
使用 Linux 的并行计算
并行计算涉及计算系统的设计,该系统使用多个处理器来解决单个问题。例如,如果要将两个各有十个元素的数组相加,可以使用两个处理器来计算结果。一个处理器计算前五个元素的和,第二个处理器计算后五个元素的和。计算完成后,必须将一个处理器的结果传达给另一个处理器。在开始计算之前,两个处理器都同意处理独立的子问题。每个处理器处理一个子问题,并在解决方案可用时进行通信。理论上,双处理器计算机应该以单处理器计算机两倍的速度添加数字数组。在实践中,存在开销,并且对于更大的处理器配置,使用更多处理器的优势会降低。
以 PC 的成本获得 Unix 工作站一直是使用 Linux 的好处之一。通过将多台 Linux PC 连接在一起,这个想法更进一步。目前正在进行多个研究项目,以使用高性能网络连接 PC。高速网络是一个热门话题,并且有许多项目使用 Linux 开发低延迟和高带宽的并行计算机。(一个 URL 是 http://yara.ecn.purdue.edu/~pplinux。)
目前,SMP Linux 下对共享内存编程的高级支持不多。用于跨处理器共享内存的基本 Linux 机制是可用的。它们包括 System V 进程间通信系统调用和线程库。但是,并行 C 或 C++ 编译器还需要一段时间才能在 Linux 上可用。并行编程仍然可以在 SMP Linux 机器上或使用消息传递的 Linux PC 集群上完成。
并行计算的优势在于它可以更快地获得问题的解决方案。科学应用程序已经使用并行计算作为解决问题的方法。并行计算机通常用于计算密集型应用程序,例如气候建模、有限元分析和数字信号处理。处理大量复杂数据的新型商业应用程序正在推动更快计算机的开发。这些应用程序包括视频会议、数据挖掘和高级图形。并行计算、多媒体技术和高性能网络的集成导致了 视频服务器 的发展。视频服务器必须能够快速编码和解码兆字节的数据,同时处理数百个请求。虽然商业并行应用程序越来越受欢迎,但科学应用程序仍将是并行计算机的重要用户。随着科学和工程应用程序使用大量数据,商业应用程序执行更复杂的操作,这两种应用程序类型正在融合。
并行计算是一个广泛的主题,本文将重点介绍如何使用 Linux 实现并行应用程序。我们将研究两种并行编程模型:消息传递和共享内存结构。
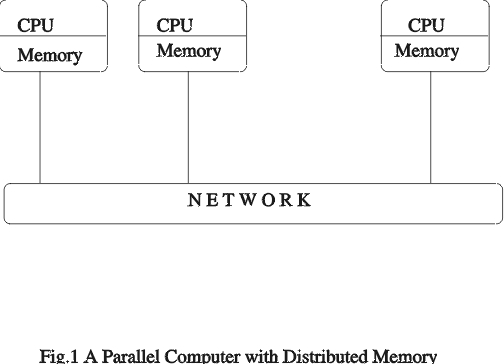
从概念上讲,消息传递背后的思想很简单——并行计算机的多个处理器运行相同或不同的程序,每个程序都有私有数据。数据在需要时在处理器之间交换。消息由 发送 处理器传输到 接收 处理器。一个处理器可以在任何时候是发送处理器或接收处理器。发送处理器可以等待发送后的确认,也可以继续执行。接收处理器检查消息缓冲区以检索消息。如果消息不存在,处理器可以继续执行并在稍后重试,或者等待直到收到消息。在并行计算机中,可以同时发生多个 发送 和 接收。并行计算机内的所有处理器都必须通过网络互连(图 1)。
所有处理器都可以与所有其他处理器交换数据。消息的路由由操作系统处理。消息传递模型可以用于工作站网络或具有分布式内存的紧密耦合的处理器组内。处理器之间的跳数可能因互连网络的类型而异。
处理器之间的消息传递是通过使用通信协议来实现的。根据使用的通信协议,发送例程通常接受目标处理器 ID、消息类型、消息缓冲区的起始地址和要传输的字节数。接收例程可以从任何处理器或特定处理器接收消息。消息可以是任何特定类型。
大多数通信协议都维护在处理器对之间发送消息的顺序。例如,如果处理器 0 发送类型为 a 的消息,然后发送类型为 b 的消息到处理器 1,那么当处理器 1 向处理器 0 发出接收通用消息类型的请求时,将首先接收类型为 a 的消息。但是,在多处理器系统中,如果处理器发出从任何处理器接收的请求,则不能保证从发送处理器接收消息的顺序。消息传输的顺序取决于路由器和网络上的流量。为了保持消息发送的顺序,最安全的方法是使用源处理器编号和消息类型。
消息传递已成功用于实现许多并行应用程序。但是消息传递的一个缺点是需要额外的编程。向大型程序添加消息传递代码需要相当长的时间。必须选择域分解技术。程序的数据必须进行划分,以便处理器之间的重叠最小,所有处理器上的负载平衡,并且每个处理器都可以独立地解决子问题。对于规则的数据结构,域分解非常简单,但对于不规则的网格,划分问题以使负载在所有处理器之间平衡并非易事。
消息传递的另一个缺点是可能发生死锁。很容易通过错误放置对 发送 或 接收 例程的调用来挂起并行计算机。因此,虽然消息传递在概念上很简单,但尚未被科学界或商业界完全采用。
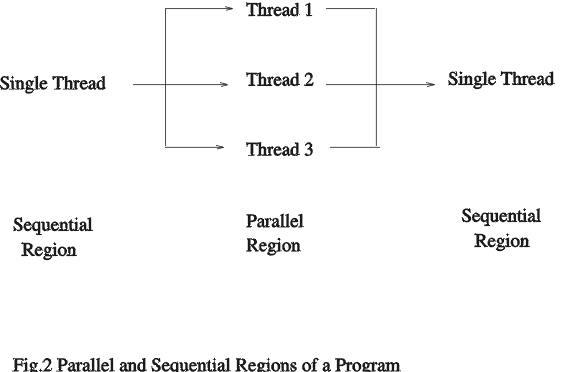
并行编程的另一种方法是使用共享内存并行语言结构。这种方案背后的思想是识别程序的并行区域和顺序区域(图 2)。程序的顺序区域在单个处理器上运行,而并行区域在多个处理器上执行。并行区域由可以并发运行的多个线程组成。
对于某些程序,识别并行区域和顺序区域可能是一项简单的任务,但对于其他程序,可能需要修改顺序程序以创建并行区域。最简单的方法是依靠编译器来确定并行区域。这就是 自动并行化 方法,通常会产生较差的结果。大多数编译器在引入并行性时都很保守,如果存在任何歧义,则不会并行化代码。例如,如果通过索引数组(例如,x(index(i)))在循环中访问数组 x 的元素,则循环将不会并行化,因为编译器无法知道数组 x 的元素是否将在循环中独立访问。
任何程序中耗时的部分通常都花费在执行循环上。为循环创建并行区域是为了加速循环的执行。为了使编译器从循环构建并行区域,必须识别循环的私有和共享数据变量。下面的示例适用于 Silicon Graphics Challenge 机器,但这些概念对于其他共享内存机器(例如 Digital Alpha、IBM PC 或 Cray J90)也是类似的。共享内存结构放置在循环之前和之后。
#pragma parallel
#pragma shared (a,b,c)
#pragma local (i)
#pragma pfor iterate (i=0;100;1)
for (i = 0; i < 100; i++) {
a(i) = b(i) * c(i)
}
#pragma one processor
第一个 pragma 语句之前和最后一个 pragma 语句之后的代码在单个处理器上执行。循环中的代码使用多个线程并行执行。使用的线程数基于环境变量。对于简单的循环,识别共享变量和私有变量很容易,但对于具有函数调用和依赖关系的复杂循环,这可能是一项繁琐的工作。
使用共享内存结构进行编程可能比消息传递更简单。使用共享内存结构的程序的并行版本可以比消息传递版本更快地开发出来。虽然生产力的提高可能很吸引人,但性能的提高取决于编译器的复杂性。用于并行程序的共享内存编译器必须生成用于线程创建、线程同步和访问共享数据的代码。相比之下,消息传递的编译器更简单。它由带有通信库的基本编译器组成。虽然没有人可以预测使用共享内存结构或消息传递会获得更好的性能,但消息传递模型提供了更大的优化空间。可以针对特定应用程序优化数据收集和分发算法。可以基于代码中的通信模式执行域分解。
消息传递的另一个优点是可移植性。使用标准通信协议编写的消息传递程序可以在没有重大更改的情况下从 PC 网络移植到大规模并行超级计算机。消息传递也可以在异构机器网络上使用。
每个共享内存编译器的供应商都为编译器指令选择了不同的语法。因此,使用指令并行化的代码通常仅限于特定的编译器。
并行虚拟机 (PVM) 是目前最流行的用于实现分布式和并行应用程序的通信协议。它最初于 1991 年由橡树岭国家实验室和田纳西大学发布,并在世界各地的计算应用程序中使用。PVM 是一个正在进行的项目,并且是免费分发的。PVM 软件提供了一个框架,用于在异构机器网络上开发并行程序。PVM 处理消息路由、数据转换和任务调度。应用程序被编写为协作任务的集合。每个任务都通过库例程集合访问 PVM 资源。这些例程用于启动任务、终止任务、发送和接收消息以及在任务之间同步。PVM 接口例程库是 PVM 系统的一部分。系统的第二部分是 PVM 守护程序,它在参与应用程序网络的每台机器上运行,并处理任务之间的通信。
PVM 可以使用流或数据报协议(TCP 或 UDP)来传输消息。通常,TCP 用于单台机器内的通信,而 UDP 用于单独机器上的守护进程之间的通信。UDP 是一种无连接协议,不执行错误处理。因此,当 UDP 用于通信时,PVM 对每个数据包使用停止等待方法。数据包一次发送一个,每个数据包都有一个确认。这种方案在具有高延迟的系统上带宽很差。另一种方法是直接在任务之间使用 TCP,绕过守护程序(图 3)。
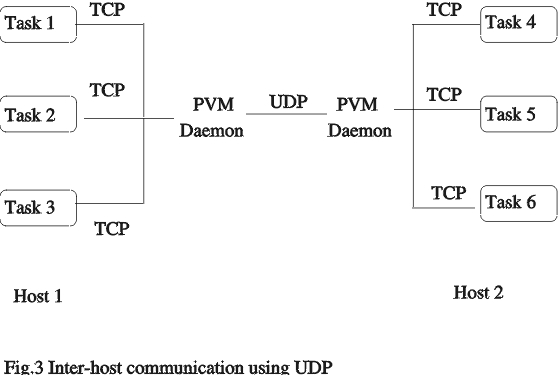
图 3. 使用 UDP 的主机间通信
TCP 是一种可靠的传输协议,不需要在传输数据包后进行错误检查。使用 TCP 的开销高于 UDP。每个连接都需要单独的套接字地址,并且使用额外的系统调用。因此,虽然 TCP 提供了更好的性能,但它不具有可扩展性。
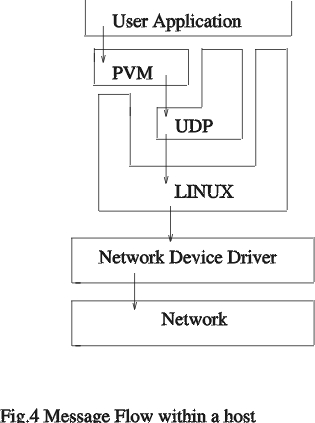
要将消息从主机 1 发送到主机 2,必须完成许多步骤(图 4)。第一步,在主机 1 上初始化消息缓冲区。第二步,使用 PVM 打包例程 打包 消息数据。最后,用消息标签标记消息并将其发送到主机 2。要接收消息,主机 2 发出带有消息标签和主机 ID 的 PVM 调用。可选地,可以使用通配符消息类型或主机 ID。然后,主机 2 必须按照在主机 1 上打包的顺序 解包 消息。
已经开发了使用线程和 ATM(异步传输模式)的实验性 PVM 实现,以获得更高的带宽和更低的延迟。虽然 PVM 的使用很广泛,但消息传递接口 (MPI) 标准正变得越来越流行。
在 Supercomputing '92 会议上,成立了一个委员会(后来称为 MPI 论坛)来制定消息传递标准。在 MPI 开发之前,每个并行计算机供应商都开发了自定义通信协议。各种通信协议使得在并行机器之间移植代码变得乏味。1994 年,发布了 MPI 的第一个版本。使用 MPI 的优点是
它是一个标准,应该使机器之间的移植变得容易。
供应商负责开发 MPI 库的高效实现。
MPI 的多个实现是免费提供的。
使用 PVM 的问题之一是 Digital、Cray 和 Silicon Graphics 等供应商开发了 PVM 的优化版本,这些版本不是免费提供的。自定义版本的 PVM 通常不包括橡树岭分发的 PVM 系统的所有库例程,有时它们还包括用于获得更好性能的非标准例程。尽管存在上述问题,但 PVM 易于使用,开发新的并行应用程序只需很少的努力。将 PVM 应用程序转换为使用 MPI 的应用程序并非难事。
如何并行化程序?第一步是确定代码的哪个部分消耗的时间最多。这可以使用分析程序(例如 prof)来完成。专注于并行化一段代码或一组函数,而不是整个程序。有时,这也可能意味着并行化程序的启动和终止代码以分发和收集数据。其思想是将并行化的范围限制在可管理的任务中,并逐步添加并行性。
使用两个、四个和八个处理器运行以确定可扩展性。随着您使用更多处理器,您可以预期性能的提高会降低。常用的并行性能度量是 加速比。它是使用最佳顺序算法解决问题所花费的时间与使用并行算法解决问题所花费的时间之比。如果您使用四个处理器并获得超过四的加速比,原因通常是更好的缓存性能,而不是更出色的并行算法。当问题规模较小时,您可以预期更高的缓存命中率和相应的更低执行时间。超线性加速比受到怀疑,因为它意味着超过 100% 的效率。
虽然您可能会获得良好的加速比,但并行程序的结果应与顺序算法的结果相似。当使用异构主机时,您可以预期精度会略有差异。结果差异程度将取决于使用的处理器数量和处理器的类型。
最有效的算法是通信开销最小的算法。大多数通信开销发生在主从机之间发送和接收数据时,这是不可避免的。可以使用不同的算法来分发和收集数据。可以采用一种有效的拓扑,以最大限度地减少处理器之间的通信跳数。当处理器之间的跳数很大时,通信开销将增加。如果大量的通信开销是不可避免的,那么计算和通信可以重叠。这可能是可能的,具体取决于问题。
Manu Konchady (manu@geo.gsfc.nasa.gov) 是乔治梅森大学的研究生,并在戈达德太空飞行中心工作。他喜欢放风筝和与他 2 岁的女儿玩耍。


{kind=link}
{kind=link}
{kind=link}