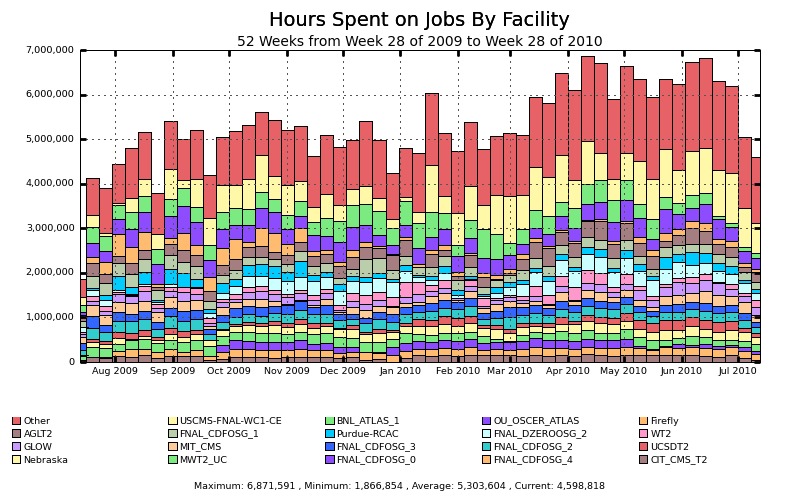
图 2. 计算设施每周向开放科学网格提供的 CPU 小时数的视图。 “Nebraska”和“Firefly”都是内布拉斯加大学提供的资源。
简而言之,SETI@home 对人们的桌面所做的事情,OSG 对使用大学计算中心的研究也做了同样的事情。
CMS 实验每天将生成超过 1 TB 的记录数据。 每个 Tier-2 站点预计将在本地存储数百 TB 的数据以供分析。 如何有效地存储数百 TB 的数据并允许来自网格提交作业的分析?
当我们开始构建内布拉斯加大学的 CMS Tier-2 时,答案是在德国高能物理 (HEP) 实验 DESY 编写的名为 dCache 的软件包。 dCache 或磁盘缓存是一个分布式文件系统,由物理学家创建,充当大型磁带存储的前端。 这种模型非常符合高能物理学家的既定实践。 HEP 社区已经使用磁带存储数据数十年了。 我们是利用磁带的专家。 dCache 旨在将数据从慢速磁带暂存到快速磁盘,而用户无需了解任何有关磁带访问的信息。 直到最近,dCache 都使用名为 PNFS(完全正常文件系统,不要与并行 NFS 混淆)的软件以类似于 POSIX 的方式但又不是完全符合 POSIX 标准的方式来呈现 dCache 文件系统。 存储在 dCache 中的数据必须使用 dCache 特定协议或通过网格接口访问。 由于文件访问和控制并非真正符合 POSIX 标准,因此对于非 dCache 专家来说,系统管理可能会有问题。
dCache 存储是基于文件的。 存储在磁盘上的所有文件都对应于 PNFS 命名空间中的文件。 弹性是通过副本管理器来管理的,副本管理器尝试将单个文件存储在多个存储池上。 虽然对于非专家来说,使用 dCache 可以轻松管理和手动修复基于文件的分布式存储系统,但该架构可能会导致存储服务器上的负载高度不平衡。 如果大量作业请求同一文件,则单个存储服务器很容易变得过载,而其余服务器则相对空闲。
我们对 dCache 的内部研究发现,当使用大型磁盘库而不是在集群工作节点中使用硬盘驱动器时,我们获得了更好的整体体验。 这给我们在预算内满足存储需求带来了问题。 购买硬盘驱动器并将它们部署在工作节点中比购买大型磁盘库便宜得多。 CMS 计算模型不允许为 Tier-2 站点的大型磁带存储提供资金。 数据存档维护在 Tier-0 和 Tier-1 级别。 这意味着 dCache 的真正优势在 Tier-2 站点中没有得到利用。
可扩展性和预算问题促使内布拉斯加大学在开源世界中寻找不同的解决方案。 我们找到了 Hadoop 和 HDFS。
Hadoop (hadoop.apache.org) 是一个用于分布式计算的软件框架。 它是 Apache 的顶级项目,并受到许多商业利益的积极支持。 我们对 Hadoop 中的计算软件包不感兴趣,但我们对 HDFS 非常感兴趣,HDFS 是 Hadoop 提供的分布式文件系统。 HDFS 使我们能够轻松利用集群工作节点中可用的硬盘驱动器插槽。 HDFS 的初始安装除了硬盘驱动器本身之外,没有花费我们任何费用。 HDFS 也被证明易于管理和维护。
为了使 HDFS 适合我们的需求,我们唯一需要的开发是扩展 gridftp 软件以使其能够识别 HDFS。 分析作业能够通过 FUSE 挂载访问 HDFS 中的数据。 分析软件的持续开发正在使其能够识别 HDFS,并进一步消除不必要的开销。
HDFS 是一个基于块的分布式文件系统。 这意味着存储在 HDFS 中的任何文件都会被分解为可配置大小的数据块。 然后,这些单独的块可以存储在任何 HDFS 存储节点上。 当文件分布在所有工作节点上时,拥有一个“热”数据服务器为整个集群提供数据的可能性开始接近于零。 HDFS 还会识别当前节点所需的数据是否位于该节点上,并且不会启动到自身的网络传输。
HDFS 中的块复制机制非常成熟。 HDFS 为我们提供了出色的数据弹性。 块复制级别可以在文件系统级别轻松配置,但也可以在用户级别指定。 这使我们能够以智能的方式调整复制级别,以确保在内布拉斯加大学创建的模拟数据比我们可以轻松地从其他站点重新传输的数据享有更高的容错能力。 这最大限度地提高了我们可用的存储空间,同时保持了高可用性。
HDFS 非常适合我们的 Tier-2。
HadoopViz
内布拉斯加大学林肯分校的学生 Derek Weitzel 完成了一个学生项目,该项目展示了我们 HDFS 系统中数据的实时传输。 这种可视化称为 HadoopViz,它将 HDFS 系统中的所有数据包传输显示为从一台服务器弧形移动到另一台服务器的雨滴。 下图显示了一个静止镜头。

从左到右的屏幕:Condor 作业视图; PhEDEx 传输质量; Hadoop 状态页; MyOSG 站点状态; CMS 仪表板作业状态; 内布拉斯加大学集群的 Nagios 监控; 11 月 7 日光束刮削事件的 CMS 事件显示; 美国 CMS Tier-2 站点的 OSG 资源验证监控 HadoopViz 数据包移动可视化
一旦数据存储在 Tier-2 中,物理学家就需要能够分析数据以进行发现。 此任务的平台是 Linux。 为了标准化,大多数开发都在基于 Red Hat Enterprise 的发行版上进行。 CERN 和 FNAL 都有自己的 Linux 发行版,但将改进和自定义添加到 Scientific Linux 发行版中。 内布拉斯加大学的 Tier-2 运行 CentOS 作为我们站点的主要平台。
由于数据文件构建为大约 2GB 大小,并且数据集目前徘徊在低 TB 范围内,因此在典型的台式机上进行完整数据集分析是有问题的。 典型的物理分析将从编码和调试开始,在单个工作站或小型 Tier-3 集群上进行。 一旦编码和调试阶段完成,分析将在整个数据集上运行,最有可能在 Tier-2 站点上运行。 将分析提交到网格计算站点并不容易,并且该过程已通过 CMS 开发的名为 CRAB(CMS 远程分析构建器)的软件实现自动化。
为了创建用户的作业,CRAB 查询 CERN 的 CMS 数据库,其中包含数据在全球范围内的存储位置。 CRAB 构建网格提交脚本。 然后,用户可以将整个分析提交到适当的网格资源。 CRAB 允许用户查询其作业的进度,并请求将输出下载到其个人工作站。
CRAB 可以将输出定向到 Tier-2 存储本身。 每个 CMS 用户在每个 Tier-2 站点上被允许 1 TB 的空间,用于非存档存储每个用户的分析输出。 监管科学家使用的存储空间是留给 Tier-2 站点的任务。 HDFS 的配额功能为内布拉斯加大学 Tier-2 管理员提供了一个易于更新的工具,可以自动限制分析空间的使用。
图 3 显示了通过 CMS 看到的模拟事件,图 4 显示了实际记录的事件。

图 3. 物理学家如何看待 CMS——这是单个模拟事件的事件显示。

图 4. 来自 CMS 的实际记录事件——此事件显示辐射和带电粒子从光束与光束管道中的材料碰撞而溢出到探测器中。
Carl Lundstedt 于 2001 年在内布拉斯加大学林肯分校 (UNL) 获得高能粒子物理学博士学位。在教授了五年物理学入门课程后,他现在是位于 UNL 荷兰计算中心的 CMS Tier-2 计算设施的管理员之一。
