
Linux 中的“虚拟文件系统”
在任何类 Unix 系统中,主要的数据项是“文件”,并且唯一的路径名标识运行系统中的每个文件。每个文件看起来都像任何其他文件一样被访问和修改:相同的系统调用和相同的用户命令适用于每个文件。这独立于保存信息的物理介质和信息在介质上的布局方式。通过将数据传输分派到不同的设备驱动程序,可以实现从信息物理存储的抽象。通过 VFS 实现,可以在 Linux 中获得信息布局的抽象。
Linux 以与 Unix 相同的方式看待其文件系统——采用超级块、inode、目录和文件的概念。随时可访问的文件树取决于不同部分的组装方式,每个部分都是硬盘驱动器或其他物理存储设备的“挂载”到系统的分区。
虽然假定读者非常熟悉挂载文件系统的概念,但我将详细介绍超级块、inode、目录和文件的概念。
超级块的名称源于其传统,即磁盘或分区的第一个数据块用于保存关于分区本身的元信息。超级块现在已从数据块的概念中分离出来,但它仍然包含关于每个已挂载文件系统的信息。Linux 中的实际数据结构称为 struct super_block,它保存各种内务处理信息,如挂载标志、挂载时间和设备块大小。2.0 内核保留了此类结构的静态数组,以处理最多 64 个已挂载的文件系统。
每个文件都关联一个 inode。这种“索引节点”保存关于命名文件的所有信息,除了其名称和实际数据。文件的所有者、组、权限和访问时间都存储在其 inode 中,以及它保存的数据大小、链接数和其他信息。将文件信息从文件名和数据中分离出来的想法,使得硬链接的实现成为可能——并且可以使用目录的“点”和“点点”表示法,而无需对其进行特殊处理。inode 在内核中由 struct inode 描述。
目录是一个将 inode 与文件名关联的文件。内核没有特殊的数据结构来表示目录,在大多数情况下,目录被视为普通文件。特定于每种文件系统类型的函数用于读取和修改目录的内容,而与其实际数据布局无关。
文件本身与 inode 相关联。通常文件是数据区域,但它们也可以是目录、设备、fifo(先进先出)或套接字。“打开的文件”在 Linux 内核中由 struct file 项描述;该结构保存指向表示文件的 inode 的指针。file 结构由诸如 open、pipe 和 socket 等系统调用创建,并由父子进程在 fork 之间共享。
虽然前面的列表描述了信息的理论组织,但操作系统必须能够处理磁盘上布局信息的不同方式。虽然理论上可以寻找磁盘上信息的最佳布局并将其用于每个磁盘分区,但大多数计算机用户需要访问他们所有的硬盘驱动器而无需重新格式化,以跨网络挂载 NFS 卷,有时甚至访问那些有趣 的 CD-ROM 和软盘,它们的文件名不能超过 8+3 个字符。
以透明方式处理不同数据格式的问题已通过将超级块、inode 和文件变成“对象”来解决;对象声明一组必须用于处理它的操作。内核不会陷入大型 switch 语句中,以便能够访问数据的不同物理布局,并且可以在运行时添加和删除新的文件系统类型。
因此,整个 VFS 思想是围绕对对象进行操作的操作集实现的。每个对象都包含一个声明其自身操作的结构,并且大多数操作都接收指向“自身”对象的指针作为第一个参数,从而允许修改对象本身。
在实践中,超级块结构包含一个字段 struct super_operations *s_op,inode 包含 struct inode_operations *i_op,文件包含 struct file_operations *f_op。
Linux 内核执行的所有数据处理和缓冲都独立于存储数据的实际格式。与存储介质的每次通信都通过 operations 结构之一进行。然后,文件系统类型是负责将操作映射到实际存储机制的软件模块——无论是块设备、网络连接 (NFS) 还是几乎任何其他存储和检索数据的方式。这些模块可以链接到正在启动的内核,也可以编译为可加载模块。
当前 Linux 的实现允许对所有文件系统类型使用可加载模块,但 root 文件系统除外(必须先挂载 root 文件系统,然后才能从中加载模块)。实际上,initrd 机制允许在挂载 root 文件系统之前加载模块,但此技术通常仅在安装软盘上使用。
在本文中,我使用短语“文件系统模块”来指代可加载模块或链接到内核的文件系统解码器。
总而言之,这就是任何给定文件系统类型的所有文件处理方式,如图 1 所示
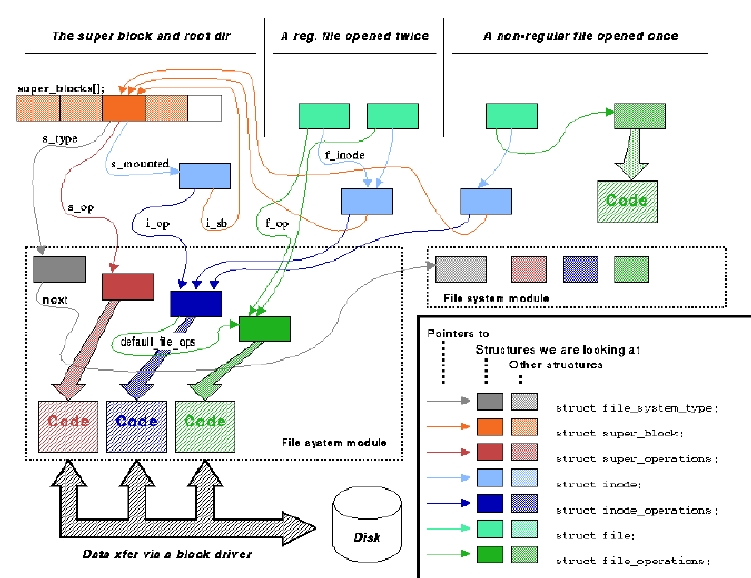
struct file_system_type 是一个仅声明其自身名称和 read_super 函数的结构。在 mount 时,该函数被传递关于正在挂载的存储介质的信息,并被要求填充超级块结构,以及将文件系统根目录的 inode 加载为 sb->s_mounted(其中 sb 是刚刚填充的超级块)。文件系统类型使用附加字段 requires_dev 来声明它是否将访问块设备:例如,NFS 和 proc 类型不需要设备,而 ext2 和 iso9660 需要。填充超级块后,不再使用 struct file_system_type;只有刚刚填充的超级块才会保存指向它的指针,以便能够将状态信息返回给用户(/proc/mounts 是此类信息的一个示例)。该结构如清单 1 所示。
内核使用 super_operations 结构来读取和写入 inode,将超级块信息写回磁盘并收集统计信息(以处理 statfs 和 fstatfs 系统调用)。当文件系统最终卸载时,会调用 put_super 操作——在标准内核措辞中,“get”表示“分配和填充”,“read”表示“填充”,“put”表示“释放”。每个文件系统类型声明的 super_operations 如清单 2 所示。
创建 inode 的内存副本后,内核将使用其自身的操作对其进行操作。struct inode_operations 是文件系统模块声明的第二组操作,并在下面列出;它们主要处理目录树。目录处理操作是 inode 操作的一部分,因为 dir_operations 结构的实现将在文件系统访问中引入额外的条件。相反,仅对目录有意义的 inode 操作将执行自己的错误检查。inode 操作的第一个字段定义了常规文件的文件操作。如果 inode 是 fifo、套接字或设备特定的文件操作,则将使用它。Inode 操作如清单 3 所示;请注意,rename 的定义在 2.0.1 版本中已更改。
最后,file_operations 指定如何处理实际文件中的数据:这些操作实现了 read、write、lseek 和其他数据处理系统调用的低级细节。由于相同的 file_operations 结构用于对设备执行操作,因此它还包括一些仅对字符或块设备有意义的字段。有趣的是,此处显示的结构是在 2.0 内核中声明的结构,而 2.1 更改了 read、write 和 lseek 的原型,以允许更广泛的文件偏移量。文件操作(截至 2.0)如清单 4 所示。
上面描述的访问文件系统数据的机制与数据的物理布局分离,并且旨在考虑所有与文件系统相关的 Unix 语义。
不幸的是,并非所有文件系统类型都支持刚刚描述的所有功能——特别是,即使内核通过其 unsigned long inode 号标识每个文件,也并非每种类型都具有“inode”的概念。如果文件系统类型访问的物理数据没有物理 inode,则实现 readdir 和 read_inode 的代码必须为存储介质中的每个文件发明一个 inode 号。
选择 inode 号的典型技术是使用文件在文件系统数据区域内的控制块的偏移量,假设文件由可以称为“控制块”的东西标识。例如,iso9660 类型使用此技术为设备中的每个文件创建 inode 号。
另一方面,/proc 文件系统没有从中提取数据的物理设备,因此,对于始终存在的文件(如 /proc/interrupts),它使用硬编码的数字,对于其他文件,它使用动态分配的 inode 号。inode 号存储在与每个动态文件关联的数据结构中。
实现文件系统类型时面临的另一个典型问题是处理实际存储能力的限制。例如,当用户尝试将文件重命名为名称长度超过特定文件系统允许的最大长度时,或者当她尝试修改文件系统中没有访问时间概念的文件 的访问时间时,该如何反应。
在这些情况下,标准是返回 -ENOPERM,这意味着“操作不允许”。大多数 VFS 函数,如所有系统调用和许多其他内核函数,在成功时返回零或正数,在错误时返回负数。内核函数返回的错误代码始终是 <asm/errno.h> 中定义的整数值之一。
我现在想展示一些代码来玩 VFS,但很难想象一个足够小的文件系统类型来适合这篇文章。编写新的文件系统类型当然是一项有趣的任务,但完整的实现包括 39 个“操作”函数。
幸运的是,Linux 内核中定义的 /proc 文件系统允许模块在不注册全新文件系统类型的情况下使用 VFS 内部结构。/proc 中的每个文件都可以定义自己的 inode 操作和文件操作,因此,能够利用 VFS 的所有功能。创建 /proc 文件的方法非常简单,可以在此处介绍,尽管不会太详细。“动态 /proc 文件”之所以如此命名,是因为它们的 inode 号是在文件创建时动态分配的(而不是从 inode 表中提取或由块号生成)。
在本节中,我们将构建一个名为 burp 的模块,代表“Beautiful and Understandable Resource for Playing”(用于游戏的漂亮且易于理解的资源)。不会显示模块的所有内容,因为每个动态文件的内部结构与 VFS 无关。
用于构建 /proc 文件树的主要结构是 struct proc_dir_entry。这样的结构与 /proc 中的每个节点相关联,它用于跟踪文件树。文件系统的默认 readdir 和 lookup inode 操作访问 struct proc_dir_entry 树,以将信息返回给用户进程。
burp 模块一旦配备了所需的结构,将创建三个文件:/proc/root 是与当前 root 分区关联的块设备,/proc/insmod 是一个用于加载/卸载模块的接口,而无需成为 root 用户,proc/jiffies 读取 jiffy 计数器的当前值(即,自系统启动以来的时钟滴答数)。这三个文件没有实际价值,仅用于展示如何使用 inode 和文件操作。正如您所见,burp 实际上是一个“Boring Utility Relying on Proc”(依赖 Proc 的无聊实用程序)。为了避免使该实用程序过于无聊,我不会详细介绍模块加载和卸载,因为它们已在之前的 Kernel Korner 文章中描述过,这些文章现在可以在 Web 上访问。整个 burp.c 文件也可以从 SSC 的 ftp 站点获得。
/proc 文件的创建和销毁是通过调用以下函数执行的
proc_register_dynamic(struct proc_dir_entry \
*where, struct proc_dir_entry *self);
proc_unregister(struct proc_dir_entry *where, \
int inode);
在这两个函数中,where 是新文件所属的目录,我们将使用 &proc_root 来使用文件系统的根目录。另一方面,self 结构在 burp.c 内部为三个文件中的每一个声明。该结构的定义在清单 5 中报告以供您参考;稍后,在讨论它们在游戏中的作用之后,我将展示该结构的三个 burp 化身。
因此,burp 的“同步”部分简化为 init_module() 中的三行和 cleanup_module() 中的三行。其他一切都由 VFS 接口分派,并且是“事件驱动的”,因为访问文件的进程可以被视为事件(是的,这种看待事物的方式 是 非正统的,您永远不应该对专业人士使用它)。
ini_module() 中的三行看起来像
proc_register_dynamic(&proc_root, \
&burp_proc_root);
而 cleanup_module() 中的行看起来像
proc_unregister(&proc_root, \
burp_proc_root.low_ino);
low_ino 字段是正在注销的文件的 inode 号,并且已在加载时动态分配。但是这三个文件将如何响应用户访问?让我们分别查看它们中的每一个。
/proc/root 旨在成为块设备。因此,其“mode”应设置 S_IFBLK 位,其 inode 操作应为块设备的操作,并且其设备号应与当前挂载的 root 设备相同。由于与 inode 关联的设备号不是 proc_dir_entry 结构的一部分,因此必须使用 fill_inode 字段。root 设备的 inode 号将从已挂载文件系统的表中提取。
/proc/insmod 是一个可写文件。它需要自己的 file_operations 来声明其“write”方法。因此,它声明其 inode_operations,该操作指向其文件操作。每当调用其 write() 实现时,该文件都会要求 kerneld 加载或卸载已写入其名称的模块。该文件可由任何人写入。这不是一个大问题,因为加载模块并不意味着访问其资源,并且可加载的内容仍然由 root 用户通过 /etc/modules.conf 控制。
/proc/jiffies 更容易;该文件是只读的。2.0 及更高版本的内核为只读文件提供了简化的接口:get_info 函数指针(如果设置)将在每次读取文件时被要求填充一页数据。因此,/proc/jiffies 不需要自己的文件操作也不需要 inode 操作;它只使用 get_info。该函数使用 sprintf() 将整数 jiffies 值转换为字符串。
清单 6 中的 tty 会话快照显示了这些文件的外观以及其中两个文件的工作方式。最后,清单 7 显示了用于在 /proc 中声明文件条目的三个结构。这些结构尚未完全定义,因为 C 编译器会用零填充任何部分定义的结构,而不会发出任何警告(功能,而不是错误)。
该模块已在 PC、Alpha 和 Sparc 上编译和运行,所有这些都运行 Linux 版本 2.0.x
/proc 实现还提供了其他有趣的功能,最值得注意的是 sysctl 接口。这个想法非常有趣,需要在未来的 Kernel Korner 中介绍。
我的讨论现在结束了,但是有很多地方可以查看有趣的源代码。值得研究的文件系统类型的实现
显然,“/proc”文件系统:它很容易查看,因为它既不是性能关键型的,也不是特别功能齐全的(除了 sysctl 想法)。说够了。
“UMSDOS”文件系统:它是主流内核的一部分,并且 piggy-back 在“Ms-DOS”文件系统上运行。它仅实现 VFS 的少数操作,以向旧式文件系统格式添加新功能。
“userfs”模块:它在 tsx-11 和 sunsite 的 ALPHA/userfs 下都可用;0.9.3 版本将加载到 Linux 2.0。该模块定义了一种新的文件系统类型,该类型使用外部程序来检索数据;有趣的应用是 ftp 文件系统和用于挂载压缩 tar 文件的只读文件系统。即使恢复到用户程序来获取文件系统数据是危险的,并且可能导致意外的死锁,但这个想法还是很有趣的。
“supermount”:该文件系统在 sunsite 和镜像上可用。这种文件系统类型能够挂载可移动设备(如软盘或 CD-ROM),并处理设备移除,而无需强制用户 umount/mount 设备。该模块的工作原理是控制另一种文件系统类型,同时安排在设备未使用时保持卸载状态;该操作对用户是透明的。
“ext2”:extended-2 文件系统在过去几年一直是标准的 Linux 文件系统。代码很复杂,但对于那些有兴趣了解如何实现真实文件系统的人来说,值得阅读。它还具有用于有趣的安全功能的钩子,例如 immutable-flag 和 append-only-flag。标记为 immutable 或 append-only 的文件只能在系统处于单用户模式时删除,因此可以防止网络入侵者。
“romfs”:这是我见过的最小的文件系统。它是在 Linux-2.1.21 中引入的。它是一个单一的源文件,浏览起来非常愉快。正如其名称所表明的那样,它是只读的。
是一个狂野的灵魂,对源代码有吸引力。他是 Linus Torvalds 和 Baden Powell 的粉丝,并享受他们吸引的两个志愿者社区。可以通过 rubini@linux.it 联系到他。

