
NIST 的 Linux 集群
美国国家标准与技术研究院 (NIST) 正在试验基于商用个人计算机和局域网技术的集群。集群项目的实验阶段的目的是确定使用商用集群来处理 NIST 部分并行计算工作负载的可行性。除了运行顺序代码的 Cray C90 之外,许多并行作业还在 IBM SP2、SGI Origin 2000、SGI Onyx 和 Convex 超级计算机上运行。
构建集群来运行并行作业有几个原因。初始成本低是其中之一,尽管尚不清楚与制造商支持的传统封装系统相比,与集群相关的长期成本如何。另一个原因是系统的可用性。在不需要等待的情况下拥有一个较慢的系统有时比等待很长时间才能访问更快的系统更好。第三个原因是并行虚拟机 (PVM) 和消息传递接口 (MPI) 环境的免费实现在 Linux 上可用。许多 NIST 并行应用程序依赖于 PVM 或 MPI。
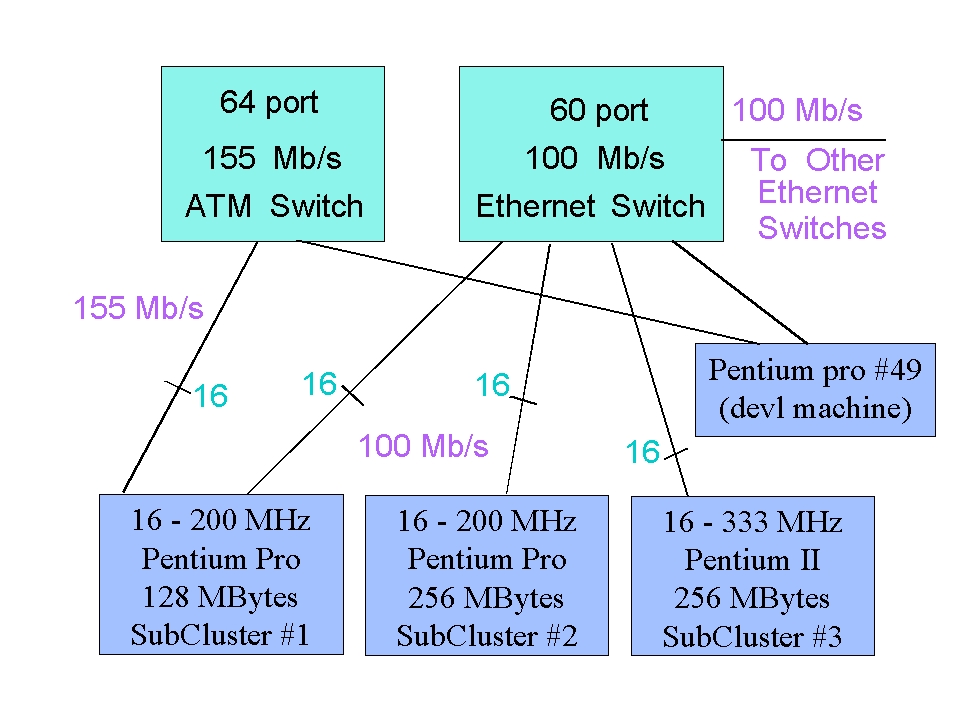
图 1 显示了当前集群的示意图。目前,集群中有 48 台机器(节点);32 个节点配备了 200 MHz Pentium-Pro 微处理器,16 个节点配备了 333 MHz Pentium II 微处理器。Pentium-Pro 机器围绕 Intel VS440FX (Venus) 主板构建,该主板使用 33 MHz PCI 总线并具有四个 SIMM 内存插槽。Pentium II 机器使用基于 Intel 440LX 芯片组的主板,也带有 33 MHz PCI 总线和 3 个 DIMM 内存插槽。所有节点都配置了单个 2.1GB 硬盘,支持 512MB 的交换空间和文件系统。16 个节点具有 128MB 内存,32 个节点具有 256MB 内存,总内存容量为 10GB。
集群机器中的 16 台同时通过快速以太网和 ATM 连接。其余 32 台机器仅通过快速以太网连接。因此,根据要运行的作业的要求,集群可以配置最多 48 个快速以太网节点或最多 16 个 ATM 节点。另一台 Pentium-Pro 机器用作集群的管理前端。这台机器同时具有快速以太网和 ATM 接口。
ATM 接口卡是带有 512KB 板载内存的 Efficient Networks ENI-155p。这些节点通过 OC-3 (155Mbps) 使用多模光纤连接到 Fore ASX-1000 交换机。对于快速以太网,我们使用 SMC EtherPower 10/100 和 Intel EtherExpress 100+ 卡连接到一个以太网交换机:一个带有 60 个快速以太网端口的 N-Base MegaSwitch 5000。到交换机的布线使用 5 类双绞线电缆完成。以太网交换机通过 100Mbps 上行链路连接到路由器,从而连接到 NIST 内部网络。ATM 和快速以太网接口都配置到不同的子网中,允许我们独立监控网络流量。集群子网上几乎没有后台流量,因为节点仅用于并行应用程序。在评估集群网络时,将非计算网络流量保持在最低限度非常重要。
集群节点已使用 NIST 开发的 MultiKron 性能测量仪器进行了增强(参见资源 6 和 7)。MultiKron PCI 板配备了 MultiKron VLSI 芯片、高精度时钟和 16MB 内存。这些功能允许精确的时间间隔测量和跟踪数据存储,且扰动很小。MultiKron 的另一个优点是,多个板(目前最多 16 个)上的时钟可以时间同步,从而可以以 25 纳秒的分辨率跟踪集群中的事件。这种类型的测量对于精确跟踪网络事件非常重要。
32 个仅支持快速以太网的集群节点正在运行 Linux 内核版本 2.0.29。我们发现此版本对于我们的配置最稳定。但是,由于此内核版本中不支持 Intel EtherExpress 100+,因此设备驱动程序构建为模块。16 个 ATM/以太网节点使用 Linux 内核 2.1.79,因为 ATM 软件的当前版本需要此版本。
ATM 软件的开发和支持来自瑞士联邦理工学院 (EPFL) 的 Werner Almesberger 运行的 Linux-ATM 项目。(参见资源 2。)我们目前正在运行此软件的 0.34 版本,之前从 0.26 版本开始。
我们在集群上安装了局域网多计算机 (LAM)(MPI 的一种实现)版本 6.1 和并行虚拟机 (PVM) 版本 3.10,以便运行我们的基准测试以及 NIST 并行作业。
我们还开发了一个设备驱动程序,以允许用户模式程序控制 Intel Pentium-Pro 和 Pentium II 处理器中存在的性能计数器。Intel Pentium-Pro 架构中存在两个性能计数器以及一个时间戳计数器。每个计数器都可以配置为计数多个事件之一,例如缓存提取和指令执行。(参见资源 3。)由于只有 Linux 内核才能写入计数器控制寄存器(和计数器本身),因此需要设备驱动程序。用户模式程序可以直接读取计数器值,而无需承担内核系统调用设备驱动程序的开销。
我们在集群上使用的另一个工具是 S-Check(参见资源 5),由我们小组开发。S-Check 是一种高度自动化的程序灵敏度分析工具。它通过对代码效率进行局部更改并将这些更改与整体程序性能相关联,来预测程序各个部分的改进将如何影响性能。
我们编写了许多小型测试内核来评估集群内通信的性能。我们有在原始套接字、IP 和 LAM/PVM 库级别进行通信的测试内核版本。这些小型内核有助于评估不同通信软件级别的开销。通过使用 MultiKron 工具包,内核可以获得非常精确的网络性能测量结果。
评估集群性能的第一步是确定集群节点在内存带宽方面的性能。内存和总线带宽性能可能会限制网络带宽的有效利用。
我们使用了 NIST 基准测试 memcopy 来确定集群节点的主内存带宽。对于大于缓存大小但小于主内存大小的缓冲区大小,传输的缓冲区大小不影响传输速率。在 200 MHz Pentium-Pro 机器上,我们测得的峰值传输速率为 86MBps (672Mbps)。在 333 MHz Pentium II 机器上,测得的速率为 168MBps。这两个速率都远远超过了 ATM 和以太网网络的线路速度。因此,内存带宽不是利用网络峰值传输速率的因素。
我们使用 netperf(参见资源 4)和我们自己的名为 pingpong 的测试内核来测量网络的吞吐量和延迟。将 pingpong 与 MultiKron 结合使用可以对集群节点之间的延迟进行直接且精确的测量。netperf 用于测量 TCP 和 UDP 性能,而 pingpong 程序的变体用于测量 LAM、TCP、UDP 和 ATM 套接字级别的性能。
使用 netperf 流基准测试来测量吞吐量,我们测得 TCP/IP over ATM 的峰值速率为 133.88Mbps(OC-3 线路速率的 86%)。对于 TCP/IP over Ethernet,我们测得 94.85Mbps(线路速率的 95%)。这两个速率都接近相应网络的最大有效负载速率。
使用 pingpong 程序测量吞吐量可以更深入地了解网络性能。虽然 netperf 结果倾向于产生平滑曲线,但随着消息大小的增加,pingpong 的吞吐量变化更大。对于小于 16KB 的消息,使用 TCP/IP 时,快速以太网的性能优于 ATM。在此消息大小下,快速以太网接近其最大吞吐量,而 ATM 则不然。对于大于 16KB 的消息,ATM 吞吐量增加以超过快速以太网。
在运行吞吐量测试时,我们注意到当消息大小接近 31KB 时,TCP/IP 吞吐量会急剧下降。通过使用 MultiKron 工具包探测 Linux 内核中的网络堆栈,我们能够找到吞吐量下降的原因。对于 Linux 2.0.x 内核,即使接收器窗口已打开以包含段的空间,最后一个消息段的传输也会延迟。我们修改了内核 TCP 软件以防止这种延迟,从而消除了性能下降。(有关详细信息,请参阅 http://www.multikron.nist.gov/scalable/publications.html。)
为了测量消息传输的延迟,我们对参与数据传输的两个集群节点上的同步 MultiKron 时钟进行了采样。延迟是将最小长度的消息从一个节点发送到另一个节点所需的时间。表 1 给出了网络堆栈不同层的测量结果。给出的值是从发送方到接收方的单向时间。因此,TCP/IP 测量值也包括设备驱动程序和交换机时间。同样,设备驱动程序测量值也包括交换机时间。
对于小型消息,ATM 交换机增加的延迟大于快速以太网。但是,随着消息大小的增长,快速以太网交换机增加的延迟也会增加,而 ATM 交换机延迟保持不变。表 2 显示了在使用快速以太网交换机和交叉线发送各种大小的数据包时的应用层延迟。如表所示,交换机增加的延迟在 123 到 131 微秒之间。对于来自不同制造商的多个交换机,这些延迟值是一致的。原因是缓冲每个帧直到完全接收到,而不是仅缓冲标头字节,然后在从帧标头确定目的地后重叠发送和接收。(我们已与一家交换机制造商确认了这一点。)尽管每个数据包的延迟是恒定的,但在突发中,除了第一个数据包之外,所有数据包的延迟都很容易被流水线隐藏。
我们在集群上运行了多个 NIST 应用程序。这些应用程序大多数是计算密集型的,磁盘访问很少。一个例外是下面描述的语音处理作业。
我们的语音处理应用程序是一个批处理作业,从中央服务器零散地提交到每个集群节点。此作业用于处理超过 100 小时的录音语音。处理过程包括分析语音以生成文本翻译。该作业在集群上运行了近三周,几乎没有中断。在 32 个集群节点上,用于处理的总 CPU 时间超过 4200 万秒。每个作业片段在开始计算之前,都会通过网络文件系统 (NFS) 从中央服务器传输 50MB 的数据。Linux NFS 已被证明非常稳定。总共运行了 6464 个子作业作为语音处理应用程序的一部分,成功完成率为 98.85%。
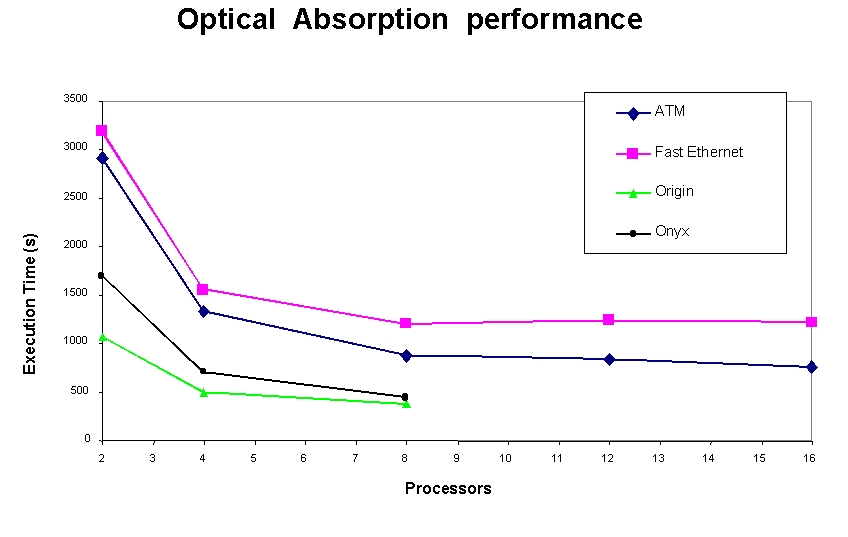
在集群上运行的另一个 NIST 应用程序 OA 通过考虑激子的相互作用来预测各种固体的光学吸收光谱。计算的大部分基于快速傅里叶变换 (FFT)/卷积方法来计算量子力学积分。OA 应用程序在集群以及 Silicon Graphics (SGI) Origin 和 Onyx 系统上运行。图 2 显示了 OA 应用程序在 SGI 和集群系统上的执行时间。最佳运行时间出现在 8 节点 Origin 上,为 500 秒,而 8 节点 ATM 子集群上的运行时间为 900 秒。对于 16 节点 ATM 子集群,运行时间仅略有改善,表明该应用程序在超过 8 个节点时无法很好地扩展。结果显示集群和 Origin 之间此应用程序的性能差异接近两倍,而成本差异超过十倍。与快速以太网网络(运行时间为 1300 秒)相比,使用 ATM 网络运行作业将运行时间缩短了 30%。这种差异是由于通过 ATM 可获得更高的吞吐量。
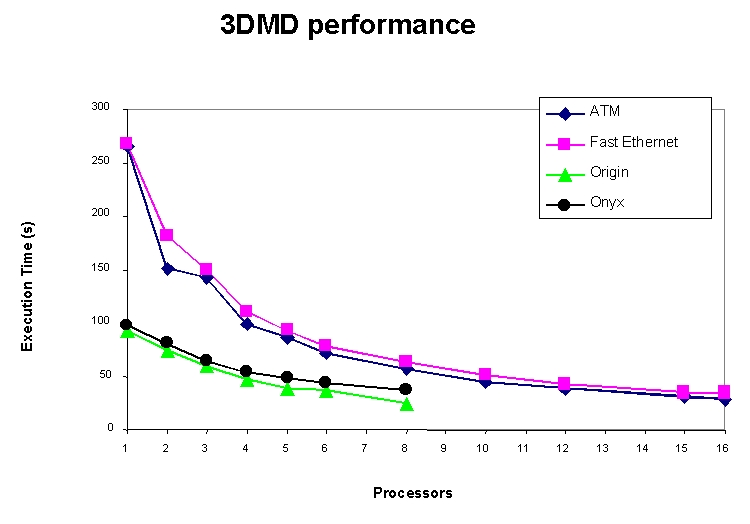
第三个 NIST 应用程序 3DMD 实现了三维矩阵分解算法来求解椭圆偏微分方程。此应用程序被认为是“粗粒度”的,因为它以不频繁的间隔生成大型(100KB 或更大)消息。随着添加更多节点,此应用程序可以很好地扩展。图 3 显示了 3DMD 在 SGI 并行计算机和集群上的执行时间。使用 16 个集群节点,3DMD 的运行速度比 8 个 Origin 节点(Origin 上可用的最大节点数)更快。对于此应用程序,ATM 和快速以太网之间的性能差异为 10%,ATM 性能更好。
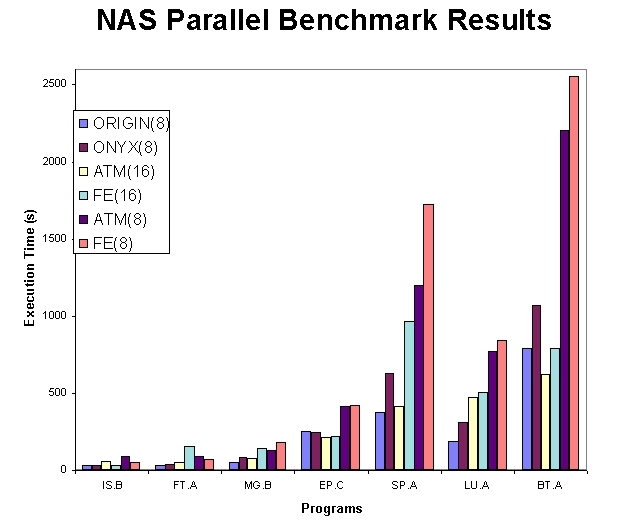
图 4 显示了数值空气动力学模拟 (NAS) 并行基准测试的执行时间(参见资源 8)。NAS 基准测试打包为一组程序,旨在衡量并行计算机在计算密集型航空物理应用程序上的性能。NAS 套件使用 MPI 通信标准(分布式内存)以 FORTRAN 77 编写。该图显示了 NAS 示例问题在 8 节点 SGI Origin、8 节点 SGI Onyx 以及 8 节点和 16 节点集群上使用快速以太网和 ATM 运行时的执行时间。机器名称后面的括号中的数字表示问题运行时使用的处理器数量。集群与传统的并行计算机竞争良好,并且对于多个基准测试,ATM 比快速以太网具有优势。
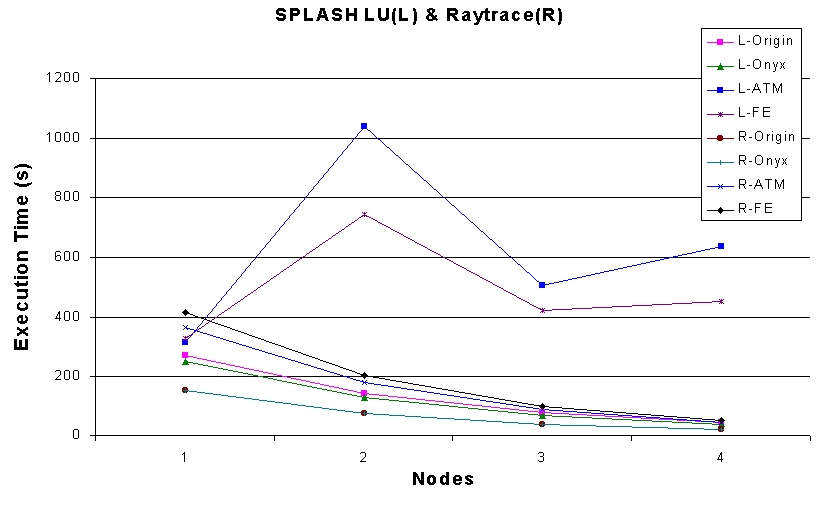
我们运行的第二组基准测试是斯坦福并行共享内存应用程序 (SPLASH)(参见资源 9)。此基准测试套件与 NAS 的不同之处在于 SPLASH 利用共享内存而不是分布式内存。为了在集群上运行 SPLASH 套件,我们使用了 TreadMarks(参见资源 10)分布式共享内存 (DSM) 系统。TreadMarks 通过网络文件系统模拟 DSM。图 5 显示了两个 SPLASH 程序 Raytrace 和 LU 的执行时间。Raytrace 主要由计算组成,通信很少,而 LU 则将很大一部分时间(接近 35%)用于通信。该图显示,对于 Raytrace,集群性能非常好;但是,对于 LU,集群性能无法与并行计算机相媲美。这种性能差距是由于 LU 应用程序在集群上产生的小消息通信开销很高。
图 5. SPLASH LU (L) & Raytrace (R)
运行 NAS、SPLASH 和其他基准测试的目的是了解集群可以有效运行的应用类型。此外,对于类似于 SPLASH LU 的应用程序,其中通信时间是运行时的主要因素,我们需要更深入地研究 Linux 网络软件,并确定如何提高此类应用程序的网络性能。
集群的另一个应用是 Distributed.NET 项目(参见 http://www.distributed.net/)。在活动量低的时期,RC5 加密软件在集群节点上运行。每个节点独立于其他节点运行该软件,因此我们可以使用任意数量的节点参与。我们有时运行所有 48 个节点(加上前端),总密钥处理速率超过每秒 3200 万个密钥。
Linux 在我们的研究中非常有利。PCI MultiKron 卡的第一个设备驱动程序是在 Linux 上完成的,也是最容易编写的。我们使用 Linux 监控集群,我们开发的工具要么首先为 Linux 编写,要么从其他 UNIX 环境快速移植。使用商业操作系统进行计算集群实验将更加困难,因为源代码通常不可用。通过能够探测操作系统源代码,我们能够准确测量操作系统的性能以及应用程序的性能。
我们的实验表明,在运行分布式内存应用程序(通常以大型消息为特征)时,集群与传统的并行计算机竞争非常激烈。对于共享内存应用程序(通常与许多小型消息通信),网络开销会对应用程序性能产生不利影响。对于这两种类型的应用程序,调整网络参数都可以极大地有利于减少执行时间。
333 MHz、16 节点 Pentium-II 集群已转移到生产环境。此集群将提供给整个 NIST 社区,并将由支持传统超级计算机的团队进行管理。我们相信基于 Linux 的集群将为运行许多高性能应用程序提供有效的环境。
Wayne Salamon 是马里兰州盖瑟斯堡国家标准与技术研究院信息技术实验室的计算机科学家。在过去的 12 年中,他一直从事 PC、UNIX 工作站和 IBM 大型机的系统软件工作。他目前的研究兴趣是并行计算和性能测量。可以通过 wsalamon@nist.gov 联系 Wayne。
Alan Mink 是 NIST 信息技术实验室分布式系统技术项目的项目工程师。他拥有罗格斯大学电气工程学士学位以及马里兰大学电气工程硕士和博士学位。他的研究兴趣包括计算机体系结构和性能测量。可以通过 amink@nist.gov 联系 Alan。


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}