
Linux 性能监控工具
在过去的几年里,我一直在各种 UNIX 系统上为用户提供支持,并且发现系统会计报告数据对于性能分析非常宝贵。当我开始使用 Linux 作为我的个人工作站时,缺少类似的性能数据收集和报告工具集是一个真正的问题。当您没有数据来支持您“我需要更多性能!”的说法时,很难让管理层升级您的系统。因此,我开始寻找一个软件包来获取我需要的信息,但发现根本没有。我求助于最后的手段——我自己编写了一个,尽可能多地使用现有工具。我编写了一些脚本,可以收集数据并在 X11 窗口或硬拷贝中以图形方式显示出来。
为了很好地了解系统的性能,需要在一段时间内观察关键系统资源,以了解它们的使用率和可用性如何随着系统上运行的内容而变化。以下是我希望跟踪的系统资源类别。
CPU 利用率:从 Linux 的角度来看,中央处理器始终处于以下状态之一
空闲:可用于工作,等待中
用户:高级函数、数据移动、数学运算等
系统:执行内核函数、I/O 和其他硬件交互
低优先级:与用户状态类似,低优先级的作业会将 CPU 让给另一个优先级更高的任务
通过记录每种状态所花费的时间百分比,我们可以发现一种或另一种状态的过载。过多的空闲意味着无所事事;过多的系统时间表明需要更快的 I/O 或额外的设备来分散负载。每个系统在运行其工作负载时都会有自己的配置文件,通过长期观察这些数字,我们可以确定该系统的正常状态。一旦建立基线,我们就可以轻松检测到配置文件的变化。
中断:大多数 I/O 设备都使用中断来向 CPU 发出信号,表明有工作要做。例如,SCSI 控制器会发出中断信号,表明请求的磁盘块已被读取并可在内存中使用。带有鼠标的串行端口每次按下/释放按钮或移动鼠标时都会生成中断。观察每个中断的计数可以大致了解关联设备正在处理的负载量。
上下文切换:时间分片是经常用来描述计算机如何看似同时执行多项作业的术语。每个任务都被赋予系统控制权一段时间“切片”,当时间到了,系统会保存正在运行的进程的状态,并将系统控制权交给另一个进程,确保必要的资源可用。这个管理过程称为上下文切换。在某些操作系统中,这种切换的成本可能相当昂贵,有时会消耗比它切换的进程更多的资源。Linux 在这方面做得非常好,但是通过观察这种活动的数量,您将学会识别系统何时有大量任务在积极消耗资源。
内存:当许多进程正在运行并占用可用内存时,系统会变慢,因为进程会被分页或交换出去,以便为其他进程运行腾出空间。当时间片耗尽时,该任务可能必须被写入分页设备,以便为下一个进程让路。内存利用率图表有助于指出内存问题。
分页:如上所述,当可用内存开始变得稀缺时,虚拟内存系统将开始将实内存页写入交换设备,从而释放活动进程的空间。磁盘驱动器速度很快,但是当分页超出一定程度时,系统可能会将所有时间都花在页面的来回传输上。Linux 系统上的分页也可能因程序加载而增加,因为 Linux 会“按需分页”每个可执行文件的部分。
交换:交换非常像分页。但是,它迁移整个进程映像(由许多内存页组成)从实内存到交换设备,而不是通常用于分页的逐页机制。
磁盘 I/O:Linux 保留前四个磁盘的统计信息;总 I/O、读取、写入、块读取和块写入。这些数字可以显示多个磁盘的负载不均,并显示读取与写入的平衡。
网络 I/O:网络 I/O 可用于诊断问题和检查网络接口的负载。统计信息显示了传入和传出的流量、冲突以及在两个方向上遇到的错误。
这些图表还可以帮助解决以下情况
系统在您不在场的时间运行您不知道的作业。
有人在您不知情的情况下登录系统或远程运行命令。
这类信息通常会在系统本应处于空闲状态的时间在图表中显示为峰值。活动突然增加也可能是由 crontab 运行的作业引起的。
/proc/stat 文件包含了我想要的大部分数据的当前计数器,并且它是可读格式。为了使收集器脚本尽可能快速和简单,我将数据保存为可读格式,而不是二进制数据。
分解和重组数据以进行存储是 awk 的一项好工作,根据数据类型将数据写入不同的文件。/proc 文件为此格式化得很好;每个记录在第一个字段都有一个标识名称。以下是我的 486 系统中 /proc/stat 的示例
cpu 1228835 394 629667 23922418 disk 43056 111530 0 0 disk_rio 18701 20505 0 0 disk_wio 24355 91025 0 0 disk_rblk 37408 40690 0 0 disk_wblk 48710 182050 0 0 page 94533 204827 swap 1 0 intr 27433973 25781314 58961 0 1059544 368102 1 2\ 0 0 0 11133 154916 0 0 0 0 ctxt 18176677 btime 863065361 processes 18180
我深入研究了 /proc 文件系统的内核源代码,以弄清楚各个字段是什么,因为手册页似乎可以追溯到 1.x。
cpu:包含以下信息:在用户/低优先级/系统/空闲状态下花费的节拍数(百分之一秒)。我不太关心实际测量值,因为我只是计划将每种状态视为总数的百分比。
disk:汇总了对四个磁盘中每个磁盘的所有 I/O,而 disk_rio、disk_wio、disk_rblk 和 disk_wblk 将总数分解为读取、写入、块读取和块写入。
page:页面调入和调出计数器
swap:换入和换出的页面计数。/proc/meminfo 中的交换数据表示为总页数、已用和可用。结合两组数据可以清晰地了解交换活动。
intr:自启动以来中断总数,后跟每个中断的计数。
ctxt:自启动以来上下文切换的次数。这计算了一个进程“进入休眠”而另一个进程被“唤醒”的次数。
btime:我没有发现它有什么用处——它是系统启动后自 1970 年 1 月 1 日起的秒数。
processes:最新的进程标识号。这是查看自上次检查以来已生成多少进程的好方法,因此通过从当前值中减去旧值,然后除以两次观察之间的时间差(以秒为单位),就可以知道每秒的新进程数,并可以用来衡量系统的繁忙程度。
我们在这里需要的行是 ethx 和 pppx 记录。在收集器脚本中,数据使用完整的接口名称写入文件。这样,该脚本就可以推广到大多数配置。
内存利用率可以在 /proc/meminfo 文件中跟踪,如 表 2 所示。
内存计数器在此文件中表示了两次,因此我们只需要保存 Mem: 和 Swap: 记录即可获得完整画面。该脚本匹配行首的关键字,并将数据写入单独的文件,而不是写入一个大型数据库,以便在添加新字段或数据类型时具有更大的灵活性。这会使目录变得混乱,但脚本编写更简单。
收集数据的脚本如 清单 1 所示。以下是几个关键部分正在发生的事情,以及注释
第 13 行:使用 cd 移动到要存储数据的目录。
第 14 行:以 HHMM 格式获取数据记录的时间戳。
第 15 行:以 MonDD.YY 格式获取输出数据文件名的日期。
第 19 - 25 行:从 /proc/meminfo 中选择内存和交换计数器行,并将记录的时间戳和数据部分写入 Mem.MonDD.YY 和 Swap.MonDD.YY。
第 29 - 36 行:从 /proc/net/dev 中提取任何网络接口的计数器,并将它们写入包含接口号的文件,即 eth0 数据写入 eth0.MonDD.YY。
第 39 - 79 行:从 /proc/stat 中剪切 cpu、磁盘、分页、交换页面使用情况、中断、上下文切换和进程号的计数器,并将它们写入相应的文件。
我的 crontab 文件中的以下行每天每小时每五分钟运行一次收集脚本
0,5,10,15,20,25,30,35,40,45,50,55 * * * *\
/var/log/sar/sa 0 0 * * * exec /usr/bin/find\
/var/log/sar/data/ -mtime +14
-exec /bin/rm -f {} \;
数据在一天中累积,为分析提供数据点。第二行调用的清理脚本会在两周后删除每个文件,以减少磁盘空间需求。可能的增强功能可能是压缩每个完成的文件,但空间尚未成为大问题。我现在有了数据,但是由于数字列很枯燥,所以我需要一种查看数据并理解其含义的方法。我曾在其他系统上使用 gnuplot 进行类似的工具,因此它似乎是一个不错的选择。我从一个脚本开始显示 CPU 利用率,绘制空闲、用户、系统和低优先级状态所花费的时间百分比。
cpu 数据文件有五列,如下所示
0000 4690259 69915 661038 7937582 0005 4690408 69964 661286 7966975
第 1 列:自上次启动以来处于空闲状态的秒数 第 2 列:自上次启动以来处于系统状态的秒数 第 3 列:自上次启动以来处于低优先级状态的秒数 第 4 列:自上次启动以来处于用户状态的秒数 第 5 列:观察的时间戳 (HHMM)
我的报告方案是获取自上次观察以来每种状态所花费的秒数,将不同状态加起来,并将每种状态表示为总数的百分比。我立即遇到了一个有趣的问题——重启怎么办?重启系统会将计数器归零,从新值中减去旧值会生成负值,因此我必须正确处理它才能提供有用的信息。我决定监视低于上次观察值的计数器值,如果发现,则将先前的值重置为零。为了使图表更具信息性,重启的数据点设置为 100,正常记录的数据点设置为 -1。-1 值会导致数据点超出图表范围,因此不显示。
有时,当需要演示文稿或报告时,最好使用硬拷贝。gnuplot 作者提供了各种输出格式,脚本将在 X11 显示和 PostScript 输出之间切换,具体取决于设置了哪些选项开关。
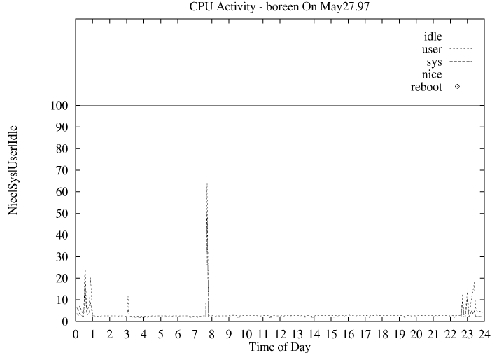
图 1. 示例图表
图 1 是图表脚本生成的示例图表,如 清单 2 所示。此脚本的主要部分的分解包含在 SSC 的 FTP 站点上的存档文件中,ftp.linuxjournal.com/pub/lj/listings/issue56/2396.tgz。还包括收集脚本、图表脚本、用于运行收集脚本的示例 crontab 条目以及以下图表脚本
cpu:绘制如上所述的 cpu 信息
ctxt:绘制每秒上下文切换次数
disk:磁盘利用率:每秒总 I/O、读/写和块读/写
eth:每秒发送和接收的以太网数据包以及传入和传出错误
intr:按中断号划分的中断,并按每秒绘制图表
mem:内存利用率和缓冲区/缓存/共享内存分配
page:页面调入和调出活动
ppp:点对点协议每秒发送/接收的数据包和错误
proc:每秒新进程创建数
swap:交换活动和交换空间可用性
我目前正在将此工具包转换为 Perl,并构建一个 Web 界面,以允许将这些图表作为 HTML 页面查看,图表为 GIF 文件。
本文中引用的所有清单都可以通过匿名下载文件 ftp.linuxjournal.com/pub/lj/listings/issue56/2396.tgz 获取。

