
EXT2 文件系统非技术内幕
每个人都想要一台快速的计算机;然而,并非每个人都意识到计算机性能最重要的因素之一是文件系统的速度。无论您的 CPU 有多快,如果文件系统很慢,那么整台计算机都会显得很慢。许多拥有非常快的奔腾 Pro 处理器但磁盘驱动器速度缓慢,甚至网络文件系统更慢的人每天都在重新发现这个事实。
Linux 有一个非常快速的文件系统,称为 扩展文件系统版本 2 (EXT2)。EXT2 文件系统由 Remy Card (card@masi.ibp.fr) 创建。
在决定如何在磁盘上布局数据时,有几个目标。
首先也是最重要的,数据结构应该是 可恢复的。如果在将数据写入磁盘时发生错误(例如用户拔掉电源线),则不应丢失整个文件系统。虽然丢失当前正在写入的数据有时是可以接受的,但丢失磁盘上的所有数据是不可接受的。
其次,数据结构必须允许 高效地实现 所有需要的操作。最难实现的操作通常是硬链接。当使用硬链接时,有多个目录条目(即文件名)指向相同的文件数据。通过任何有效的文件名访问数据都应产生相同的数据。
另一个困难的操作涉及删除打开的文件。如果应用程序在用户删除文件的同时打开文件进行访问,则应用程序应该仍然能够访问文件的数据。在最后一个应用程序关闭文件之前,不应从磁盘上清除数据。这种行为与 DOS/Windows 完全不同,在 DOS/Windows 中,删除文件会导致任何正在读取/写入该文件的应用程序立即失去对该文件的访问权限。表现出这种 Unix 行为的应用程序比人们想象的要普遍得多,改变它会导致许多应用程序崩溃。
第三,磁盘布局应通过在磁盘上 聚簇 数据来最大限度地减少寻道时间。驱动器读取磁盘上相距较远的两段数据比读取彼此靠近的相同大小的数据段需要更多时间。良好的磁盘布局可以通过将相关数据聚簇在一起,最大限度地减少磁盘寻道时间(并最大限度地提高性能)。例如,同一文件的各个部分应该在磁盘上彼此靠近,并且也应该靠近包含文件名的目录。
最后,磁盘布局应该 节省磁盘空间。当硬盘驱动器又小又贵时,节省磁盘空间在过去更为重要。如今,节省磁盘空间已不那么重要了;但是,不应该浪费磁盘空间。
分区是磁盘布局的第一个级别。每个磁盘必须有一个或多个分区。操作系统假装每个分区都是一个单独的逻辑磁盘,即使它们可能共享同一个物理磁盘。分区最常见的用途是在同一个物理磁盘上放置多个文件系统,每个文件系统位于其自己的分区中。每个分区在 /dev 目录中都有自己的设备文件(例如,/dev/hda1, /dev/hda2 等)。每个 EXT2 文件系统占用一个分区,并完全填充它。
EXT2 文件系统分为 组,组是分区的一部分。分组是在格式化文件系统时完成的,并且在不重新格式化的情况下无法更改。每个组都包含相关数据。组是 EXT2 文件系统中的聚簇单位。每个组都包含一个 超级块、一个 组描述符、一个 块位图、一个 inode 位图、一个 inode 表,最后是 数据块,所有这些都按此顺序排列。
有关文件系统的一些信息属于整个文件系统,而不属于任何特定的文件或组。此信息存储在 超级块 中,包括文件系统内的块总数、上次检查错误的时间等等。
第一个超级块是最重要的,因为它是挂载文件系统时首先读取的超级块。超级块中的信息非常重要,没有它就无法挂载文件系统。如果在更新超级块时发生磁盘错误,则整个文件系统将被破坏;因此,每个组中都保留了超级块的副本。如果第一个超级块损坏,则可以使用冗余副本通过使用命令 e2fsck 来修复错误。
每个组的下一个块是 组描述符。组描述符存储有关每个组的信息。在每个组描述符中,都有一个指向 inode 表的指针(稍后会详细介绍 inode)以及 inode 和数据块的 分配位图。
分配位图只是一个位列表,描述了哪些块或 inode 正在使用中。例如,如果数据位图中的第 123 位被设置,则数据块编号 123 正在使用中。通过使用数据和 inode 位图,文件系统可以确定哪些块和 inode 当前正在使用中,哪些可用于将来使用。
磁盘上的每个文件都与正好一个 inode 相关联。inode 存储有关文件的重要信息,包括创建和修改时间、文件的权限以及文件的所有者。inode 还包含文件的类型(常规文件、目录、设备文件,如 /dev/ttyS1 等)以及文件在磁盘上的位置。
文件中的数据不存储在 inode 本身中。相反,inode 指向磁盘上数据的位置。每个 inode 中都有十五个指向数据块的指针。但是,这并不意味着文件只能有十五个块长。相反,由于数据指针指向数据的间接方式,文件可以长达数百万个块。
前十三个指针直接指向包含文件数据的块。如果文件少于或等于十三个块长,则文件的数据由每个 inode 中的指针直接指向,并且可以快速访问。第十四个指针称为间接指针,它指向一个指针块,每个指针块都指向磁盘上的数据。第十五个指针称为双重间接指针,它指向一个块,该块包含许多指向块的指针,每个块都指向磁盘上的数据。图 1 中显示的图片应该可以清楚地说明问题。
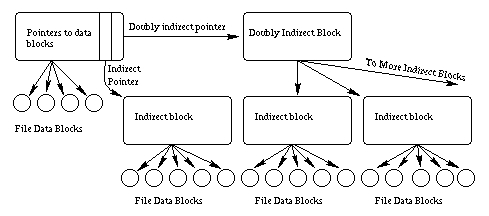
图 1. inode 与其关联数据之间的指针。
此方案允许直接访问小文件(少于十四个块的文件)的所有数据,并且仍然允许访问只有少量额外访问权限的非常大的文件。如表 1 所示,几乎所有文件实际上都很小;因此,几乎所有文件都可以使用此方案快速访问。
Inodes 存储在 inode 表中,inode 表位于每个组中组描述符指向的位置。inode 表的位置和大小在格式化时设置,并且在不重新格式化的情况下无法更改。这意味着文件系统中文件的最大数量也在格式化时固定。但是,每次格式化文件系统时,都可以使用 mke2fs 的 -i 选项设置 inode 的最大数量。
没有人会喜欢通过 inode 编号访问文件的文件系统。相反,人们希望给文件提供文本名称。目录将这些文本名称与文件系统内部使用的 inode 编号关联起来。大多数人没有意识到目录只是文件,其数据采用特殊的目录格式。事实上,在一些较旧的 Unix 系统上,您可以在目录上运行编辑器,只是为了看看它们的内部结构(想象一下运行 vi /tmp)。
每个目录都是目录条目的列表。每个目录条目将一个文件名与一个 inode 编号关联起来,并由 inode 编号、文件名的长度和文件名的实际文本组成。
根目录始终存储在 inode 编号 2 中,以便文件系统代码可以在挂载时找到它。子目录是通过在名称字段中存储子目录的名称,并在 inode 字段中存储子目录的 inode 编号来实现的。硬链接是通过使用多个文件名存储相同的 inode 编号来实现的。通过任一名称访问文件都会产生相同的 inode 编号,因此,产生相同的数据。
特殊目录“.”和“..”是通过在目录中存储名称“.”和“..”并在 inode 字段中存储当前目录和父目录的 inode 编号来实现的。这两个条目获得的唯一特殊待遇是,它们在创建任何新目录时都会自动创建,并且无法删除。
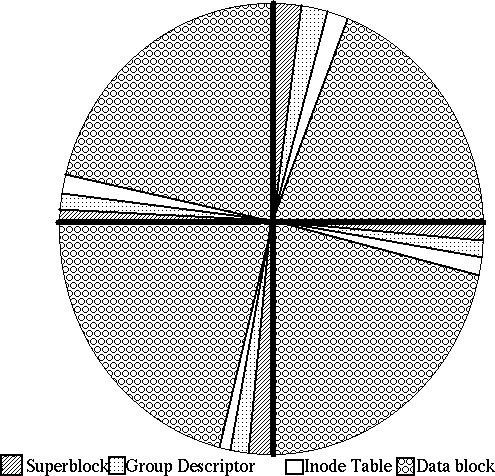
图 2. 具有一个分区和四个组的磁盘布局。
为了解释运行中的 EXT2 文件系统,我们将需要两件事:一个名为 DIR 的变量,用于保存目录,以及一个要查找的路径名。一些路径名有很多组件(例如,/usr/X11/bin/Xrefresh),而另一些则没有(例如,/vmlinuz)。
假设一个进程想要打开一个文件。每个进程都与一个当前工作目录相关联。所有不以“/”开头的文件名都相对于此当前工作目录解析,DIR 以当前工作目录开头。以“/”开头的文件名相对于根目录解析(有关一个例外,请参阅 chroot),DIR 以根目录开头。
要解析的路径中的每个目录名称都会依次在 DIR 中查找。此查找会产生我们感兴趣的子目录的 inode 编号。
接下来,访问子目录的 inode。检查权限,如果您具有访问权限,则此新目录将变为 DIR。路径中的每个子目录都以这种方式处理,直到只剩下路径的最后一个组件。
当到达路径名的最后一个组件时,变量 DIR 包含包含我们一直在搜索的文件名的目录。在 DIR 中查找,我们可以找到文件的 inode 编号。访问此最终 inode 会告诉我们数据的位置。检查权限后,您可以访问数据。
访问您想要的数据需要多少次磁盘访问?合理的上限是每个子目录两次(一次查找名称,另一次查找 inode),以及实际文件名再两次。此工作仅在文件打开时执行。打开文件后,后续访问可以使用 inode 的数据,而无需再次查找。此外,缓存 消除了查找文件所需的许多访问(稍后会详细介绍)。
当创建新文件或目录时,EXT2 文件系统必须决定将数据存储在哪里。如果磁盘大部分是空的,则数据几乎可以存储在任何地方。但是,如果数据与其他相关数据聚簇在一起以最大限度地减少寻道时间,则性能将最大化。
EXT2 文件系统尝试在其父目录所在的组中分配每个新目录,其理论是访问父目录和子目录将密切相关。EXT2 文件系统还尝试将文件放置在其目录条目所在的同一组中,因为目录访问通常会导致文件访问。但是,如果组已满,则新文件或新目录将放置在其他非满组中。
存储目录和文件所需的数据块可以通过查看数据分配位图找到。inode 表中任何所需的空间都可以通过查看 inode 分配位图找到。
与大多数文件系统一样,EXT2 系统非常依赖缓存。缓存 是 RAM 的一部分,专用于保存文件系统数据。缓存保存目录信息 inode 信息和实际文件内容。每当应用程序(如文本编辑器或编译器)尝试查找文件名或请求文件数据时,EXT2 系统首先检查缓存。如果可以在缓存中找到答案,则可以非常快速地回答请求,而无需使用磁盘。
缓存填充了来自先前请求的数据。如果您请求以前从未请求过的数据,则必须首先从磁盘检索数据。大多数时候,大多数人都会请求他们以前使用过的数据。这些重复请求可以从缓存中快速回答,从而为磁盘驱动器节省大量工作,同时为用户提供快速访问。
当然,每台计算机的可用 RAM 量是有限的。大多数 RAM 用于其他用途,例如运行应用程序,可能只剩下总 RAM 的 10% 到 30% 可用于缓存。当缓存已满时,最旧的未使用数据(最近最少使用的数据)将被丢弃。只有最近使用的数据保留在缓存中。
由于较大的缓存可以容纳更多数据,因此它们也可以满足更多的请求。下图显示了总缓存大小与可以从缓存中满足的所有请求的百分比的典型曲线。如图 3 所示,使用更多 RAM 进行缓存会增加从缓存中回答的请求数量,从而提高文件系统的表面速度。

图 3. 总缓存大小与从缓存中满足的请求数量的典型曲线。
正如之前所说,应该尽可能简单,但不能更简单。EXT2 文件系统比大多数人意识到的要复杂得多,但这种复杂性导致全套 Unix 操作都能正确运行,并且性能良好。该代码是健壮且经过良好测试的,并且为 Linux 社区提供了良好的服务。我们都应该感谢 M. Card。
Randy Appleton 是北密歇根大学计算机科学教授。他在肯塔基大学获得博士学位。自 0.9 版本之前,他就一直参与 Linux。当前的研究包括高性能预取文件系统,即将移植到 Linux 的 2.X 版本。其他兴趣包括飞机,尤其是自制飞机。可以通过电子邮件 randy@euclid.acs.nmu.edu 与他联系。
