
经济型容错网络
在过去的十年左右,我们见证了计算机网络作为通信和计算世界融合的演变。这场革命使全球互联互通的梦想成为可能,并随之带来了大量人员利用计算机网络执行众多重要任务的爆炸式增长。移植到基于网络的应用程序和服务的任务的庞大数量和重要性使得可靠性成为不可否认的需求。另一方面,网络总是会因各种原因而发生故障,包括但不限于电源故障、通信链路中断、硬件故障和软件崩溃。克服这些故障并为用户维护网络服务需要通过实施容错来实现。
实现容错的一种常用方法是冗余数据复制。使用完全相同的副本代替发生故障的网络组件可确保网络上服务的可用性。故障检测和更换过程必须快速且自动,以使客户端看不到故障。
我们的解决方案基于一组相同的 Linux 服务器集群,提供各种网络服务。除了标准网络连接之外,我们没有采用任何额外的链路。解决方案中的各种组件包括选择故障组件的后继者的算法,以及进程之间的时钟和数据同步程序。服务和数据在集群内的所有计算机上复制。如果服务器发生故障,则由一个副本替换它,该副本携带崩溃机器提供的所有数据和服务配置的冗余副本。在检测到故障后,在相同的服务器之间启动选举过程,并选出一个崩溃服务器的替代者。在网络的正常工作条件下,当前服务器定期将时钟时间、数据和关键配置文件推送到集群的其余部分,以将它们维护为对等节点。
提高网络可靠性的标准技术可以分为两大类。
专用硬件:这种方法昂贵,并且需要特殊维护。这种方法的示例包括 RAID(廉价磁盘冗余阵列)和需要在机器之间建立辅助通信链路的非 IP 解决方案。
辅助备份机器:这些机器与主服务器相同,并维护为主服务器的镜像。它们的主要缺点不是成本高昂,而是当网络发生故障时,切换到备份机器对客户端来说不是透明的。实际上,客户端需要预先配置辅助(或从属)服务器参数。大多数服务的客户端通常会先尝试主服务器;然后,在超时时,尝试使用辅助服务器。这会引入不必要的开销和延迟。另一个需要注意的重要事项是,备份机器是 100% 冗余的,仅在主服务器发生故障时使用。
问题在于实现一种软件解决方案,以确保可靠性,而无需额外的硬件,并保持切换对客户端透明。此外,我们不希望通过完全将一台或多台机器专用于备份角色来浪费资源。
我们的解决方案的根源在于已建立的主服务器和辅助服务器备份系统。我们没有使用两台计算机,而是使用一组计算机。选择其中一台计算机作为主机器来协调网络服务,其余的计算机则充当从属机器的角色:参与选举的通用服务器级机器。主服务器设置一个虚拟 IP 地址并启动网络正常运行所需的所有服务。从属服务器监控主服务器的状态以检测故障。如果发生故障,将选择一个新的主服务器并恢复网络服务;这种更改对客户端来说是透明的。从属服务器并非旨在仅专用于此目的;相反,它们可以用于执行其他任务(计算服务器、工作站等)。只有在被选为主服务器后,机器才会承担建立虚拟服务器的任务。
发生故障时,最关键的任务是选择新的主机器。无法预测链中的哪些机器会因较早的故障或被关闭而不可用。因此,像主/辅助服务器中那样的简单的预先建立的切换层次结构是不切实际的。此外,不能使用单个协调器来选择主服务器,因为该协调器的故障将导致网络完全故障。
考虑到这些事实,我们使用分布式选举算法来选择已死主服务器的适当后继者。选举算法广泛用于在并行和分布式计算中选择协调器进程。最初,我们尝试了“Bully Election”算法。(请参阅资源。) 这存在一个缺点,即当修复发生故障的主服务器并将其重新接入网络时,它会欺负已建立的主服务器交出服务。这会造成不必要的切换,并导致更新的数据丢失,此外还会导致网络延迟。数据丢失的原因是更新可能已在新主机器中完成,而当原始崩溃的主服务器恢复时,它不具有更新的数据。
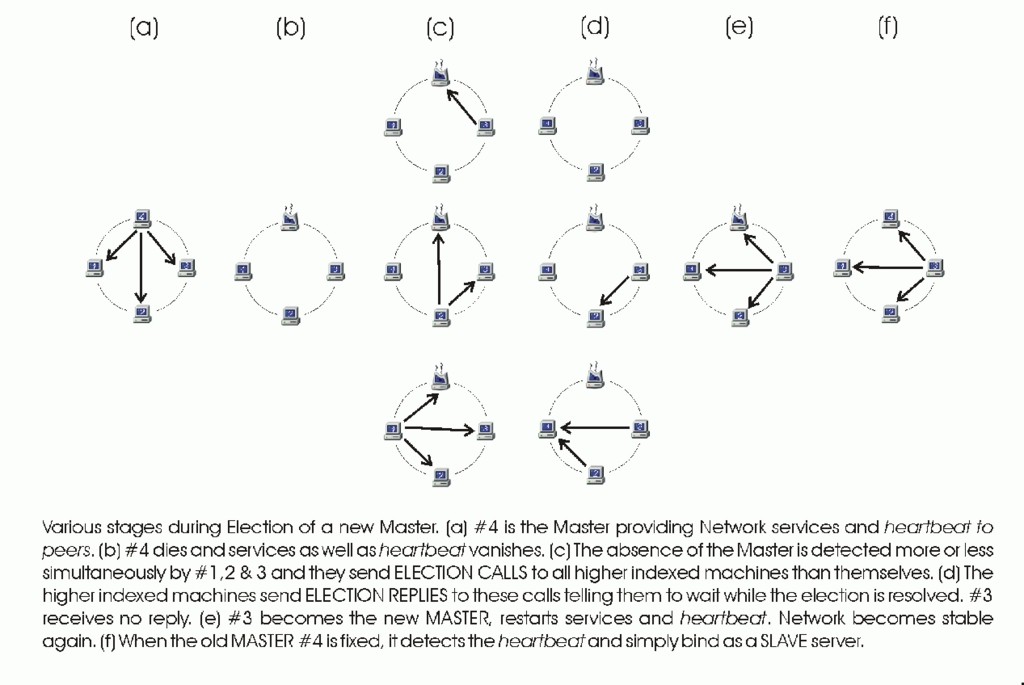
图 1. 选举算法
“改进的 Bully Election”算法是我们对基本 Bully Election 算法的修改。假设一个稳定的网络,其中有一组服务器可用。其中一台机器充当主机器,为网络提供服务。主服务器还向所有从属服务器多播“心跳”信号,告知它们它的存在。所有机器都分配有一个性能指标编号。此编号取决于各种参数,例如处理器速度、最新数据的可用性、可用资源等。它可以动态地在每次选举时分配,或者在最简单的情况下,它是一个 IP 地址。机器的序号越高,它就越适合充当主服务器。
现在,假设发生故障,导致主服务器崩溃。其余机器从心跳信号的缺失中检测到故障,并进入选举状态。在此状态下,机器向所有索引号高于自身的机器发送选举呼叫。如果索引号较高的机器可用,它将回复此选举呼叫。收到选举回复后,机器进入“绑定等待”状态。如果在选举状态的机器在指定的时间内未收到回复,则它断定它具有最高的索引号。然后它进入“初始化”状态。在此状态下,它启动中断的网络服务并恢复心跳信号。它还向其他机器发送绑定信号,使它们进入从属状态。最后,它自身进入主状态,网络再次变得稳定。
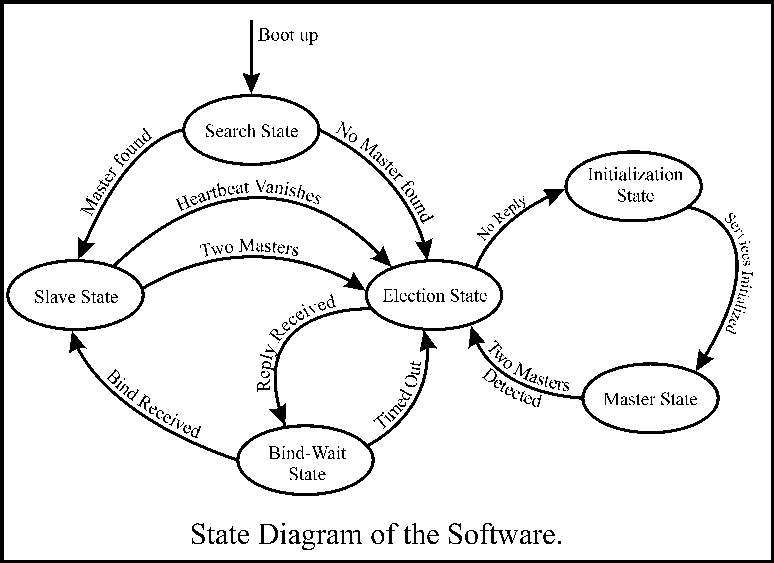
图 2. 状态图
在收到选举回复后,如果编号较低的机器在指定时间内无法进入从属状态,则选举超时并重新启动。因此,此分布式过程将在任何故障序列下选举出一个主服务器。如果现在修复了发生故障的主服务器并将其重新启动,它将不会启动选举。实际上,它首先侦听心跳信号。如果找到主服务器,它只需进入从属状态,直到下一次故障发生。
我们对原始 Bully Election 算法的修改是,具有最高索引号的计算机不一定始终是主服务器。在原始算法中,每当索引号较高的机器出现时,无论网络状态如何,它都会始终调用重新选举并接管控制权。在我们的案例中,我们发现这种欺负过程在实际实施中是不切实际的。我们实施了一种变体,使得当索引号较高的计算机恢复时,具有主服务器的稳定网络不会受到干扰。它在启动期间检测到主服务器的存在,并在找到主服务器时进入从属状态。只有在启动新的选举时,索引号最高的机器才会接管。当前的主服务器始终是最近一次选举的获胜者,因此是当时存活的索引号最高的机器,但不一定是当前时间。
不将欺负部分包含在选举算法中的直接后果是可能存在两个主服务器。由于我们依赖主服务器来控制作为虚拟服务器的关键 IP 地址,因此两个主服务器是完全不可接受的。当主服务器因网络拥塞而隔离时,可能会发生此类问题,其他机器断定其已死并选举另一个主服务器。随着拥塞的解决和原始主服务器的重新出现,将会有两个主服务器。克服此问题的一种非常简单的技术是,所有机器都监控心跳信号的来源。如果发现它不是唯一的,则重新进行选举,再次产生单个主服务器。
通过遵循此算法,我们能够促进网络上始终存在工作的主服务器。由于它是分布式实现,因此任何单个组件的故障都不会影响选举。因此,可以持续地向网络提供各种服务。
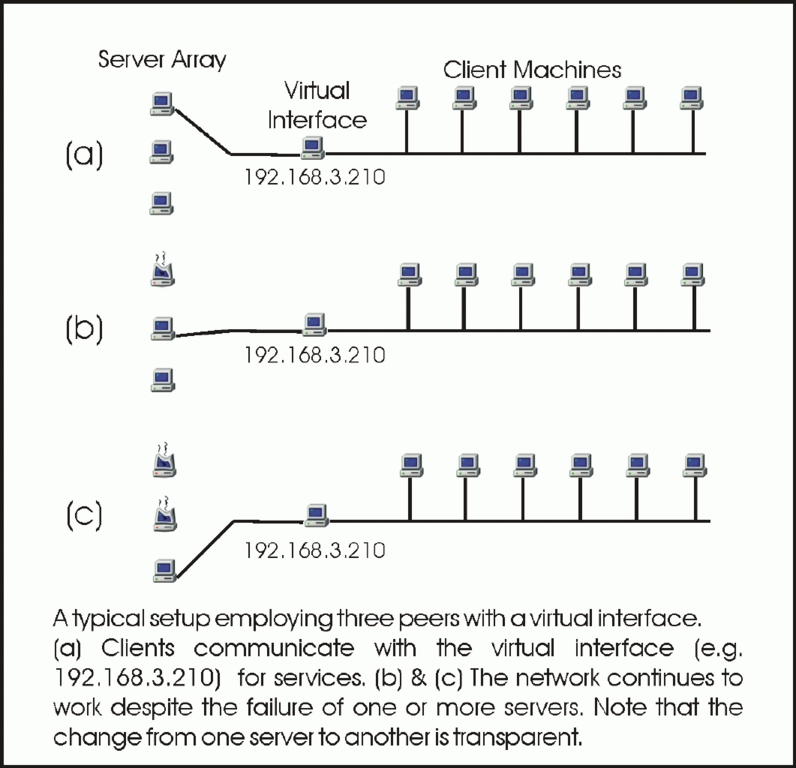
图 3. 虚拟服务器图
选举过程选出一个主服务器,但我们离使主服务器的这种更改对客户端透明还差得很远。为了实现透明性,我们选择一个任意 IP 地址,以下称为虚拟服务器地址。此地址不是集群中某台机器的地址,而是一个单独的地址。所有客户端都配置为使用虚拟服务器地址来请求服务。每当一台机器成为主服务器时,它就会接管虚拟服务器地址并继续其原始地址。IP 别名用于实现此目的,即为单个网络适配器分配多个 IP 地址。然后,新的主服务器开始提供先前由发生故障的主服务器提供的网络服务。因此,虚拟服务器始终可用,由参与选举过程的任何机器供电。由于客户端始终与虚拟服务器通信,因此容错算法的过程对它们来说是不可见的。
新当选的主服务器悄悄地接管了虚拟服务器地址。但是,客户端已经具有地址解析协议 (ARP) 缓存条目,该条目将虚拟服务器 IP 地址连接到发生故障的主服务器的机器地址 (MAC)。此缓存将阻止客户端与较新的主服务器通信,因为客户端仍会尝试与旧的 MAC 地址通信。克服此问题的一种解决方案是选择一个任意 MAC 地址并由当选的主服务器接管。这种方法的问题是并非所有网络适配器都支持此功能。另一种解决方案是粗暴地转储所有客户端的 ARP 缓存,然后重置缓存,这也不是一种有效的技术。
我们设计的解决方法是在新当选的主服务器的 ARP 缓存中删除虚拟服务器 IP 地址条目。现在,主服务器自动尝试更新其 ARP 缓存。在此过程中,它会联系网络上的机器,包括客户端和从属服务器。这不仅更新了主服务器的 ARP 缓存,还更新了客户端的 ARP 缓存。此技术的优点是我们的软件不必向每台计算机发送特殊的更新数据包,而是已经工作的 ARP 机制为我们完成了这项工作。
更新 ARP 缓存,然后接管 IP 地址,透明地导致客户端从新当选的主服务器请求服务。客户端在实际选举发生时可能会遇到一些延迟,但除此之外,它们会继续不间断地运行。
整个切换场景中一个非常关键的方面是,应该保持机器相同。只有这样,切换才能真正透明。必须采取措施确保在发生故障时,可能的新主服务器具有尽可能多的更新数据。维护对等节点的两个重要方面是时间和文件同步。
重要和关键的文件需要在所有服务器上分发。任何服务器都可能是主服务器,并且可能具有较新版本的文件。因此,服务器必须进行时间同步,以便它们的文件时间戳具有可比性,这变得势在必行。这确保在文件同步时仅分发更新的版本。需要注意的重要事项是,时间不必与实际时间匹配。唯一的要求是所有服务器都具有相同的时间。我们依靠简单地使用远程 shell 程序将时钟设置为与主服务器的时间相同。未使用特殊的时钟服务器,尽管运行 NTPD 或 TIMED 会是一种更好的技术。
维护对等节点的另一项重要任务是在整个服务器阵列上执行数据同步和复制,以保持它们始终相同。复制过程非常耗时,并且经常会使网络拥塞。复制频率应足够高,以适应替换透明度并最大程度地减少切换期间的数据丢失,同时又应足够低,以允许网络正常运行而不会造成不必要的拥塞。
在非常动态的情况下,可能无法在所有参与选举的机器上连续分发更新。在这种情况下,切换可能会导致文件回退到上次同步的版本。通常,同步安排在低工作负载时间内进行。此外,现在数据被分发到服务器阵列,而不是进行备份,这更好地服务于目的。
在讨论了软件解决方案的各种必要方面之后,我们继续对其进行描述。我们使用在 Red Hat Linux 6.0 上运行的 Perl 5.0 实施了此解决方案。由于 Perl 的可移植性,该软件可以在任何版本的 Linux/UNIX 上运行,只需进行少量或无需更改。该程序作为守护程序实现,在服务器启动时启动。它在生成四个进程后移至后台
心跳侦听器进程,用于处理主服务器生成的心跳信号。
侦听器进程,用于接收和解析从其他服务器生成的各种信号。
Doctor 进程,用于解释心跳信号并确定主服务器是否发生故障。
Elector 进程,用于实际实施选举算法并确定需要采取哪些操作。如果在主服务器上运行,它还会生成心跳信号。
主守护程序辅以特殊脚本来处理启动和同步。为 Master 服务器和 Slave 服务器创建了单独的脚本。这使得在 Master 服务器和 Slave 服务器上配置启动服务非常容易。
除了从属脚本外,还提供了一系列脚本用于文件同步和分发。它们可以启动以进行计划的同步和备份。
我们使用 UDP 通信进行心跳信号,以最大程度地减少网络负载。对于选举呼叫和其他信号,使用 TCP 以确保可靠性。
如果不加以检查,任何外部机器都可以生成选举呼叫,并且服务器将进入不需要的选举状态。因此,服务器之间交换的信号的安全性和完整性受到高度重视。我们实施了三个级别的安全措施以确保安全运行。
级别 1:所有参与选举的服务器列表都维护在所有服务器上。仅接受来自这些机器的信号;所有其他与选举过程相关的消息都将被丢弃。
级别 2:服务器是面向状态的。也就是说,它们获得某些状态,例如,选举状态、主状态等。在每种状态下,都会预期某些信号,并且仅接受这些信号。接收到的任何其他信号,即使源自列出的服务器,也会被丢弃。
级别 3:加密方案用于加密所有信号。为加密创建一个随机密钥,并且该密钥仅对一条消息有效。因此,即使信号被拦截和破解,加密密钥在任何其他时间都将无效。
对于我们的实施,我们凭经验发现,每周同步大型数据就足够了,而密码数据库在每次选举时都会复制。其他情况可能需要更频繁的同步。
集群的可靠性和容错级别与集群的大小成正比增加。增加服务器数量会增加同步的维护时间,并过度延长选举过程。在我们的情况下,我们通过实验确定三到四台服务器足以保证实用的解决方案。
平均而言,从属服务器的负载可以忽略不计,而主服务器的负载不超过 CPU 使用率的 0.1%。网络负载也很低,除非在繁重的同步期间,因此同步作为计划进程运行。
我们用于此实施的测试平台是巴基斯坦拉合尔 UET 数字计算机实验室。该实验室由 10 台基于奔腾的服务器和 60 台通过 10MBps 以太网连接的无盘工作站组成。

Jahangir Hasan 是巴基斯坦拉合尔 UET EE-通信系统专业的应届毕业生。
Kamran Khalid 是巴基斯坦拉合尔 UET EE-通信系统专业的应届毕业生。
Farhan-ud-din Mirza 是巴基斯坦拉合尔 UET EE-通信系统专业的应届毕业生。

