
Python HTMLgen 模块
本文介绍如何使用 HTMLgen,一个用于生成 HTML 的 Python 类库。Python 是一种面向对象的脚本语言,大多数 Linux 发行版都附带它。它在 Caldera 和 Red Hat 等发行版的配置和管理中起着重要作用。HTMLgen 是一个附加的 Python 模块,由 Robin Friedrich 编写,可从 http://starship.python.net/lib.html 获取,采用 BSD 风格的免费软件许可证。
HTMLgen 提供了类来支持所有标准的 HTML 3.2 标签和属性。它可以用于任何需要动态生成 HTML 的情况。例如,您可能希望将数据库查询结果格式化为 HTML 表格,或者生成为每个客户定制的 HTML 订单表单。
我将通过使用 HTMLgen 格式化在典型 Linux 系统上找到的数据来介绍它。我认为这些示例足够简单明了,任何熟悉 HTML 和脚本编写的人都可以理解,而无需事先了解 Python。只需记住,在 Python 中,语句块通过代码缩进表示——没有 begin/end 语句,也没有花括号。(在 Python 中,所见即所得适用。)除此之外,Python 代码看起来很像任何主流编程语言中的代码。
虽然 Perl 是最常用的 Web 脚本语言,但我个人更喜欢 Python。它可以实现类似于 Perl 的结果,并且我认为 Python 的语法,加上其用户社区建立的风格,可以带来更简洁、更简单的编码风格。这在开发和维护过程中都是一个优势。这些相同的优势为新手提供了更平缓的学习曲线。Python 在一定程度上远离了传统的脚本语言,而更接近非脚本的、过程式的编程语言。这使得 Python 脚本能够很好地扩展。当一小组脚本开始增长到完整的应用程序系统的大小时,该语言将支持这种转变。
任何需要 HTMLgen 的 Python 程序都必须将其作为模块导入。从 bash 开始,以下是我如何设置和导入 HTMLgen 以创建一个 “Hello World” 网页
bash$ export PYTHONPATH=/local/HTMLgen:$PYTHONPATH bash$ python >>> import HTMLgen >>> doc = HTMLgen.SimpleDocument(title="Hello") >>> doc.append(HTMLgen.Heading(1, "Hello World")) >>> print doc
首先,我设置 PYTHONPATH 以包含可以找到 HTMLgen.py 模块的目录。然后,我启动 Python 解释器并使用其命令行界面导入 HTMLgen 模块。我创建一个名为 doc 的文档对象,并向其添加一个标题。
最后,我打印 doc 对象,它会将以下 HTML 转储到标准输出
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2//EN"> <HTML> <!-- This file generated using HTMLgen module. --> <HEAD> <META NAME="GENERATOR" CONTENT="HTMLgen 2.0.6"> <TITLE>Hello World</TITLE> </HEAD> <BODY> <H1>Hello World</H1> </BODY> </HTML>
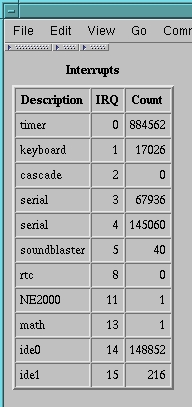
这是一个开始,虽然不是一个令人兴奋的开始。HTMLgen 是一个非常好的用于生成 HTML 表格和列表的工具。图 1 中的表格是由 清单 1 中的 Python 脚本创建的。表格中的数据来自 Linux /proc/interrupts 文件,该文件详细说明了您的 Linux PC 的 IRQ 中断。在我的 PC 上,执行 cat /proc/interrupts 会产生
0: 2348528 timer 1: 42481 keyboard 2: 0 cascade 3: 47735 + serial 4: 75428 + serial 5: 48 soundblaster 8: 0 + rtc 11: 1 NE2000 13: 1 math error 14: 175816 + ide0 15: 216 + ide1
Python 脚本读取 /proc/interrupts 文件的内容,并将数据复制到 HTML 表格中。我将逐步描述这个过程。与前面的示例一样,我首先创建一个简单的文档。然后,我向文档添加一个 HTMLgen 表格
table = HTMLgen.Table( tabletitle='Interrupts', border=2, width=100, cell_align"right", heading=[ "Description", "IRQ", "Count" ]) doc.append(table)在创建表格对象时,我通过将一些可选属性作为命名参数提供来设置它们。最后的 headings 参数设置 HTMLgen 将使用的列标题列表。以上所有参数都是可选的。
设置好表格后,我打开 /proc/interrupts 文件并使用 readlines 方法读取其全部内容。我使用 for 循环遍历返回的行,并将它们转换为表格行。在循环内部,使用字符串和正则表达式函数来去除前导空格,并根据空格和冒号 (:) 分隔符将每一行拆分为包含三个数据值的列表
data=regsub.split(string.strip(line),'[ :+]+')
数据列表的元素经过处理,通过将它们重新排序为一个新的三元素列表(包含名称、编号和总调用次数)来形成表格行
[ HTMLgen.Text(data[2]), data[0], data[1] ]外部的方括号构造一个由逗号分隔的参数组成的列表。第一个列表元素 data[2] 是中断名称。中断名称是一个非数字字段,所以我采取了预防措施,通过 HTMLgen Text 过滤器转义任何可能对 HTML 特殊的字符。生成的列表通过将该列表附加到表格的主体中而成为表格的一行
table.body.append(
[ HTMLgen.Text(data[2]), data[0], data[1] ])
最后,一旦所有行都被处理完毕,文档将被写入 interrupts.html。结果如图 1 所示。简单的 Table 类旨在显示数据行,例如可能从数据库查询返回的数据行。对于更复杂的表格,TableLite 对象提供了更低级别的表格构建工具,其中包括进行单独的行/列自定义、列/行跨越和嵌套表格的能力。
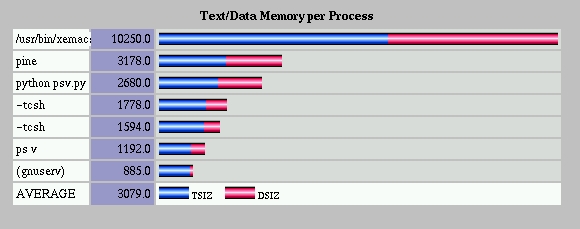
表格功能也已扩展到创建精美的条形图。图 2 显示了我从 Linux ps 命令的输出生成的条形图。该图表由 HTMLgen 条形图模块创建。psv.py 的代码是 清单 2 中显示的 20 行 Python 代码。ps v 的原始输出看起来像下面这样
PID TTY STAT TIME PAGEIN TSIZ DSIZ RSS LIM %MEM COMMA 555 p1 S 0:01 232 237 1166 664 xx 2.1 -tcsh 1249 p2 S 0:00 424 514 2613 1676 xx 5.4 xv ps ...
我使用 Python 操作系统模块的 popen 函数为命令的输出流返回一个文件输入管道
inpipe = os.popen("ps vax", "r");
然后,我从输入管道中读取第一行,并将其拆分为列名列表。colnames = string.split(inpipe.readline())现在,我创建图表对象和图表对象的数据列表对象
chart = barchart.StackedBarChart() ... chart.datalist = barchart.DataList()数据列表可以为每个条形图拥有多个数据段,这会导致堆叠条形图,如图 2 所示。我需要通过设置 segment_names 列表来告诉数据列表对象存在多少个数据段。我决定我的图表上的条形图将有两个段,一个用于 TSIZ(程序文本内存大小),另一个用于 DSIZ(程序数据内存大小)。为了实现这一点,我需要将两个列名从 colnames 复制到 segment_names。由于 Python 中的列表从零开始编号,因此我感兴趣的两个 colnames 列是第 5 列 (TSIZ) 和第 6 列 (DSIZ)。我可以使用单个切片语句从 colnames 列表中提取它们
chart.datalist.segment_names = colnames[5:7] data = chart.datalist[5:7] 表示法是一种切片表示法。在 Python 中,您可以从字符串、列表和其他序列数据类型中切片出单个项目和项目范围。表示法 [low:high] 表示从 low 到 high 减 1 切片出一个新列表。在第二行中,我将名为 “data” 的变量分配给变量 “chart.datalist”,以缩短以下行的长度,使其适合Linux Journal 中所需的列宽。
初始化图表后,我使用 for 循环从 ps 输出管道中读取剩余的行。我通过使用 string.split(line) 将行分解为列列表来提取我需要的列。我通过从第 10 列开始获取所有单词并将它们连接成一个新的 barname 字符串来提取每个命令的文本
barname = string.join(cols[10:], " " )
我使用 string 模块的 atoi 函数将数字字段中的 ASCII 字符串转换为整数。循环中的最后一个语句将数据组装成一个元组
( barname, tsize, dsize )元组是一种 Python 结构,很像列表,只是元组是不可变的——您无法从元组中插入或删除元素。尽管两者相似,但它们的差异导致了非常不同的实现效率。Python 既有元组又有列表,因为这允许程序员选择最适合情况的一个。Python 及其模块的许多功能都旨在成为服务的更高级别接口,然后这些服务在编译语言(如 C)中高效实现。这允许 Python 用于使用 OpenGL 的计算机图形编程以及使用快速数值库的数值编程。
回到示例。循环中的最后一个语句将元组插入到图表的数据列表中。
data.load_tuple(( barname, tsize, dsize ))
当最后一行被处理后,循环终止,我按 TSIZ 的降序对数据进行排序
data.sort(key=colnames[5], direction="decreasing")之后,我创建最终文档并将其保存到文件中。
doc = HTMLgen.SimpleDocument(title='Memory')
doc.append(chart)
doc.write("psv.html")
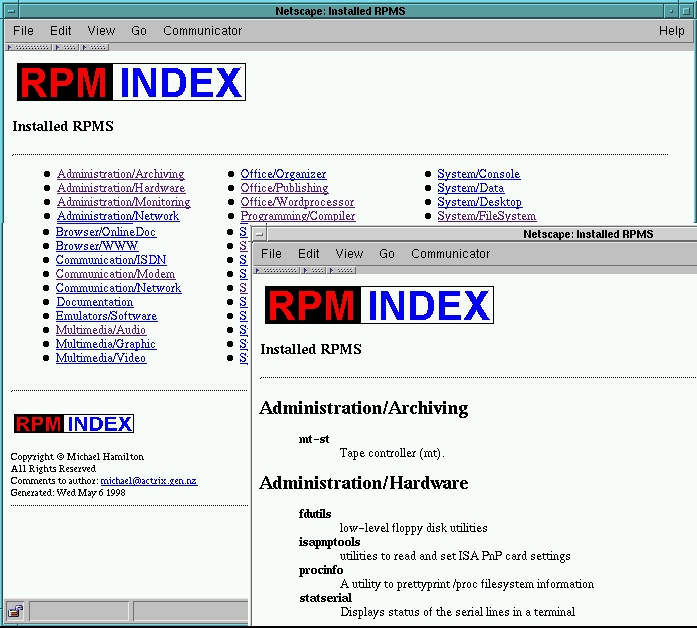
将 psv.html 加载到浏览器中会得到如图 2 所示的图表。通过更改条形图的参数,例如用于图表的“原子”的 GIF,我可以构建不同样式的图表。在我的下一个示例中,我将向您展示如何处理数据流以生成一系列相互链接的文档。清单 3 中的脚本创建一组两个文档,总结了 Linux 系统上安装的所有 Red Hat 软件包。生成的 HTML 页面如图 3 所示。索引文档总结了 RPM 主要组,第二个主文档总结了每个组中的 RPM。索引文档中每个组的链接直接跳转到主文档中每个组的条目。
HTML 是从以下 rpm 命令的输出生成的
rpm -q -a --queryformat \
'%{group} %{name} %{summary}\n'
输出通常如下所示
System/Base sh-utils GNU shell utilities. Browser/WWW lynx tty WWW browser Programming/Tools make GNU Make. System/Library xpm X11 Pixmap Library System/Shell pdksh Public Domain Korn Shell我将此输出读取到 Python 列表中,并通过按字母顺序对其进行排序来预处理它。
我使用 HTMLgen 的 SeriesDocument 生成两个文档,一个索引文档 (idoc) 和一个主文档 (mdoc),使两个文档具有相同的外观和风格。通过使用 SeriesDocument,我可以通过 rcfile 和其他可选参数配置标准文档标头、页脚和导航按钮。
索引文档 (idoc) 只有一个 HTMLgen 组件:RPM 组的 HTML 列表。我使用了 HTMLgen.List columns 选项来创建一个多列列表
ilist = HTMLgen.List(style="compact", columns=3) idoc.append(ilist)
for 循环处理来自 rpm 命令的每一行,并生成 idoc 和 mdoc 文本。每次组名更改时,我都会向 ilist 添加一个新的列表条目
if group != lastgroup:
lastgroup = group
title = HTMLgen.Text(group)
href = HTMLgen.Href(mainfile+"#"+ group,
title)
index.append(href)
我将列表文本包装在 HTML 命名 HREF 中,将其链接回 mdoc。我使用主文件名和组标题来形成 HREF 链接。例如,对于 “Browser/FTP” RPM 组,我的代码将生成以下 HREF 链接<A HREF="rpmlist.html#Browser/FTP">Browser/FTP</A>主文档 (mdoc) 具有更复杂的结构。它由一系列 HTML 定义列表组成,每个 RPM 组一个。每次组名更改时,我都会生成命名锚点,该锚点是上面生成的引用的目标
anchor = HTMLgen.Name(group, title)我将锚点作为新的组标题附加到 mdoc
mdoc.append(HTMLgen.Heading(2, anchor))对于 “Browser/FTP” 组,这将生成以下 HTML
<H2><A NAME="Browser/FTP">Browser/FTP</A></H2>一旦组标题被附加,我就开始一个组中的 RPM 列表
grplist = HTMLgen.DefinitionList()一旦新的组列表启动,我的 for 循环将继续将 RPM 摘要附加到 mdoc,直到下一个组名发生更改
grplist.append( (HTMLgen.Text(name),HTMLgen.Text(summary)))当整个 rpmlist 被处理完毕后,我生成您在图 3 中看到的两个文档。
在这个例子中,我同时生成了两个简单的文档,并将一个文档链接到另一个文档。这个例子可以很容易地扩展,以便为每个 RPM 提供进一步的链接到单独的文档,并从每个 RPM 链接到它所依赖的 RPM。
我只是浅尝辄止地介绍了 HTMLgen 和 Python 的可能性。我没有涵盖 HTML 表单、图像地图、嵌套表格、框架或 Netscape 脚本的 HTMLgen 对象。我也还没用过 Python 的面向对象特性。例如,我可以对一些 HTMLgen 对象进行子类化,以针对每个应用程序的特定性进行自定义。我没有讨论用于 CGI 处理的 Python 模块。您可以通过将浏览器指向本文随附的一些参考资料(请参阅“资源”)来阅读有关这些主题的更多信息。
如果您正尝试开始使用 HTMLgen,则 HTMLgen 附带的 HTMLtest.py 文件提供了一些很好的示例。HTMLgen 文档相当不错,尽管在某些情况下,更多的示例会有所帮助。我不认为我的示例需要任何特定的 Linux 发行版、libc 或 Python。所有这些都是使用 HTMLgen 2.0 和 Python 1.4 在 Caldera OpenLinux Standard 1.2 版本上编写的。


{kind=link}
{kind=link}
{kind=link}