
POSIX 线程库
近年来,线程的普及程度有所提高,因为在许多应用程序中线程都很有用。在许多方面,线程的运行方式与进程相同,但可以更有效地执行。如今,所有现代操作系统都包含某种形式的线程管理支持。此外,线程已由 IEEE 操作系统技术委员会标准化。此标准允许用户编写可移植的多线程程序。
与其他操作系统一样,Linux 也包含多线程功能,并且 Linux 提供了一些多线程库。我们将描述对 Linux 的五个线程包的比较研究:CLthreads、LinuxThreads、FSU Pthreads、PC threads 和 Provenzano Pthreads。所有评估的库都使用了符合 POSIX 标准的功能。本研究的主要目的是评估和比较一些多线程特性的性能,以分析这些库在多线程应用程序中的适用性。此外,我们还与 Solaris 线程进行了比较。
线程是进程内独立的控制流。传统的 UNIX 进程具有单个线程,该线程独占进程的内存和其他资源。同一进程中的线程共享全局数据(全局变量、文件等),但每个线程都有自己的堆栈、局部变量和程序计数器。线程被称为轻量级进程,因为它们的上下文小于进程的上下文。此特性使得线程之间的上下文切换比传统进程之间的上下文切换更便宜。
线程对于提高应用程序性能很有用。只有一个控制线程的程序每次从操作系统请求服务时都必须等待。使用多个线程可以让进程将处理与一个或多个 I/O 请求重叠(参见图 1)。在多处理器机器中,多个线程是应用程序开发人员利用硬件并行性的有效方法。
此特性对于客户端/服务器应用程序尤其重要。客户端/服务器应用程序中的服务器程序可能会同时收到来自多个独立客户端的请求。如果服务器只有一个控制线程,则客户端请求必须按顺序处理。使用多线程服务器,当客户端尝试连接到服务器时,可以创建一个新线程来管理请求。
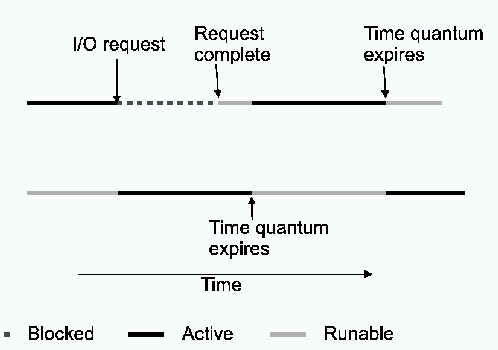
图 1. 重叠处理和 I/O 请求
一般来说,多线程功能对某些类型的应用程序(通常是服务器或并行处理应用程序)非常有益,使它们能够在多处理器硬件上获得显着的性能提升,即使在单处理器硬件上也能提高应用程序吞吐量,并有效利用系统资源。然而,线程并非适用于所有程序。例如,必须加速单个计算密集型算法的应用程序在单处理器硬件上执行程序时不会从多线程中受益。
线程控制有两种传统模型:用户级线程和内核级线程。
用户级线程包通常在现有操作系统之上运行。进程内的线程对内核不可见。线程由作为进程代码一部分的运行时系统调度。用户级线程之间的切换可以独立于操作系统完成。但是,用户级线程存在一个问题:当线程在进行系统调用时被阻塞时,进程内的所有其他线程都必须等待,直到系统调用返回。此限制限制了利用多处理器平台提供的并行性的能力。
内核级线程由内核支持。内核知道每个线程都是一个计划实体。在这种情况下,提供了一组类似于进程的系统调用,并且线程由内核调度。内核线程可以利用多个处理器;但是,线程之间的切换更加耗时,因为内核参与其中。
还有混合模型,支持用户级和内核级线程。这为运行进程提供了两种模型的优势。Solaris 提供了这种模型。
线程已由 IEEE 操作系统技术委员会标准化。POSIX 标准 (POSIX 1003.1) 的基础,可移植操作系统接口,定义了一个应用程序编程接口,该接口源自 UNIX,但也可能由任何其他操作系统提供。此标准包括一组线程扩展 (POSIX 1003.1c)。这些线程扩展为基本标准提供了接口和功能,以支持进程内的多个控制流。提供的设施代表了 POSIX 1003.1 的一小部分语法和语义扩展,以便为多线程函数提供方便的接口。
此标准中的接口专门针对支持紧密耦合的多任务环境,包括多处理器系统和高级语言结构。此标准涵盖的特定功能领域及其范围包括
线程管理:在公共共享地址空间的假设下,在同一进程中创建、控制和终止多个控制流。
同步原语:互斥和条件变量,针对进程内多个控制流的紧密耦合操作进行了优化。
协调:与现有的 POSIX 1003.1 接口。
多线程功能包含在 Linux 2.0 内核中。目前正在努力改进这一点,并使内核更具可重入性。多线程功能由 clone 系统调用提供,该调用创建一个新的执行上下文。此调用可用于创建新进程、新线程或一系列不属于这两类别的可能性之一。fork 系统调用实际上是对 clone 的调用,其中一组特定值作为参数,而 pthread_create 函数调用可能是对 clone 的调用,其中一组不同的值作为参数。
clone 系统调用有多个标志来指示线程之间将共享多少内容。图 2 列出了每个标志。

图 2. clone 系统调用的标志
线程功能由不同的线程包提供。Linux 提供了多个线程库。本文中提到的所有库都使用了符合 POSIX 标准的功能;但是,在撰写本文时,Linux 还没有完全符合 POSIX 标准的多线程库。
我们评估的库如下
Provenzano threads (PT):此软件包提供了一个用户级 POSIX 线程库,具有线程阻塞系统调用(read、write、connect、sleep、wait 等)和一个线程安全的 C 库(stdio、网络实用程序等)。此实现当前支持基本功能、同步原语、线程特定数据和线程属性。
FSU_Pthreads (FSUT):这是一个 C 库,它为不同的操作系统实现了用户级 POSIX 线程:Solaris 2.x、SCO UNIX、FreeBSD、Linux 和 DOS。此实现支持线程管理、同步、线程特定数据、线程优先级调度、信号和取消。
PC threads (PCT):这是一个用户级 POSIX 线程库,包括非阻塞 select、read 和 write。此库具有运行时可配置参数,例如时钟中断间隔、默认线程调度策略、默认线程堆栈大小和 I/O 轮询间隔等。
CLthreads (CLT)。CLthreads 是 Linux 之上的内核级 POSIX 兼容库。CLthreads 使用 clone 系统调用来充分利用多处理器系统。
LinuxThreads (LT)。LinuxThreads 是 Linux 的 POSIX 线程实现。LinuxThreads 提供内核级线程:它们是使用 clone 系统调用创建的,所有调度都在内核中完成。这种方法可以充分利用多处理器系统。它还产生了一个更简单、更健壮的线程库,特别是对于阻塞系统调用。
Solaris 支持线程的混合模型——用户级线程和内核级线程——以及 POSIX 兼容库。用户级线程由库支持,用于创建和调度,内核不知道这些线程。Solaris 还定义了一个中间级别的线程,即轻量级进程 (LWP)。LWP 介于用户级线程和内核级线程之间(参见图 3)。LWP 由线程库操作。用户级线程多路复用到进程的 LWP 上(每个进程至少包含一个 LWP),只有当前连接到 LWP 的线程才能完成工作。其余线程要么被阻塞,要么等待 LWP 以在其上运行。

图 3. Solaris 中的线程
每个 LWP 都有一个内核级线程,并且一些内核级线程代表内核运行,并且没有关联的 LWP。内核级线程是系统中唯一调度的对象。
使用此模型,任何进程都可能有很多用户级线程。这些用户级线程可以在内核支持的轻量级进程之间进行调度和切换,而无需内核的干预。每个 LWP 恰好连接到一个内核级线程。一个进程中有很多 LWP,但只有当线程需要与内核通信时才需要它们;如果一个 LWP 被阻塞,其他 LWP 可以在进程内继续执行。在 Solaris 中,用户可以创建永久绑定到 LWP 的新线程。
图 4 总结了评估库的用户级和内核级特性。

图 4. 库的种类
线程管理指标旨在评估线程创建和终止的效率。这些指标是
线程创建:线程创建时间的测量,例如,执行 pthread_create 操作的时间。
加入线程:在已终止的线程上执行 pthread_join 操作所需的时间。
线程执行:执行线程的第一条指令所需的时间。此时间包括线程创建时间和执行 sched_yield 操作的时间,如下所示
thread_1()
{ . . .
start_time();
pthread_create(...);
sched_yield();
. . . }
thread_2()
{
end_time();
... }
线程终止:从执行 pthread_exit 操作到此线程上的 pthread_join 操作完成的时间间隔,如下所示
thread_1()
{ . . .
start_time();
pthread_exit(...);
. . . }
thread_2()
{ . . .
pthread_join();
end_time();
... }
线程创建与进程创建:比较创建进程所需的时间与在进程内创建线程所需的时间。
加入线程与等待进程:比较在已完成的进程上执行等待操作所需的时间与在已完成的线程上执行 pthread_join 操作所需的时间。
并行粒度:这是在 n 个线程同时执行空循环的最小迭代次数,之后 n 个线程所需的时间少于单个线程自身执行总迭代次数所需的时间。n 线程情况的时间必须包括创建所有 n 个线程并等待它们终止的时间。程序员可以使用此数字来确定何时将任务划分为可以同时执行的 n 个不同部分可能是有利的。此指标为 n 提供,其中 n 是机器上的处理器数量。
这些指标集中在互斥锁和条件变量操作性能上。
互斥锁初始化:执行 pthread_mutex_init 所需的时间间隔。
互斥锁锁定:在空闲互斥锁上执行 pthread_mutex_lock 所需的时间间隔。
互斥锁解锁:执行 pthread_mutex_unlock 所需的时间间隔。
无争用互斥锁锁定/解锁:在仅由执行测试的线程使用的互斥锁上调用 pthread_mutex_lock 紧接着 pthread_mutex_unlock 所需的时间间隔。此测试如下所示
thread()
{ . . .
start_time();
pthread_mutex_lock(...);
pthread_mutex_unlock(...);
end_time();
. . . }
互斥锁销毁:执行 pthread_mutex_destroy 操作所需的时间。
条件变量初始化:执行 pthread_cond_init 所需的时间间隔。
条件变量销毁:执行 pthread_cond_destroy 操作所需的时间。
同步时间:测量两个线程使用两个条件变量相互同步所需的时间,如下所示
thread_1()
{ . . .
start_time();
pthread_cond_wait(c1,...);
pthread_cond_signal(c2);
end_time();
. . . }
thread_2()
{ . . .
pthread_cond_signal(c2);
pthread_cond_wait(c1,...);
. . . }
有争用互斥锁锁定/解锁:一个线程调用 pthread_mutex_unlock 到另一个被阻塞在 pthread_mutex_lock 上的线程返回并持有锁之间的时间间隔。
thread_1()
{ . . .
pthread_mutex_lock(...);
start_time();
pthread_mutex_unlock(...);
. . . }
thread_2()
{ . . .
pthread_mutex_lock(...); < Blocked >
end_time();
pthread_mutex_unlock(...);
. . . }
无等待者的条件变量信号/广播:如果条件上没有线程被阻塞,则执行 pthread_cond_signal 和 pthread_cond_broadcast 所需的时间。
条件变量唤醒:从一个线程调用 pthread_cond_signal 到阻塞在该条件变量上的线程从其 pthread_cond_wait 调用返回的时间。条件及其关联的互斥锁不应被任何其他线程使用。
thread_1()
{ . . .
pthread_mutex_lock(...);
start_time();
pthread_cond_signal(...);
pthread_mutex_unlock(...);
. . . }
thread_2()
{ . . .
pthread_mutex_lock(...);
pthread_cond_wait(...);
end_time();
pthread_mutex_unlock(...);
. . . }
所有结果都是通过在配备双 Pentium Pro 处理器的 PC 上运行基准测试获得的。Pentium Pro 处理器是采用 RISC 技术的 32 位处理器。此处理器使用动态执行,它是改进的分支预测、推测执行和数据流分析的组合。计算机的时钟速度为 200MHz,配备了 64MB 内存和 2GB 硬盘。
所有测试都执行了十次,并将测量的平均值作为测试结果。此结果指示了正在评估的功能的性能。我们考虑了平均值,因为它们更能代表用户可以从机器获得的性能。其他作者考虑最小值,因为它们应该不受操作系统和其他用户的影响。测试是在机器上只有一个用户的情况下进行的。所有测试都比较了 Solaris 线程、Provenzano threads (PT)、FSU_Pthreads (FSUT)、PC threads (PCT)、CLthreads (CLT) 和 LinuxThreads (LT) 获得的性能。在 Solaris 中创建的线程永久绑定到 LWP,以充分利用所使用的硬件平台。
图 5 中显示的数字是线程管理测量的结果。所有值均以微秒为单位给出,并行粒度除外,其值以迭代次数给出。总的来说,可以看出用户级软件包比内核级软件包和 Solaris 线程更有效,因为线程是在操作系统之上创建的,并且对内核不可见;但是,这些库对于在多处理器系统上运行的多线程应用程序没有用处。Provenzano threads 和 FSU_Pthreads 就是这种情况,尽管 PC threads 呈现出更耗时的结果。并行粒度的结果显示了内核级库(Solaris、CLthreads 和 LinuxThreads);用户级库无法在多个处理器中执行多个线程。图 5 显示了 Solaris 如何更好地利用多处理器架构。比较线程执行和并行粒度结果,我们可以看到 Linux 线程(CLthreads 和 LinuxThreads)的上下文切换比 Solaris 线程更耗时。LinuxThreads 可以比 CLthreads 更好地利用多处理器系统。
图 6 描述了同步管理测量的结果。PC threads (PCT) 效率较低,尽管它是一个用户级库。结果表明,Provenzano threads 是评估的最佳用户级库,而 LinuxThreads 是在 Linux 机器中使用的良好内核级库。
我们的目标是评估和比较 Linux 的五个 POSIX 线程库的性能,以及它们与其他操作系统(如 Solaris)的比较情况。结果集中在线程管理和同步管理测量上。主要结果表明 Provenzano threads 是最佳用户级库,而 LinuxThreads 是一个良好的内核级库。此外,结果表明 Linux 线程(CLthreads 和 LinuxThreads)的上下文切换比 Solaris 线程更耗时。



