
Javalanche:雪崩预测器
Javalanche 是一个原型,目前的模型过于稀疏和幼稚,无法用于实际的雪崩预测。然而,它表明,在显著增强此处提出的模型后,模糊逻辑可能是一种适用于此类应用的工具。该软件使用 Java 在 Debian/GNU Linux 环境中开发。图表是使用 gnuplot 创建的。
评估雪崩危险性依赖于从大量变量中收集有意义的数据,这些变量包括坡向和坡度角、风载和风向、地形粗糙度、积雪中存在的雪晶形态、积雪层阻力、强弱区域的层叠效应、当前温度和温度历史,以及最近的降雪深度和含水量。值得注意的是,任何可用的模型都应包含长期和当前变量,某些因素是相互关联的,并且某个因素可能在某个特定时间发挥主导作用,也可能不发挥主导作用。
为了实用,输入变量的值应该相对容易在从驯服的滑雪区到未驯服的荒野等环境中测量。许多典型的评估工具都是定性的,但已被证明其价值。可以通过挖掘雪坑并检查坑壁的雪晶形态、温度和层阻力来评估雪层。评估雪层阻力的常用方法是手测试,该测试测量雪层对穿透的阻力水平。这些级别按阻力递增的顺序分为拳头、四指、一指、铅笔和刀。这有助于确定是否存在潜在的埋藏不稳定因素。评估可以被风输送的表面积雪量的一种技术是脚穿透测试。测试者用一只脚踩在雪地上并测量穿透深度,30厘米被认为足以表明潜在的危险。一种改进方法是尝试将测试者的体重和脚部面积考虑在内。还有其他此类测试。坡向是斜坡所朝向的罗盘方向。其危险效应将受到风向和阳光照射的影响。后者的影响随一年中的时间而变化。一个与这些问题相关的优秀网站,其中包含指向其他网站的链接,是网络空间冰雪和雪崩中心,网址为 http://www.csac.org/。
最重要的是,一个合理有用的模型将采用许多变量,需要大量的测试和改进,并且需要经验丰富的雪崩人员的大量投入。显然,在发达的滑雪区应用该模型比在偏远地区更容易。我们所知的计算机模型本质上是机械的,例如,有欧洲的工作使用有限元分析。我们认为模糊逻辑是一种合适的工具,并发表本文来解释这种方法。我们在一开始就强调,本文是阐述性的,所提出的模型在实际环境中尚不可用。然而,我们将通过一次添加一个新变量并测试生成的软件来开发一个成熟的模型。此外,我们甚至没有选择最重要的变量,而是选择了一些容易理解的变量。
描述模糊逻辑的文章和书籍随处可见,只需进行粗略的网络搜索即可快速确认。我们推荐 Earl Cox 的书作为首次实践接触(模糊系统手册,AP Professional,1994)。模糊逻辑最初由 Lotfi Zadeh 提出(“模糊集”,信息与控制,第 8 卷,338-353,1965),最著名的是其在工业控制中的应用。然而,它也成功地应用于决策应用,这正是我们项目的基础。
模糊逻辑特别适用于数学模型不可用或过于笨拙,并且可以获得从经验中收集并得到直觉支持的人类专业知识的情况。特别是,它模拟了人类的推理过程,并在其建模过程中采用了语言形式。对于本文,第一作者是模糊逻辑程序员,第二作者提供雪崩专业知识。
在本文中,我们将通过我们的问题空间介绍模糊逻辑。这种方法将通过一个稍微详细的示例应用,让您深入了解这些概念。然而,本文的篇幅不允许我们正式地或充分地展示模糊逻辑。
模糊逻辑模型的最小成分包括以下要素
一个或多个输入变量
每个输入变量的模糊集族
一个或多个输出变量
每个输出变量的模糊集族
连接输入和输出变量的一组规则
还有一些应用于模型的算法
清晰输入变量的模糊化
规则的应用
规则结果的去模糊化以获得清晰输出
该模型将在过去 24 小时内有降雪时应用。有三个输入变量
Slope_Pitch,疑似雪崩危险区域的平均坡度角(度)
Water_Equiv,降雪的含水量(厘米当量水)
Current_Temp,当前温度(摄氏度)
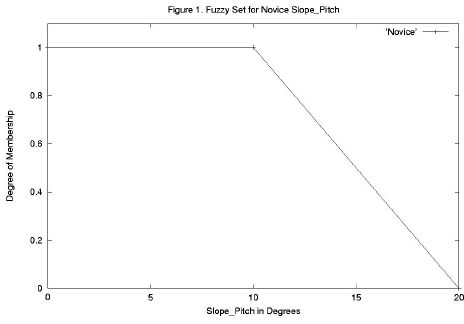
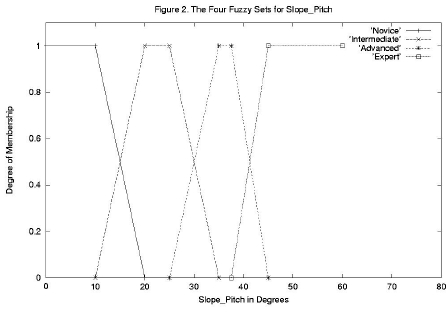
为了介绍模糊集,我们将从输入变量 Slope_Pitch 开始。当然,野外的斜坡坡度并非恒定,即使是平均坡度的测量也是近似的。15.2 度和 17.3 度这样的数字之间的区别是否真的那么有用也不清楚。模糊集提供了一种将这种固有的模糊性融入模型的方法。我们根据熟练驾驭地形所需的相应滑雪能力,将 Slope_Pitch 变量大致分为四类:新手、中级、高级和专家。
对于这些术语,没有广泛接受的滑雪行业标准,但对其含义存在大致的共识。例如,大多数滑雪者会将 0 到 10 度的坡度范围视为新手级,但在斜坡不再被认为是新手级,而是中级级的角度上,共识会减少。模糊逻辑将通过定义新手坡度角的模糊集来适应这种不确定性,如图 1 所示,其中纵轴称为隶属度 (dom)。在图 2 中,中级、高级和专家的模糊集也已纳入。查看图 2,17.5 度的输入 Slope_Pitch 在新手类别中的隶属度为 0.25,在中级类别中的隶属度为 0.75,反映了从新手到中级 Slope_Pitch 的模糊过渡。确定各种输入值的 dom 称为模糊化过程。
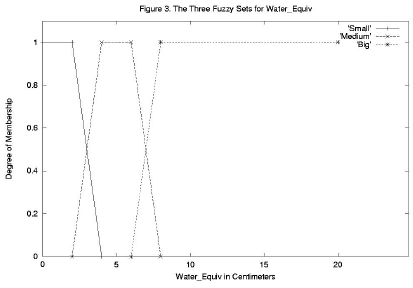
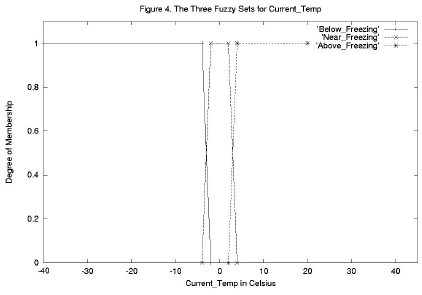
图 3 和图 4 显示了其他两个输入变量 Water_Equiv 和 Current_Temp 的模糊集选择。模糊集范围和形状的选择在某种程度上是任意的,但应以专家的知识为指导。从图 2、3 和 4 中,我们看到该模型具有以下集合
Slope_Pitch 的四个模糊集
Water_Equiv 的三个模糊集
Current_Temp 的三个模糊集
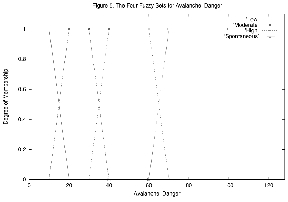
只有一个输出变量,Avalanche_Danger。它的范围从 0 到 100。很容易将其解释为雪崩的概率,但在目前的开发阶段,它只是一个任意的尺度。如果该模型得到显著增强,然后得到广泛而成功的应用,则可以校准此参数,并且可能很像概率。图 5 描绘了 Avalanche_Danger 的四个模糊集类别。
请注意,程序员必须咨询雪地科学家专家来构建模糊集。可以预期,随着模型经验的积累,这些模糊集会进行修改,并纳入额外的输入。
规则分为条件型和非条件型两种。对于 Javalanche,目前仅实施了条件规则。一个典型的规则可能是“如果 Water_Equiv 为小 AND Slope_Pitch 为新手 AND Current_Temp 低于冰点,则 Avalanche_Danger 为低”。规则的 if 子句(前件)包含输入模糊集,而 then 子句(后件)包含输出模糊集。此处的每个规则都使用“AND”连词将前件中的三个模糊集链接起来。每个后件都涉及单个输出模糊集。


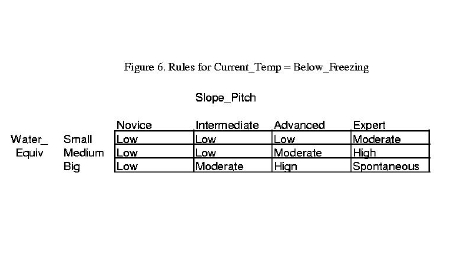
回想一下,三个输入变量的模糊集的多样性分别为 4、3 和 3,因此规则总数为三者的乘积,即 36。我们没有引用 36 条规则中的每一条,而是用图 6、7 和 8 中所示的三个表来表示它们。从表格中提取规则非常简单。表格条目显示了两个输入 Water_Equiv(行)和 Slope_Pitch(列)的 Avalanche_Danger,而第三个输入包含在图例中。例如,在图 6 中,左上角的条目是“低”,相应的输入是
Water_Equiv = 小(行)
Slope_Pitch = 新手(列)
Current_Temp = 低于冰点(图 6 的标签)
因此,相关的规则是“如果 Water_Equiv 为小 AND Slope_Pitch 为新手 AND Current_Temp 低于冰点,则 Avalanche_Danger 为低”;与前面引用的规则相同。
与模糊集一样,程序员必须咨询雪地科学家专家才能编写足够的规则。与模糊集一样,在现实世界中应用模型的经验很可能会导致规则的调整。
为了了解模糊逻辑算法的工作原理,我们将进行示例计算。当然,这些计算是由程序完成的,但手动计算对于理解和调试程序至关重要。我们将经历的步骤是
从三个清晰的输入值开始。
模糊化这三个值。
评估 36 个可用规则中的适当规则,获得模糊输出。
去模糊化输出以获得清晰的输出。
假设我们已测量/估计了三个输入变量,分别为 Slope_Pitch = 17 度、Water_Equiv = 5 厘米和 Current_Temp = 3 摄氏度。这些是清晰的值。
模糊化输入变量意味着找到其在所有模糊集中的 dom。使用图 2,我们发现 Slope_Pitch 在其模糊集中具有以下 dom
新手 dom = 0.3
中级 dom = 0.7
高级 dom = 0.0
专家 dom = 0.0
同样,从图 3 中,Water_Equiv 值为
小 dom = 0.0
中 dom = 1.0
大 dom = 0.0
低于冰点 dom = 0.0
接近冰点 dom = 0.5
高于冰点 dom = 0.5
模糊化后,评估规则。并非所有规则都适用于每种情况。特别是,如果三个输入中的任何一个的 dom = 0.0,则该规则不适用。从前面的 dom 计算中,我们看到 Slope_Pitch 的两个模糊集、Water_Equiv 的一个模糊集和 Current_Temp 的两个模糊集具有非零 dom 值。因此,四个(= 2x1x2)规则适用;即图 7 中间行的前两个规则和图 8 中间行的前两个规则。
我们将继续我们的示例计算,仅评估四个规则中的一个。让我们考虑后果为中等雪崩危险的规则,来自图 7:“如果 Water_Equiv 为中 AND Slope_Pitch 为中级 AND Current_Temp 接近冰点,则 Avalanche_Danger 为中等。”
为了评估此规则,我们通过形成其乘积来组合前件模糊集的 dom
Slope_Pitch 具有中级 dom = 0.7
Water_Equiv 具有中 dom = 1.0
Current_Temp 具有接近冰点 dom = 0.5
然后将乘积 = 0.35 分配给输出,即 Avalanche_Danger 值在中等模糊输出集中具有 0.35 的 dom。使用 dom 的乘积来组合由 AND 连词连接的模糊集称为“乘积 AND”。模糊逻辑允许其他选择(参见 Cox 的书)。
在我们的示例中适用的其他三个规则也必须进行评估。我们不会在此处进行这些计算——它们与第一个规则的评估非常相似。请注意,在适用的四个规则中,两个规则的结果为中等,两个规则的结果为低。我们选择通过将低模糊集的 dom 值相加来组合它们,从而使每个触发的规则都产生影响。我们对中等 dom 执行相同的操作。这在决策问题中经常这样做,但不是唯一可能的选择(同样,参见 Cox 的书)。因此,我们现在具有 Avalanche_Danger 的这些 dom 值
低 = 0.3
中等 = 0.7
高 = 0.0
自发 = 0.0
然后对这些 dom 值进行“去模糊化”,如图 5 所示。在查看具有这些 dom 值的图形后,似乎可以合理地得出结论,结果数字将在 10.0 到 20.0 之间,并且由于中等 dom 更强,因此它应该更接近 20.0 而不是 10.0。在实践中,我们使用称为“重心”的加权平均值,在本例中,它产生 19.0。我们不会在此处进行详细计算。
因此,对于我们的示例计算,Slope_Pitch = 17 度、Water_Equiv = 5 厘米和 Current_Temp = 3 的输入值导致 Avalanche_Danger = 19.0 的输出值,该值主要处于中等区域,但在低区域中也有一定的隶属度。
该软件可通过匿名 FTP 从 ftp://turing.sirti.org/pub/ras/fuz3.tar.gz 获取。解压并解档后,它将生成一个目录树,其中 fuz3 为顶层节点。顶层节点包含一个 README 文件,使用户能够使用和修改该软件包。要执行该软件,假定用户的机器已正确安装 Java。我们使用了 JDK1.1.1。
在最低的子目录 io_n_sets 中,三个文件包含为模型选择的基本类,如下所示
ioput.java 包含输入和输出变量的类。
fz_set.java 包含模糊集的类。
cond_rule 包含条件规则的类。
这些类不包含特定于雪崩预测模型的信息。
io_n_sets 的父目录是 init_n_run,其中包含两个感兴趣的源文件:make_init_file.java 和 run_eng.java。第一个文件创建初始化文件 fz_init.dat,run_eng.java 读取该文件以初始化其模糊逻辑“引擎”。只有 make_init_file.java 包含雪崩预测器的模型。因此,可以对其进行修改,以将该软件应用于其他决策问题。正如预期的那样,run_eng.java 在初始化自身后,会请求用户选择输入变量,然后运行模糊逻辑引擎并生成输出结果。
可以通过在 X Window 系统环境中的终端窗口中输入命令来执行该软件
appletviewer run_eng.html
在此,我们讨论两个主题作为可能的改进
改进和扩展 Javalanche 应用程序
用用户语言和翻译器替换 make_init_file.java
为了改进和扩展 Javalanche 应用程序,将需要活跃的雪崩控制小组进行现场测试和模型改进/增强。本文的较早部分确定了我们将研究的各种其他重要输入参数。即使这被证明不可行,我们仍然相信我们已经为在雪崩预测中使用模糊逻辑提供了依据。
使用 make_init_file.java 的方法用于隔离/模块化特定应用程序,但对用户不友好。一种更可取的方法是允许用户使用简单的编辑器来创建包含特定于应用程序详细信息的文本文件。这需要用专门为此目的设计的语言(用户特定语言)编写。然后将其通过翻译器运行,翻译器的输出是一个初始化文件,在功能上类似于 fz_init.dat。翻译器可以提供 make_init_file.dat 未提供的非常重要的功能。特别是,翻译器将检查用户编写的文本文件中是否存在任何本质上不是运行时错误的错误。然后,雪崩控制小组可以使用它,他们的人员无需成为程序员,只需学习基于他们熟悉的术语的描述性文本建模系统即可。
翻译器还可以生成第二组文件,这些文件适用于生成用户模糊集的图形视图(例如,使用 gnuplot)。翻译器的设计、实施和测试很可能被分配为东华盛顿大学编译器设计课程学生的家庭作业项目。可以使用 Linux 中提供的编译器构建工具 flex 和 bison 以直接的方式完成此任务。现在可能也有成熟的这些工具的 Java 版本,可用于 Linux。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}