
xldlas—统计程序
Linux 是一个几乎无与伦比的平台,用于使用自由分发的软件。内核源代码是自由的,标准实用程序是自由的,X 窗口系统也是如此。使用自由软件的整个概念非常吸引人,许多用户都想尝试在他们的系统上完全不使用任何商业产品。然而,这种愿望常常因缺少一个应用程序而受挫;桌面出版和演示软件通常被认为是 Linux 武器库中当前的“漏洞”。
当我决定放弃硬盘上的 MS-DOS 分区并完全转向 Linux 时,我也面临着这样一个问题。由于我处理相当多的统计信息,我需要一种直接的方法来汇总数据、绘制数据并在需要时执行回归分析。gnuplot 非常适合绘图,但它只能做这些。Octave 和 MuPad 具有强大的数值功能,但对于简单的统计任务来说,它们又显得过于复杂。由于找不到适合这个领域的程序,我决定自己编写一个。结果就是 xldlas,一个统计程序。按照 Unix 的伟大传统,它的名字是一个伪首字母缩略词,代表“x l谎言,d该死的l谎言,a以及s统计”。1996 年 10 月的首次公开发布收到了用户的非常积极的反馈,其中一位 beta 测试人员(Hans Zoebelein)建议在Linux Journal 上发表一篇文章可能是向更广泛的受众介绍 xldlas 的好方法。LJ 的人同意了,并要求我撰写这篇概述。该程序在 X 窗口系统下运行,并使用 XForms 库构建。您可以在本文末尾找到有关如何下载 xldlas 和相关软件的信息。
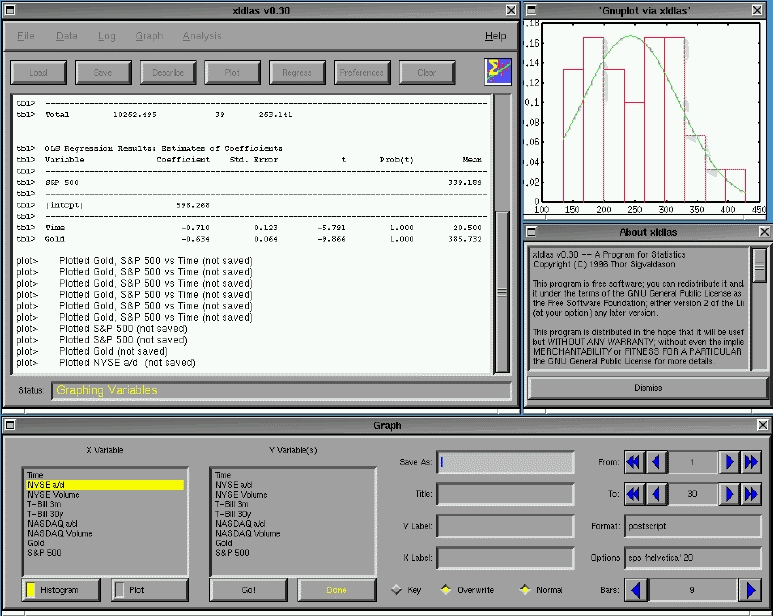
xldlas 背后的理念是通过易于使用的点击界面提供标准统计工具。为了方便这种方法,常用命令被分组到一组菜单中。此外,常用命令可通过按钮访问(见图 1)。
像大多数统计软件包一样,xldlas 将随机变量视为值向量。因此,单个变量名可以指代数十、数百或数千个观测值。* 通过将数据点按变量名分组,通过选择几个变量并单击相关命令,可以轻松执行相对复杂的操作。
*默认情况下,xldlas 限制为 100 个变量,每个变量最多 10,000 个观测值。可以通过更改源文件 xldlas.h 中 MAX_VARS 和 MAX_OBS 的值轻松调整这些约束。
当然,在执行任何类型的统计操作之前,您必须将数据导入 xldlas。由于 ASCII 是 Linux 下交换信息的实际标准,xldlas 允许您使用 Import 命令从文本文件中读取空格分隔的数据。您提供文件名,并告诉 xldlas 数据是列格式还是行格式。导入例程会自动计算出有多少变量和观测值,并读取数据。举一个具体的例子,假设您有一个文件,其中包含单个地点的降雨量、温度和气压的空格分隔数据。导入此文件后,xldlas 将在内存中拥有三个变量,它们将被称为 unknown0、unknown1 和 unknown2。您可以使用 Rename 命令将这些名称更改为您喜欢的任何名称,该命令可以从 Data 菜单访问。除了这种简单的 ASCII 格式外,xldlas 还可以读取和写入其自身专有文件格式的数据集。按照惯例,这些文件的扩展名为 .lda。由于变量名、描述和其他有用的信息都存储在这些文件中,因此如果您计划经常使用 xldlas,通常最好以这种方式保存所有数据。Load、Save 和 Import 命令都可以在 File 菜单中找到。要手动输入数据、擦除变量或执行任何类型的编辑,Data 菜单中分组了一些相关命令。其中,最常用的可能是 Describe 命令,它在主 xldlas 窗口中生成一个表格,显示当前内存中每个变量的名称、观测值数量和描述。除了更改观测值外,Edit 命令还可用于输入变量的描述。
Data 菜单中另一个常用的项目是 Generate 命令。此例程允许您对现有数据执行数学转换。继续上面的天气示例,假设我们要将降雨量变量从毫米转换为厘米。只需点击几下鼠标,我们就可以轻松完成此任务。我们还可以添加一些随机噪声,找到数据的对数等等。它与 Mathematica 相差甚远,但对于简单的操作,Generate 命令快速易用。
一旦加载、编辑和转换了数据,下一步逻辑步骤就是对其执行某种统计工作。要获得单个变量的表格摘要,包括均值、方差、偏度和峰度,可以使用 Summarize 命令。如果您想检查多个变量的线性关系,Correlation 命令将生成 Pearson 系数表。同样,ANOVA 命令允许您通过使用鼠标选择变量名并单击 Go 按钮来执行单向和双向方差分析。
普通最小二乘回归是统计技术的主力,可通过 Regress 命令获得。只需从因变量浏览器中选择一个变量,从自变量浏览器中选择任意数量的变量,然后按 Go。如果您想存储拟合值,则可以在回归窗口中输入新的变量名。回归命令的输出是一组三个表格,它们总结了回归的拟合度,分解了平方偏差和,并列出了系数估计值。相关的 t 统计量及其相关概率会自动包含在内,F 系数和所有估计值联合检验的置信水平也是如此。
xldlas 还提供了两种使用连接主义人工智能技术的实验性数据拟合例程。第一个 GA Fit 使用遗传算法来构建拟合方程,该方程最小化给定因变量的拟合值和实际观测值之间的平方和。第二个 NN Fit 创建一个反向传播神经网络,使用选定的自变量作为输入层,并使用单个因变量作为输出层。在这两种情况下,这些技术拟合的值都可以存储在提供的变量名下。这些例程有时可用于探索通常难以使用标准 OLS 回归检查的数据中的非线性关系。*
*虽然这些 AI 技术不是“标准”统计工具包的一部分,但它们在各种环境中变得越来越普遍,并且非常适合数据挖掘。尽管它们在 xldlas 中的实现相当初级,但如果用户提出要求,可能会进行更复杂的修改。
除了操作数据和执行分析外,xldlas 还允许您绘制变量图形。xldlas 的所有图形输出实际上都由 gnuplot 执行,gnuplot 是所有主要 Linux 发行版中都包含的应用程序。实现了两个绘图命令:Plot 和 Histogram。前者允许您创建折线图和散点图,而后者生成描述变量分布的直方图。两种类型的图形都可以添加标题和标签,并且可以以系统上安装的 gnuplot 版本支持的任何格式保存。此外,您可以设置点和线样式,Histogram 例程还包括一个可选功能,该功能将叠加一个正态分布,该正态分布具有与正在绘制图形的数据相同的均值和方差。
xldlas 还提供了相当强大的日志记录工具。Log 命令允许您将 xldlas 的所有输出回显到 ASCII 文件。更强大的工具是 TeXLog 命令,它允许您使用用户提供的名称创建 PlainTeX 格式的日志文件。所有后续输出(例如回归表)都以 TeX 格式写入此文件。在 xldlas 的默认配置下,所有保存的图形也作为封装的 PostScript 插入包含在内。这使得编写统计论文(例如家庭作业)非常快速高效,因为许多耗时的 TeX 标记都是自动完成的。
最后,所有 xldlas 命令都在 Help 菜单中在线记录。还有许多在线教程,许多 xldlas 用户发现它们是非常有用的入门介绍。
目前正在计划向 xldlas 添加许多功能。使用 Probit 和 Logit 模型的回归分析在待办事项列表中名列前茅。一套统计过滤器也可能很快推出,使其可以轻松地对数据进行去趋势处理、删除异常值等等。HTML 格式的日志文件很快将得到支持。另一项重要任务是扩展源代码中的文档,以便原始作者以外的人更容易对其进行修改。
像几乎所有自由分发的软件一样,xldlas 的开发由用户反馈驱动。如果您希望看到某些功能,请给我发送电子邮件,最好附上您希望看到实现的算法的参考文献。
获取 xldlas 副本的最佳方法是从其主页 www.a42.com/~thor/xldlas 获取。如果您只有 FTP 访问 Internet 的权限,您可以从 ftp://sunsite.unc.edu/ 获取(在 pub/Linux/X11/xapps/math/ 中)。完整源代码和 Linux ELF 可执行文件都包含在发行版中,该发行版名为 xldlas-X.Y-srcbin.tgz,其中 X.Y 是版本号(在撰写本文时为 0.40)。
要运行包含的可执行文件或从源代码编译,您需要在系统上安装 XForms 库。有关 XForms 的更多信息,请访问 XForms 主页 bragg.phys.uwm.edu/xforms。虽然 xldlas 旨在在 Linux 下运行,但它显然可以在几乎所有存在 Xforms 库的 Unix 版本下编译,尽管有时需要稍微修改 Makefile。请务必查看每个发行版中包含的 README 文件,以获取有关编译和运行 xldlas 的最新消息。
gnuplot 可在 sunsite.unc.edu/pub/Linux/apps/math/gplotbin.tgz 获得。它也包含在大多数 Linux 发行版中。
为了获得完整的功能,xldlas 还要求您在机器上安装相当完整的 TeX 包。NTeX 和 teTeX 在 Linux 下常用,可在 http://sunsite.unc.edu/pub/Linux/apps/tex/ 获得。
Thor Sigvaldason 已经完成了经济建模中连接主义 AI 技术应用的博士学位的大部分工作。在本文发表时,他要么是圣塔菲研究所的访问博士前研究员,要么是在纽约市工作。您可以通过电子邮件 thor@netcom.ca 与他联系。

{kind=link}