
Coda 分布式文件系统
Coda 分布式文件系统是由 M. Satyanarayanan 在卡内基梅隆大学 (CMU) 小组中开发的最先进的实验性文件系统。许多人为 Coda 贡献了力量,现在 Coda 包含了许多其他系统中没有的功能
移动计算:
移动客户端的断开连接操作
从断开连接的客户端重新集成数据
带宽适配
故障恢复能力:
读/写复制服务器
服务器/服务器冲突的解决
处理分割服务器的网络故障
处理客户端的客户端断开连接
性能和可扩展性:
客户端持久缓存文件、目录和属性以实现高性能
写回缓存
安全:
类 Kerberos 身份验证
访问控制列表 (ACL)
明确定义的共享语义
免费提供的源代码
分布式文件系统将文件存储在一台或多台称为服务器的计算机上,并使其他称为客户端的计算机可以访问这些文件,在客户端看来这些文件就像普通文件一样。使用文件服务器有几个优点:文件更广泛可用,因为许多计算机可以访问服务器;从单个位置共享文件比将文件副本分发给各个客户端更容易。备份和信息安全更容易安排,因为只需要备份服务器。服务器可以提供大量的存储空间,这对于每个客户端来说可能是昂贵的或不切实际的。当考虑一组员工共享文档时,分布式文件系统的用处就显而易见了;然而,还有更多的可能性。例如,共享应用软件也是一个同样好的选择。在这两种情况下,系统管理都变得更加容易。
在设计良好的分布式文件系统时,会面临许多问题。通过网络传输大量文件很容易导致性能和延迟降低;可能导致网络瓶颈和服务器过载。数据安全是另一个重要问题:我们如何确保客户端确实被授权访问信息,以及如何防止数据在网络上被嗅探?设计面临的另外两个问题与故障有关。通常,客户端计算机比连接它们的网络更可靠,网络故障可能会使客户端变得无用。同样,服务器故障可能非常令人不愉快,因为它可能会使所有客户端都无法访问关键信息。Coda 项目已经关注了许多这些问题,并将它们作为研究原型来实现。
图 2. 服务器控制安全(Gaich Muramatsu 插图)
Coda 最初是在 Mach 2.6 上实现的,最近已移植到 Linux、NetBSD 和 FreeBSD。Michael Callahan 将 Coda 的大部分移植到了 Windows 95,我们正在研究 Windows NT,以了解将 Coda 移植到 NT 的可行性。目前,我们的工作重点是移植和使系统更加健壮。正在实现一些新功能(例如,写回缓存和单元),并且在几个领域,Coda 的组件正在被重组。我们已经收到了来自网络用户的非常慷慨的帮助,我们希望这种情况能够继续下去。也许 Coda 可以成为一个流行的、广泛使用的和免费提供的分布式文件系统。
如果 Coda 在客户端上运行(我们将其视为 Linux 工作站),则键入 mount 将显示一个文件系统(类型为“Coda”)挂载在 /coda 下。任何服务器可能向客户端提供的所有文件都可以在此目录下访问,并且所有客户端都看到相同的命名空间。客户端连接到“Coda”而不是单个服务器,这些服务器会隐式地发挥作用。这与挂载 NFS 文件系统非常不同,NFS 文件系统是基于每个服务器、每个导出来完成的。在最常见的 Windows 系统(Novell 和 Microsoft 的 CIFS)以及 Macintosh 上的 Appleshare 中,文件也是按卷挂载的。然而,全局命名空间并不是什么新鲜事物。Coda 的前身 Andrew 文件系统率先提出了这个想法,并将所有文件存储在 /afs 下。同样,来自 OSF 的分布式文件系统 DFS/DCE 将其文件挂载在一个目录下。Microsoft 的新分布式文件系统 (dfs) 提供了将所有服务器共享放在单个文件树中的粘合剂,类似于 UNIX 上自动挂载守护程序和黄页提供的粘合剂。为什么单个挂载点是有利的?这意味着所有客户端都可以进行相同的配置,并且用户将始终看到相同的文件树。对于大型安装来说,这至关重要。使用 NFS,客户端需要在 /etc/fstab 中有一个最新的服务器列表及其导出的目录,而在 Coda 中,客户端只需要知道在哪里找到 Coda 根目录 /coda。当添加新的服务器或共享时,客户端将在 /coda 树中自动发现这些服务器或共享。
为了理解当与服务器的网络连接断开时 Coda 如何运行,让我们分析一个简单的文件系统操作。假设我们键入
cat /coda/tmp/foo
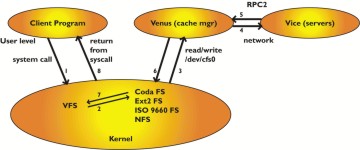
来显示 Coda 文件的内容。实际发生了什么?cat 程序将对该文件进行一些系统调用。系统调用是程序通过它向内核请求服务的操作。例如,当打开文件时,内核将要执行查找操作以找到该文件的 inode 并返回与该文件关联的文件句柄给程序。inode 包含访问文件中数据的信息,供内核使用;文件句柄供打开程序使用。打开调用进入内核中的虚拟文件系统 (VFS),当意识到请求是针对 /coda 文件系统中的文件时,它将请求传递给内核中的 Coda 文件系统模块。Coda 是一个相当简约的文件系统模块:它保留了最近来自 VFS 的已应答请求的缓存,否则将请求传递给 Coda 缓存管理器 Venus。Venus 将检查客户端磁盘缓存中是否有 tmp/foo,如果缓存未命中,它将联系服务器以请求 tmp/foo。当文件被找到后,Venus 会响应内核,内核又会从系统调用返回调用程序。示意性地,我们有图 3 中所示的图像。
该图显示了用户程序如何通过系统调用向内核请求服务。内核通过允许 Venus 从字符设备 /dev/cfs0 读取请求,将其传递给 Venus。Venus 尝试通过查看其缓存、询问服务器或可能通过声明断开连接并在断开连接模式下提供服务来应答请求。当没有与任何拥有文件的服务器的网络连接时,断开连接模式就会启动。通常,当笔记本电脑从网络上取下或在网络故障期间会发生这种情况。如果服务器发生故障,断开连接操作也可能会生效。
当内核第一次将打开请求传递给 Venus 时,Venus 会使用远程过程调用从服务器获取整个文件以到达服务器。然后,它将文件作为容器文件存储在缓存区域中(当前为 /usr/coda/venus.cache/)。该文件现在是本地磁盘上的普通文件,并且对该文件的读/写操作不会到达 Venus,而是(几乎)完全由本地文件系统(Linux 的 EXT2)处理。Coda 读/写操作的速度与本地文件的速度相同。如果文件第二次打开,则不会再次从服务器获取,但本地副本将立即可用。目录文件(请记住,目录只是一个文件)以及所有属性(所有权、权限和大小)都由 Venus 缓存,并且如果缓存中存在文件,则 Venus 允许操作继续进行而无需联系服务器。如果文件已被修改并已关闭,则 Venus 会通过发送新文件来更新服务器。其他修改文件系统的操作,例如创建目录、删除文件或目录以及创建或删除(符号)链接也会传播到服务器。
因此,我们看到 Coda 缓存了客户端上所需的所有信息,并且仅将对文件系统的更新通知服务器。研究证实,与文件的“只读”访问相比,修改非常罕见,因此我们在消除客户端-服务器通信方面取得了很大进展。在 AFS 和 DFS 中实现了这些积极缓存数据的机制,但大多数其他系统都具有更基本的缓存。稍后我们将看到 Coda 如何保持文件一致性,但首先要探讨还需要什么来支持断开连接操作。
Coda 中断开连接操作的起源在于该项目的最初研究目标之一:提供一个能够应对网络故障的文件系统。在 80 年代后期,在 CMU 校园中支持数千个客户端的 AFS 变得如此庞大,以至于几乎每天都会在某个地方发生网络中断和服务器故障。这是一个麻烦。由于移动客户端(即笔记本电脑)的快速发展,Coda 也被证明是一项及时的努力。Coda 对故障网络和服务器的支持同样适用于移动客户端。
我们在上一节中看到,Coda 缓存了提供数据访问所需的所有信息。当对文件系统进行更新时,这些更新需要传播到服务器。在正常的连接模式下,此类更新会同步传播到服务器,即,当更新在客户端上完成时,它也已在服务器上完成。如果服务器不可用,或者客户端和服务器之间的网络连接失败,则此类操作将导致超时错误并失败。有时,无能为力。例如,尝试从服务器获取缓存中没有的文件在没有网络连接的情况下是不可能的。在这种情况下,必须将错误报告给调用程序。但是,通常可以按如下方式优雅地处理超时。
为了支持断开连接的计算机或在存在网络故障的情况下运行,当更新导致超时时,Venus 不会向用户报告故障。相反,Venus 意识到有问题的服务器不可用,并且应该在客户端记录更新。在断开连接期间,所有更新都存储在 CML(客户端修改日志)中,CML 经常刷新到磁盘。当 Coda 切换到断开连接模式时,用户不会注意到任何事情。重新连接到服务器后,Venus 将重新集成 CML:它要求服务器在服务器上重放文件系统更新,从而使服务器保持最新状态。此外,CML 经过了优化——例如,如果文件先创建然后删除,则 CML 会取消。
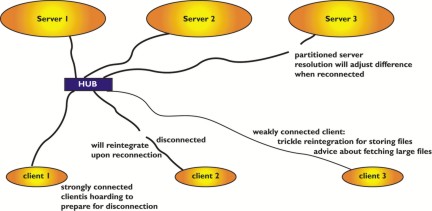
还有两个对断开连接操作至关重要的问题。首先,是囤积文件的概念。由于 Venus 在断开连接期间无法处理缓存未命中,因此如果它通过频繁询问服务器发送最新更新来使缓存中重要的文件保持最新状态,那将是很好的。此类重要文件位于用户的囤积数据库中,该数据库可以通过“监视”用户的文档访问来自动构建。更新囤积的文件称为囤积漫游。在实践中,我们的笔记本电脑囤积了大量的系统软件,例如 X11 窗口系统二进制文件和库,或 Wabi 和 Microsoft Office。由于文件就是文件,因此传统应用程序可以正常运行。
图 4. 囤积的文件在缓存中是“粘性的”。(Gaich Muramatsu 插图)
第二个问题是,在重新集成期间,可能会出现断开连接期间另一个客户端也修改了文件并将其发送到服务器的情况。这称为本地/全局冲突(即客户端/服务器),需要修复。有时可以通过特定于应用程序的解析器自动完成修复(这些解析器知道一个客户端在日历文件中插入了星期一的约会,而另一个客户端插入了星期二的约会,并没有造成无法解决的冲突)。有时,但很少需要人工干预来修复冲突。
星期五,一个人带着大量源代码离开办公室,这些源代码囤积在笔记本电脑上。在山间小屋中破解了一番之后,周一(当然是 10 天后)回到办公室的艰苦旅程从重新集成周末所做的更新开始。移动计算由此诞生。
在大多数网络文件系统中,服务器都享有标准文件结构,并将目录导出到客户端。服务器上的此类文件目录可以挂载在客户端上,在 Windows 术语中称为网络共享,在 UNIX 世界中称为网络文件系统。对于大多数此类系统来说,在已经挂载的网络卷内挂载进一步的分布式卷是不切实际的。需要对分区、目录和共享的服务器布局进行极其谨慎和周密的考虑。Coda(和 AFS)的组织结构截然不同。
Coda 服务器上的文件不存储在传统文件系统中。Coda 服务器工作站上的分区可以提供给文件服务器。这些分区将包含分组到卷中的文件。每个卷都有一个像文件系统一样的目录结构,即卷的根目录和它下面的树。卷总体上比分区小得多,但比单个目录大得多,并且是文件的逻辑单元。例如,用户的家目录通常是单个 Coda 卷,类似地,Coda 源代码将驻留在单个卷中。通常,单个服务器将拥有数百个卷,平均大小可能约为 10MB。卷是可管理的文件数据量,从系统管理的角度来看,这是一个非常自然的单元,并且已被证明非常灵活。
Coda 在原始分区中保存卷和目录信息、访问控制列表和文件属性信息。这些信息通过基于日志的可恢复虚拟内存包 (RVM) 访问,以提高速度和一致性。只有文件数据驻留在服务器分区的文件中。RVM 内置了对事务的支持——这意味着,如果服务器崩溃,系统可以恢复到一致状态,而无需付出太多努力。
卷具有名称和 ID,并且可以将卷挂载在 /coda 下的任何位置。例如,要在 /coda/usr/braam 上挂载卷 u.braam,请发出命令
cfs makemount u.braam /coda/usr/braam
Coda 不允许挂载点是现有目录;相反,它将在挂载过程中创建一个新目录。这消除了在现有目录之上挂载 UNIX 文件系统时可能引起的混乱。虽然它看起来与 Macintosh 和 Windows 创建“网络驱动器和卷”的传统非常相似,但关键的区别在于挂载点对客户端是不可见的:它在 /coda 下显示为普通目录。单个卷享有作为根卷的特权;它是启动时挂载在 /coda 上的卷。
Coda 通过称为 Fid 的 32 位整数三元组来标识文件:它由 VolumeId、VnodeId 和 Uniquifier 组成。VolumeId 标识文件所在的卷。VnodeId 是文件的“inode”号,而 uniquifier 用于解析。Fid 在 Coda 服务器集群中是唯一的。
Coda 具有读/写复制服务器,即,一组服务器可以将文件数据分发给客户端,并且通常对该组中的所有服务器进行更新。这样做的好处是数据可用性更高:如果一台服务器发生故障,其他服务器会接管,而客户端不会注意到故障。卷可以存储在一组称为 VSG(卷存储组)的服务器上。
对于复制卷,VolumeId 是复制的 VolumeId。复制的卷 ID 将卷存储组和每个成员上的本地卷结合在一起。
VSG 是一个服务器列表,其中包含复制卷的副本。
每个服务器的本地卷定义一个分区和本地卷 ID,用于保存在该服务器上的文件和元数据。
当 Venus 希望访问服务器上的对象时,它首先需要找到包含该文件的卷的 VolumeInfo。此信息包含服务器列表和每个服务器上的本地卷 ID,卷通过这些 ID 为人所知。对于文件,与 VSG 中的服务器的通信是“读取一个,写入多个”;也就是说,从 VSG 中的单个服务器读取文件,并将更新传播到所有可用的 VSG 成员 AVSG。Coda 可以使用多播 RPC,因此写入多个更新不会造成严重的性能损失。
首先必须获取卷信息的开销也具有欺骗性。虽然卷信息是一次性查找的,但随后的文件访问会享受更短的路径遍历,因为卷的根目录比挂载大型目录时更近。
服务器复制与断开连接操作一样,有两个需要介绍的表亲:解析和修复。VSG 中的某些服务器可能会通过网络或服务器故障与其他服务器分区。在这种情况下,某些对象的 AVSG 将严格小于 VSG。更新无法传播到所有服务器,而只能传播到 AVSG 的成员,从而引入全局(即服务器/服务器)冲突。
图 6. AVSG 与 VSG(Gaich Muramatsu 插图)
在获取对象或其属性之前,Venus 将从所有可用服务器请求版本戳。如果它检测到某些服务器没有文件的最新副本,它将启动一个解析过程,该过程尝试自动解决差异。如果解析失败,则用户必须手动修复。解析虽然由客户端启动,但完全由服务器处理。
复制服务器和解析非常棒。我们的某些服务器有时会遭受磁盘故障。要修复服务器,只需插入新驱动器并告诉 Coda:解析它。解析系统会将新磁盘更新到与其他服务器相同的状态。
Coda 在 CMU 不断地被积极使用。数十个客户端将其用于(Coda 的)开发工作、作为通用文件系统以及用于特定的断开连接应用程序。以下两种场景非常成功地利用了 Coda 的功能。我们购买了许多 Wabi 和 Windows 软件的许可证。Wabi 允许人们运行 MS PowerPoint。我们将 Wabi 和 Windows 3.1(包括 MS Office)存储在 Coda 中,并由我们的客户端共享。当然,包含首选项的 .ini 文件对于给定用户来说是特定的,但大多数库和应用程序都不是。通过囤积,我们继续在断开连接的笔记本电脑上使用该软件进行演示。这种情况经常在会议上发生。
在其使用的多年中,我们没有丢失用户数据。我们服务器中的磁盘有时会发生故障,但由于我们所有的卷都是复制的,因此我们用一个空磁盘替换了该磁盘,并要求解析机制更新修复后的服务器。为此,您只需在新磁盘就位时在受影响的文件树中键入 ls -lR 即可。将会注意到修复后的服务器上缺少该文件,并且解析会将文件从良好的服务器传输到新修复的服务器。
Coda 可以在许多引人注目的未来应用中提供显着的好处。
FTP 镜像站点应该是 Coda 客户端。例如,让我们以 ftp.redhat.com 为例,它有许多镜像。每个镜像都激活一个 Perl 脚本,该脚本遍历 Red Hat 中的整个树,以查看已更新的内容并获取它——无论镜像站点是否需要它。将此与 Red Hat 将其 ftp 区域存储在 Coda 中进行对比。镜像站点也应该都成为 Coda 客户端,但只有 Red Hat 具有写入权限。当 Red Hat 更新一个包时,Coda 服务器会通知镜像站点该文件已更改。镜像站点将获取此包,但仅在下次有人尝试获取此包时才获取。
WWW 复制服务器应该是 Coda 客户端。许多 ISP 都在与一些 WWW 复制服务器作斗争。它们的访问量太大,无法仅使用单个 http 服务器。由于性能问题,使用 NFS 共享要服务的文档已被证明是有问题的,因此经常手动将文件复制到各个服务器。Coda 可以来救援,因为每个服务器都可以是 Coda 客户端并将其数据保存在其缓存中。这提供了本地磁盘速度的访问。将此与离线更新其 Web 信息的 ISP 客户端结合起来,我们也有了一个移动客户端的良好应用程序。
网络计算机可以利用 Coda 作为缓存来显着提高性能。对网络计算机的更新将自动进行,因为它们在服务器上变得可用,并且在大多数情况下,即使在重新启动后,计算机也将在没有网络流量的情况下运行。
我们目前的工作主要集中在提高 Coda 的质量上。研究系统不可避免地会带来的粗糙边缘正在慢慢消除。将添加写回缓存,以便 Coda 能够更快地运行。断开连接操作是写回缓存的一种极端形式,我们正在利用这些机制在连接操作期间进行写回缓存。正在添加 Kerberos 支持。支持 Coda 的网络协议使这很容易实现。我们希望拥有单元,这将允许客户端同时连接到多个 Coda 集群。进一步的移植有望使许多系统能够使用 Coda。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}