
双向链表和抽象数据类型
经验丰富的 C 程序员如果想要摆脱编写链表的苦差事,并处理随之而来的问题,即以某种方式将它们与代码的其余部分隔离,将会欣赏这个双向链表库。那些处于 C 编程早期阶段的人也可能会在这里找到一个有用的工具来增强他们的跨平台编程技能,因为这个链表可以作为抽象数据类型 (ADT) 的一个例子。
使用 ADT 可以将特定代码段中的数据对不需要且不应访问它的其他代码段隐藏起来。这通常称为模块化编程或封装。ADT 背后的思想是隐藏代码的实际实现,只留下其抽象可见。为了做到这一点,需要找到链表代码和周围代码之间的清晰划分。当链表代码被移除时,剩下的是它的逻辑抽象。这种分离使得代码对任何一个平台的依赖性降低。因此,使用 ADT 方法进行编程通常被认为是跨平台开发的必要条件,因为它使应用程序代码的维护和管理更加容易。
ADT 概念在此通过双向链表应用程序编程接口 (API) 是如何创建的示例来展开。双向链表 (DLL) 也可以是一个独立的 C 模块,并编译到更大的程序中。
DLL 包由两个 C 模块组成:dll_main.c 包含 DLL 本身,dll_test.c 创建一个可执行程序来测试 DLL 的功能。还有三个头文件:dll_main.h 包含在 dll_main.c 中,linklist.h 包含在您的应用程序程序中,dll_dbg.h 用于调试 DLL 或 DLL 在您的应用程序中的实现。这里需要表达一个警告:头文件 dll_dbg.h 永远不应编译到生产程序中,因为这样做会规避 ADT 编程的整个概念。整个包已经在三个平台上用四个编译器编译过,并包含三个各自的 Makefile。只有一个平台由于编译器不完全兼容 ANSI 而出现问题。稍后将详细介绍平台。
在我们深入探讨这个 DLL 背后的理念之前,我想解释一下当我决定编写这个库时我的目标是什么。它首先必须是平台独立的和可实例化的;换句话说,DLL 必须能够同时处理任何一个或多个程序中无限数量的链表实例。此外,它必须是健壮的。
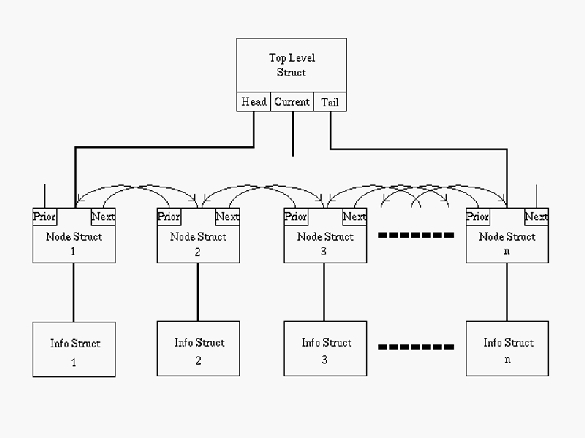
图 1. 双向链表在内存中的布局。 箭头指示 Prior 和 Next 指针指向的位置。Current 指针可以指向任何 Node Struct,因此它是开放式的。
为了满足第一个要求,我决定严格遵守 ANSI C 标准,并且,除了如何设置数据以及如何使用 DLL 的输入/输出函数之外,应该没有字节序(字节顺序)问题。第二个要求通过创建顶层结构来满足。每个链表只有一个这样的结构。它跟踪节点指针、应用程序数据的大小(以字节为单位)、列表中节点的数量、列表自创建或加载到内存后是否被修改、搜索从哪里开始以及搜索的方向。图 1 说明了顶层结构是如何集成到 DLL 中的。
typedef struct list
{
Node *head;
Node *tail;
Node *current;
Node *saved;
size_t infosize;
unsigned long listsize;
DLL_Boolean modified;
DLL_SrchOrigin search_origin;
DLL_SrchDir search_dir;
} List;
这个和下一个 typedef 结构对应用程序程序保持隐藏。上面提到的节点指针在下一个结构中定义,该结构包括指向应用程序数据的指针和指向下一个和上一个节点的指针。为列表中的每个节点创建一个这样的结构。
typedef struct node
{
Info *info;
struct node *next;
struct node *prior;
} Node;
最后一个定义是用户数据的虚拟 typedef。它被定义为 void 类型,以便 DLL 的函数能够处理任何 C 或应用程序的数据类型。typedef void Info;正如您所看到的,如果上面提到的两个结构对应用程序隐藏,那么链表如何运行的所有丑陋内部结构默认情况下都将对应用程序隐藏。因此,我们有了一个抽象数据类型。
接口本身在逻辑上是遵循的。所有 DLL 的 API 函数的第一个参数都是 List 类型的指针。这个指针可以很容易地更改为不同的列表,从而满足 DLL 的实例化要求。
API 的 25 个函数分为七个函数组:三个初始化、三个状态、四个数据修改、六个指针操作、六个搜索、两个输入/输出和一个杂项。初始化组处理 DLL 的创建、初始化和销毁。状态组返回关于 DLL 的各种类型的信息。指针操作组允许任意重新定位当前指针。数据修改组添加和删除节点。搜索组返回基于键控数据字段或绝对节点位置的节点信息。输入/输出组将节点数据保存到磁盘文件或从磁盘文件检索节点数据。杂项组目前只支持版本信息。
后面的函数原型将返回两个或多个 enum 类型或 boolean 类型。一些函数具有 void 返回值。
typedef enum
{
DLL_NORMAL, /* normal operation */
DLL_MEM_ERROR, /* malloc error */
DLL_ZERO_INFO, /* sizeof(Info) is zero */
DLL_NULL_LIST, /* List is NULL */
DLL_NOT_FOUND, /* Record not found */
DLL_OPEN_ERROR, /* Cannot open file */
DLL_WRITE_ERROR, /* File write error */
DLL_READ_ERROR, /* File read error */
DLL_NOT_MODIFIED, /* Unmodified list */
DLL_NULL_FUNCTION /* NULL function pointer */
} DLL_Return;
typedef enum
{
DLL_FALSE,
DLL_TRUE,
} DLL_Boolean;
接下来是对 API 中所有函数的简短描述。不可能在一篇像这样的短文中描述函数是如何调用的以及它们各自返回什么的所有复杂细节。有关此信息,请参阅发行版中的文档和源代码。
首先我们需要创建一个列表指针。
List *listname = NULL;
要创建顶层结构,请执行以下函数
List *DLL_CreateList(List **name);创建此结构后,需要使用下一个函数进行初始化
DLL_Return DLL_InitializeList(List *list, size_t infosize);就这样——DLL 的一个实例已准备好工作;但是,这个组中还有一个最后的函数,当我们想要永久删除列表和顶层结构时使用它。
void DLL_DestroyList(List **name);再次注意指向指针的表示法;这是用来使 name 可以作为 NULL 指针返回。C 标准函数 free 不设置指针;它在释放其内存后传递给 NULL。如果该指针不小心被重用,这可能会导致问题。
我编写了一个初始化序列的模板(参见 列表 1)。这个模板和发行版中的源代码应该有助于使用 DLL。
下一个函数测试顶层结构中的指针,以确定列表中是否有任何节点。
DLL_Boolean DLL_IsListEmpty(List *list);
随后的这个函数的逆函数,创建一个新节点,以查看是否有足够的内存用于新节点。如果有足够的内存,则临时节点被释放。
DLL_Boolean DLL_IsListFull(List *list);要获取列表中节点的数量(记录),请使用下一个函数。
unsigned long DLL_GetNumberOfRecords(List *list);
向链表添加新节点的过程可以像您希望的那样容易或复杂。以下函数具有在添加节点时执行插入排序或仅将节点粘贴在末尾的能力。不要让参数列表吓到您;函数原型使它看起来比实际情况更糟糕。
DLL_Return DLL_AddRecord(List *list, Info *info, int (*pFun)(Info *, Info *));
第一个参数是指向顶层结构的指针,这在所有函数中都是相同的。第二个参数是指向您要放入链表中的数据的指针。第三个也是最后一个参数指向您可以编写的可选函数,该函数确定排序标准。
值得回顾一下这个函数应该如何编写,因为它在下面描述的另外两个函数中再次出现。它模拟了 C 标准函数 strcmp 返回其值的方式。事实上,它可以就是那个函数。
int compare(Info *newnode, Info *keylist)
{
return(strcmp(newnode->key_element,
keylist->key_element));
}
更新当前节点(记录)在任何链表实现中都是必须的,并且这个 DLL API 也不例外。
DLL_Return DLL_UpdateCurrentRecord(List *list, Info *record);我们也会想要删除当前记录。
DLL_Return DLL_DeleteCurrentRecord(List *list);该组中的最后一个函数删除整个列表,但不删除顶层结构。
DLL_Return DLL_DeleteEntireList(List *list);
如上所示,顶层结构中有四个指针。我们在这里关注 current 指针。这个指针是 DLL 中所有能力的来源,并在 DLL 的许多函数中使用,以确定要处理什么。
接下来的两个函数将当前指针移动到列表的头部或尾部。
DLL_Return DLL_CurrentPointerToHead(List *list); DLL_Return DLL_CurrentPointerToTail(List *list);
通常,递增或递减指针是必要的
DLL_Return DLL_IncrementCurrentPointer(List *list); DLL_Return DLL_DecrementCurrentPointer(List *list);有时希望存储 current 指针,然后做其他事情,然后再恢复指针。我们在接下来的两个函数中处理这个问题。
DLL_Return DLL_StoreCurrentPointer(List *list);
DLL_Return DLL_RestoreCurrentPointer(List *list);
如果您找不到已存储在链表中的内容,那么拥有链表就没什么用处了。以下函数允许您查找您的数据,并精确指定如何找到该数据。
DLL_Return DLL_FindRecord(List *list, Info *record,
Info *match, int (*pFun)(Info *, Info *));
与往常一样,第一个参数是指向链表的指针。第二个是指向返回数据的指针。第三个是指向匹配标准的指针,最后一个参数是指向先前在数据修改组中描述的 compare 函数的指针。这个比较函数可以以不同的方式构建,但思想是相同的。
现在生活变得有点困难。上面的函数需要知道如何在链表中查找数据。是从头指针向下查找、从尾指针向上查找,还是从当前指针向上或向下查找?我对这个问题的解决方案是使用状态表。
还需要另外两个与状态表相关的 typedef 枚举,一个用于设置搜索的起点,另一个用于设置其方向。
typedef enum
{
DLL_ORIGIN_DEFAULT, /* Use current origin
* setting */
DLL_HEAD, /* Set origin to head pointer */
DLL_CURRENT, /* Set origin to current pointer */
DLL_TAIL /* Set origin to tail pointer */
} DLL_SrchOrigin;
typedef enum
{
DLL_DIRECTION_DEFAULT, /* Use current direction
* setting */
DLL_DOWN, /* Set direction to down */
DLL_UP, /* Set direction to up */
} DLL_SrchDir;
状态表在初始化时默认为 DLL_HEAD 和 DLL_DOWN。DLL_FindRecord 函数在未更改这些值的情况下使用它们。要更改此函数的操作,请使用显示的接下来的两个函数。如果不需要更改这两个函数中的任何一个,请使用 DLL_ORIGIN_DEFAULT 或 DLL_DIRECTION_DEFAULT。第一个函数将表设置为新值
DLL_Return DLL_SetSearchModes(List *list,
DLL_SrchOrigin origin, DLL_SrchDir dir);
第二个函数返回状态表副本的指针到以下结构typedef struct search_modes
{
DLL_SrchOrigin search_origin;
DLL_SrchDir search_dir;
} DLL_SearchModes;
此函数的目的是通过查询状态表来检查后续搜索将如何进行。DLL_Return DLL_GetSearchModes(List *list);本组中的最后一个是三个函数,它们返回与当前指针位置相关的数据。它们不受状态表的影响。
DLL_Return DLL_GetCurrentRecord(List *list,
Info *record);
DLL_Return DLL_GetPriorRecord(List *list,
Info *record);
DLL_Return DLL_GetNextRecord(List *list,
Info *record);
通常,输入和输出函数不会被认为是链表实现的一部分;但是,当使用 ADT 时,它们确实使生活变得更容易。如果没有这些函数,则必须将当前指针设置为列表的头部或尾部,然后重复调用上面提到的 DLL_Get 函数之一。如果在此过程中需要排序,则任务将更加繁琐。
写入磁盘或从磁盘读取往往是非常平台相关的。我努力使接下来的两个函数尽可能通用;它们以二进制模式打开文件,并从头到尾写入或读取 Info 结构。根据您在 Info 结构中输入数据的方式,将决定是否存在字节序问题。
要保存列表,请确定文件的完整路径,然后将其指针传递给下一个函数。此函数没有排序选项,因为列表可能已在内存中排序,并将按该顺序保存。
DLL_Return DLL_SaveList(List *list,
const char *path);
从磁盘加载文件时,您可以选择在文件进入内存时对其进行排序。传递 NULL 会按文件在磁盘上的存在方式加载文件,并且加载速度比列表已排序时更快。
DLL_Return DLL_LoadList(List *list, const char *path, int (*pFun)(Info *, Info *));
简短的答案是,它用于几乎任何类型的数据存储,在这些存储中您不知道要存储多少数据。我一直在研究的一个例子是 3D 图形数据,其中场景中可能存在未知数量的对象。我编写了条形码扫描软件,该软件使用此 DLL 来跟踪所有正在使用的手持终端。我还参与了一个数据库转换程序,该程序将数据读取到一个链表中,允许您对其进行编辑;然后它将数据转换为另一个链表并再次写出。
我将主要集中在编译 Linux 版本;但是,DOS 有两个 Makefile:一个使用 DJGPP GNU 编译器编译,另一个用于 MS6.0 编译器。所有三个 Makefile 都包含在发行版中。如果有人感兴趣,还有一个稍微修改过的 DLL 版本,它使用 Metaware C 编译器在 Big Blues 4690 OS (FlexOS) 上编译(此操作系统用于销售点系统)。
首先,我们需要使用 tar 将文件解压到您想要它们所在的目录中。
tar -xvzf linklist.1.0.0.tar.gz -C /your/path
tar 文件将创建一个名为 linklist 的目录并将所有内容放入其中。接下来,使用 cd 移动到 linklist 目录并键入以下命令之一,假设您正在使用 GNU 编译器
make创建一个共享库,或
make static创建一个静态库。
要将库安装到 /usr/local/lib 目录中,请输入 make install 或 make install-static。
这就是全部。您现在可以开始编写代码了。
Carl J. Nobile 目前编写销售点软件,并且是纽约 Genovese Drug Stores 的 AIX Unix 系统的管理员。在家中,他正在开发一个程序,该程序可以使用 Buckminster Fuller 的 Synergetics 中的想法来设计测地线房屋。可以通过电子邮件 cnobile@suffolk.lib.ny.us 与他联系。

{kind=link}