
Intel MMX 技术概述
MMX 技术于 1997 年 1 月商业化推出,是 Intel 架构的扩展,它使用单指令多数据执行模型,允许同时处理多个数据元素。MMX 技术适用于那些使用小整数进行大量可并行计算的应用程序。这些应用程序的示例包括 2D/3D 图形、图像处理、虚拟现实、音频合成和数据压缩。
如果您的 Linux 系统配备了奔腾 II 或带有 MMX 技术的奔腾处理器,您可以使用 gcc 和少量汇编语言来构建利用 MMX 指令集的程序。在本文中,我将简要介绍 MMX 技术的主要特性,解释如何检测 x86 微处理器是否具有内置 MMX 功能,并展示如何编写一个简单的图像处理应用程序。
本文提供的汇编语言代码使用了 NASM,即 Netwide Assembler。NASM 采用标准的 Intel 语法,而不是许多流行的 UNIX 汇编器(如 GAS)使用的 AT&T 语法。

图 1. MMX 寄存器集
MMX 技术通过增加八个 64 位寄存器和 57 条指令来扩展 Intel 架构。新寄存器命名为 MM0 到 MM7(见图 1)。根据我们使用的指令,每个寄存器可以解释为一个 64 位四字、两个压缩的 32 位双字、四个压缩的 16 位字或八个压缩的 8 位字节(见图 2)。
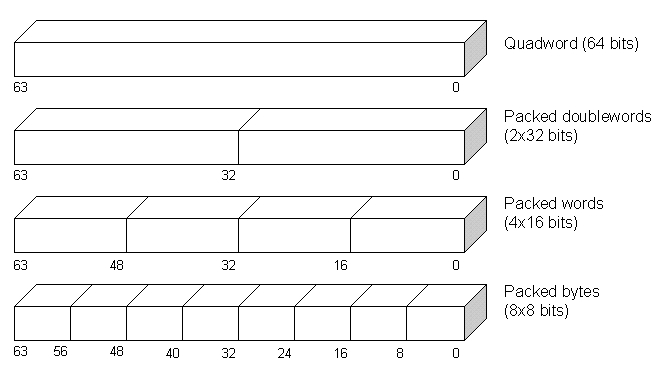
图 2. MMX 数据类型
MMX 指令集包含几个类别的指令,包括用于算术、逻辑、比较、转换和数据传输操作的指令。
MMX 指令的语法与其他 x86 指令类似
OP Destination, Source
此行被解释为
Destination = Destination OP Source除了数据传输指令外,目标操作数必须始终是任何 MMX 寄存器。源操作数可以是存储在内存位置或 MMX 寄存器中的数据。稍后将进一步讨论一些特定的 MMX 指令。
在运行使用 MMX 指令的程序之前,务必确保您的微处理器实际上支持 MMX。您的 Linux 系统应该是 Intel x86 或兼容的微处理器(386、486、奔腾、奔腾 Pro、奔腾 II 或任何 Cyrix 或 AMD 克隆产品)。这可以通过执行 uname -m 命令轻松检查。此命令应返回 i386、i486、i586 或 i686。如果不是,则您的 Linux 系统运行在非 x86 架构上。
为了确定您的 CPU 是否支持 MMX 技术,请使用汇编语言 CPUID 指令。此指令揭示重要的处理器信息,例如其供应商、系列、型号和缓存信息。不幸的是,CPUID 指令仅存在于一些较晚的 80486 处理器及更高版本中。那么,您如何知道您的系统上是否可以使用 CPUID 呢?Intel 文档记录了以下技巧:如果您的程序可以修改 EFLAGS 寄存器的第 21 位,则 CPUID 指令可用;否则,您正在使用老旧的 CPU。请参阅清单 1(第 12-29 行)以了解如何完成此操作。
接下来,通过在 EAX 寄存器中放入值 1 并执行指令来请求 CPU 功能信息。结果值在 EDX 寄存器的第 23 位返回。如果此位为开启,则处理器支持 MMX 指令集;否则,它不支持。清单 1(第 43-50 行)显示了如何执行此操作。
程序应包含同一例程的两个版本:一个使用 MMX 技术,另一个使用常规标量代码。在运行时,程序可以决定实际应调用哪个例程。
如果在不支持 MMX 指令的系统中执行 MMX 指令,CPU 将引发“无效操作码异常”(中断向量号 6),该异常会被 Linux 内核捕获。Linux 内核反过来向违规进程发送“非法指令信号”(代码号 4)。默认情况下,此操作会终止程序并生成核心文件。

图 3. 原始灰度图像
假设我们有一个灰度位图图像,如图 3 所示。每个像素存储在一个无符号 8 位字节中,该字节包含在数组中。较小的数字表示较暗的灰色调,而较大的数字表示较亮的色调。数字 0 和 255 分别表示纯黑色和白色。为了代码的简洁性,此程序中使用的图像(请参见存档文件中的清单 2)使用了 Microsoft Windows 的灰度 BMP 文件格式。John Bradley 的 xv 实用程序可以在 Linux 下轻松用于创建和显示此类位图图像。
为了使图像更亮,我们只需要向其每个像素添加一个正整数(例如 64 十六进制)。在 C 语言中,我们将得到如下代码
#define BRIGHTENING_CONSTANT 0x64 unsigned char bitmap[BITMAP_SIZE]; size_t i; /* Load image somehow ... */ for(i = 0; i < BITMAP_SIZE; i ++) bitmap[i] += BRIGHTENING_CONSTANT;

图 4. 使用回绕算术的亮度增强图像
不幸的是,我们最终得到了图 4 中的不 желаемый 图像。发生这种情况是因为回绕;如果加法的结果溢出(即超过 255,这是无符号 8 位字节的上限),则结果将被截断,以至于仅考虑较低(最低有效)位。例如,将 100(64 十六进制)添加到像素值 250(几乎纯白色)得到如下结果。
250 decimal 11111010 binary
+ 100 decimal + 01100100 binary
------------- ------------------
= 350 decimal = 101011110 binary Overflow
produced
= 94 decimal = 01011110 binary Take the 8
least significant bits
结果是 94,它产生较暗的灰色而不是更亮的灰色,从而导致可观察到的反转效果。
我们需要的是,每当加法超过最大限制时,结果都应饱和(裁剪到预定义的数据范围限制)。在这种情况下,饱和值为 255,它表示纯白色。以下 C 代码片段处理饱和
int sum;
for(i = 0; i < BITMAP_SIZE; i ++)
{
sum = bitmap[i] + BRIGHTENING_CONSTANT;
/* UCHAR_MAX is defined in <limits.h>
* and is equal to 255u */
if(sum > UCHAR_MAX)
bitmap[i] = UCHAR_MAX;
else
bitmap[i] = (unsigned char) sum;
}
现在我们获得了图 5 中显示的图像,该图像正如我们所期望的那样被亮度增强了。

图 5. 使用饱和算术的亮度增强图像

图 6. 使用饱和的无符号字节压缩加法
MMX 技术允许我们仅使用一条指令 paddusb 对八个无符号字节并行执行此饱和算术加法。图 6 显示了此指令的工作原理示例。我们的图像亮度增强算法(请参见清单 1,从第 61 行开始)可以描述如下
将相同的亮度增强常量字节打包八次到 MM0 寄存器中(第 66 行)。
重复位图大小 / 8 次
将位图数组中的下八个字节复制到 MM1 寄存器中(第 74 行)。
将 MM0 中包含的八个压缩无符号字节添加到 MM1 中包含的八个压缩无符号字节。使用饱和(第 75 行)。
将 MM1 寄存器的结果复制回最初从中获取的位图数组(第 76 行)。
前进位图数组索引寄存器(第 77 行)。
步骤 1 和 3 中使用的 movq MMX 指令将 64 位从源操作数复制到目标操作数。
每当我们完成执行 MMX 指令时,应使用 emms 指令(清单 1,第 81 行)来清除 MMX 状态。这是一个重要的问题,特别是如果我们的程序中随后有任何浮点指令。为了使 MMX 技术与现有的操作系统和应用程序兼容,Intel 工程师决定 MMX 寄存器应与浮点寄存器共享相同的物理空间。这被认为是必要的,例如,在 Linux 等多任务操作系统中,每当发生任务切换时,都必须保存正在运行的进程的状态,以便将来可以恢复它。此状态保存涉及将 CPU 的所有寄存器复制到内存中。如果向 CPU 添加更多寄存器,则还必须修改负责保存寄存器的操作系统代码。但是,如果您的新寄存器与现有寄存器别名,则代码中无需进行任何更改。
不幸的是,在 MMX 和浮点寄存器的情况下,这种折衷方案有一个主要的缺点:您不能同时使用这两种类型的寄存器,仅仅因为它们代表两种非常不同的数据类型。一般规则是您不能在同一代码段中混合使用 MMX 和浮点指令。因此,emms 指令是通知 CPU 程序中允许将来使用浮点指令的机制。
这一切都值得吗?这个问题的答案取决于您对速度的重视程度。将 MMX 示例程序与纯 C 语言版本进行比较,速度的提升不言而喻。当不进行优化编译时,MMX 例程比 C 版本(存档文件中的清单 2)快大约 14 倍,而在启用完全 -O2 优化时,快大约 5 倍。当然,您将失去可移植性,并且可能更难编写和调试汇编语言代码。生活充满了艰难的选择,不是吗?

