
THOR:超级计算机开发的多功能商品组件
世界上最高能量的粒子加速器,大型强子对撞机(LHC),目前正在瑞士日内瓦附近的欧洲核子研究中心(CERN)建造。计划的首次碰撞日期是2005年。自从美国的超导超级对撞机(SSC)于1993年终止以来,欧洲核子研究中心实际上已成为一个世界实验室,来自美国、非洲、欧洲、亚洲和澳大利亚的物理学家并肩工作。大型强子对撞机将比以往任何时候都更深入地穿透微观世界,以重现宇宙大爆炸后百万分之一秒的条件,那时温度高达万万亿度。
我们的团队是大约1500名物理学家团队中的一小部分,他们来自全球100多个机构,参与了ATLAS(超环面大型强子对撞机实验装置)实验的建设,这是准备在大型强子对撞机上获取数据的两个通用探测器之一。ATLAS的实验环境非常严苛。例如,ATLAS有数十万个探测器通道,并且必须跟上碰撞速率,这可能会在每25纳秒内产生约30个新事件。此外,探测器及其配套电子设备通常必须在高辐射环境中运行。显然,在这样的领域中,计算需求至少可以说是非常高的。欧洲核子研究中心对于解决国际粒子物理学提出的独特问题所需的软件开发并不陌生。例如,万维网最初是在欧洲核子研究中心设计的,旨在帮助散布在众多研究机构和大学的数百名成员之间进行沟通。
我们团队的粒子物理学家参与了两个领域,这两个领域都提出了大型计算问题。第一个是时间关键型计算领域,其中原始速率必须通过称为触发的三阶段实时数据选择过程,从大约1 GHz的事件速率降低到大约100 Hz。我们与来自欧洲核子研究中心、法国、意大利和瑞士的团队一起,参与了触发的最后阶段,称为事件过滤器,该过滤器将数据速率从1GB/s降低到100MB/s,首次完全重建数据并将数据写入存储介质。据估计,如果处理器速度发展的当前趋势继续下去,处理的最后阶段目前将需要大约一千个“奔腾”处理器。
我们还积极参与模拟ATLAS探测器对将要或可能存在的物理过程的响应。第二个任务不是时间关键型的,但需要大型模拟程序,并且通常需要数十万个完全模拟的事件。这些应用程序都不需要在处理期间节点之间进行通信。
为了在这两个领域实现我们的研究目标,我们必须开发一个多功能的系统,该系统可以充当ATLAS事件过滤器的实时原型,并且还能够生成大量的蒙特卡罗数据用于建模和模拟。我们需要一种具有成本效益的解决方案,该解决方案应具有可扩展性和模块化,并且与现有技术和软件兼容。此外,由于项目的时间尺度,我们需要一个具有明确且经济的升级路径的解决方案。这些限制不可避免地将我们引向了带有Linux操作系统的“Beowulf型”商品组件多处理器。我们最终开发的机器被称为THOR,这与类似类型系统的名称的北欧性质保持一致,例如NASA的Beowulf机器和洛斯阿拉莫斯国家实验室的LOKI。
在我们关于THOR的设计讨论中,我们很快清楚地认识到,可扩展性、模块化、成本效益、灵活性以及商业升级路径的优势使商品组件多处理器成为为无数科学和商业任务提供高性能计算的有效方法——能够用于时间关键型和离线数据采集和分析任务。商品英特尔处理器与传统快速以太网以及高速网络/背板结构(来自Dolphin Interconnect Solutions Inc.的可扩展一致性接口(SCI))的结合使THOR机器能够作为串行处理器集群运行,或者作为使用MPI的完全并行多处理器运行。还可以快速将THOR机器从完全并行模式重新配置为全串行模式,或用于混合并行串行使用。
为了演示THOR项目的基本思想,已经构建了一个原型。图1显示了THOR早期版本的照片。该原型目前由42台双奔腾II/III MHz机器(40个450MHz和44个600MHz处理器)组成,每台机器具有256MB的RAM。每个节点通过100Mb/s以太网48路交换机连接。一台450MHz双奔腾II计算机提供了进入THOR原型的网关。该原型可以通过快速/宽SCSI接口访问150GB的磁盘空间,以及一个能够存储大约半TB数据的42槽DDS2磁带机器人。THOR原型目前在Red Hat Linux 6.1下运行。

图1. THOR商品组件多处理器
40个节点中的16个已使用SCI连接成二维4x4环面网络,这允许最大双向链路速度为800MB/s。我们已测量SCI的吞吐量为91MB/s,这接近PCI总线的最大值133MB/s。当64位版本的SCI硬件与64位PCI总线宽度结合使用时,此最大值将会上升。在THOR上使用SCI允许将这些THOR节点分类为缓存一致性非均匀内存访问(CC-NUMA)架构机器。THOR原型的这个16节点(32处理器)细分部分是由Dolphin Interconnect Solutions Inc.和THOR的联合团队在1999年夏季作为完全并行机器实施和测试的。图2显示了THOR Linux集群的示意图。
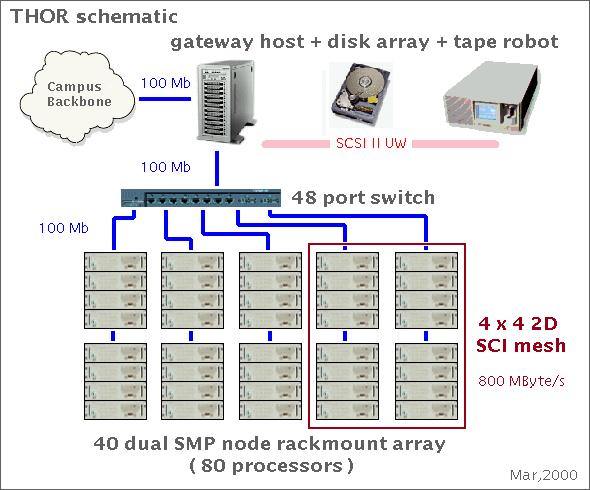
图2. THOR Linux集群的示意图
上述THOR原型现在正在作为并行和串行机器进行基准测试,并用于积极的物理研究。研究人员可以使用完整的C、C++和FORTRAN编译器、CERN和NAG数值库以及MPI并行库进行研究。我们还计划在不久的将来为THOR研究使用购买最新Linux版本的IRIS Explorer。PBS(NASA开发的便携式批处理系统)自1999年3月以来一直在THOR上运行。
当THOR原型由20个450MHz双奔腾II处理器组成时,我们对其进行了广泛的基准测试。此基准测试使用了各种软件。此处报告的两个基准测试程序中的第一个是用FORTRAN使用MPI编写的三维快速傅里叶变换(FFT)程序。该软件将THOR集群用作并行机器而不是串行处理器。如图3所示,使用此FFT的单个THOR节点的速度与450MHz Cray-T3E和卡尔加里DEC Alpha集群(1999年)相当,并且比SGI Origin 2000 (R10K) 慢大约50%。作为一台完全并行的机器,可以看出THOR在此FFT过程中与卡尔加里DEC Alpha集群和Cray-T3E具有竞争力。
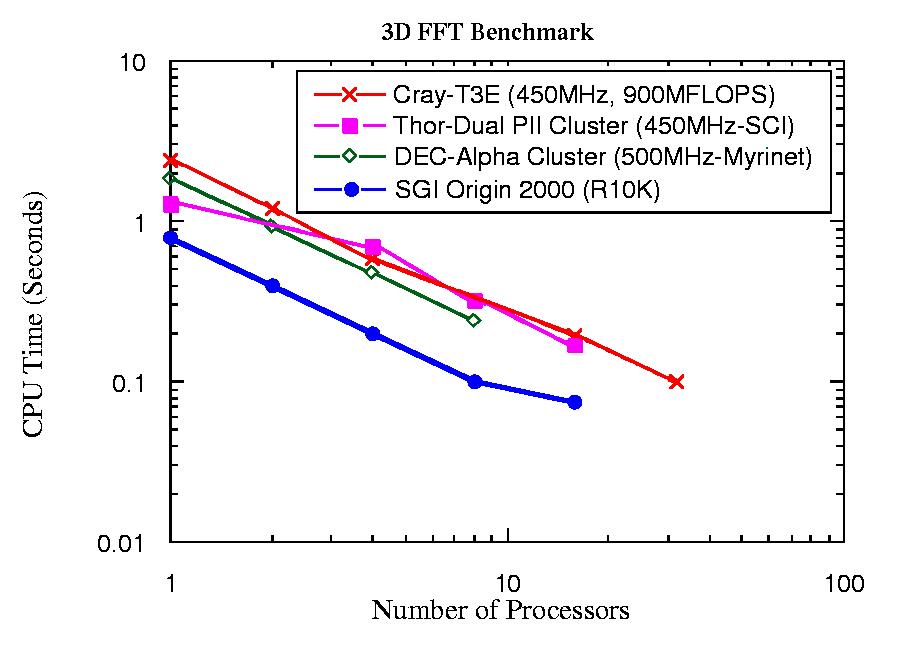
图3. 来自三维快速傅里叶变换程序的基准测试结果
第二个基准测试是使用为在地震建模领域利用有限差分法而开发的代码获得的,该代码是用C语言使用MPI编写的。在这种情况下,比较是在使用SCI互连或100 Mbp/s以太网的THOR多处理器与SGI Origin 2000之间进行的。结果如图4所示。可以看出,与以太网网络解决方案相比,使用SCI背板/网络结构提高了THOR多处理器的性能。根据此基准测试,当处理器数量接近16个时,使用SCI的THOR多处理器的性能变得与SGI Origin 2000的性能相当。
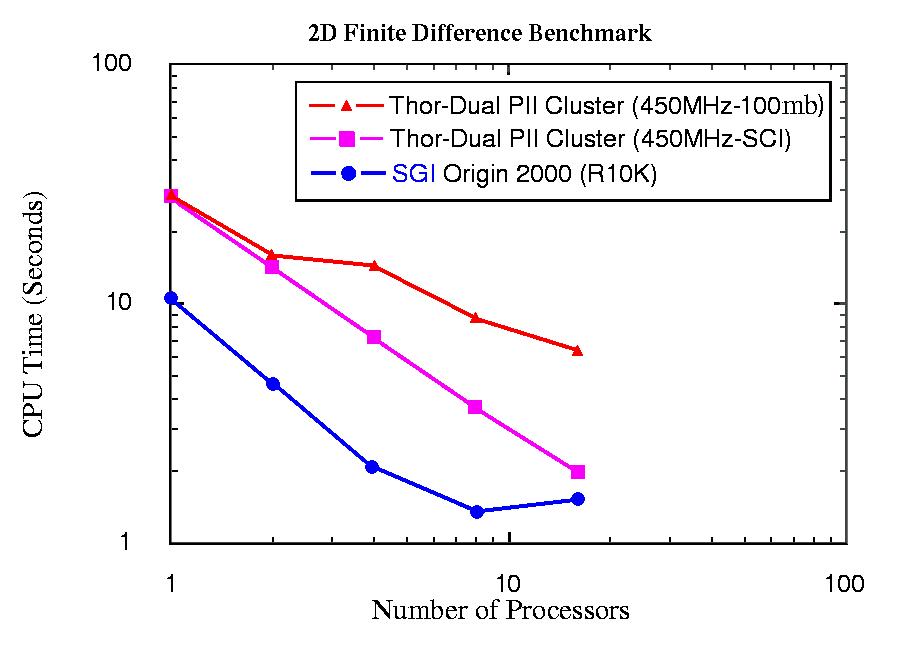
图4. 来自地震建模有限差分程序的基准测试结果
在过去的一年半中,THOR已从仅有的两台双奔腾II机器发展到超过40台双奔腾II/III机器。我们发现,维护和运行一个双节点阵列与运行一个40节点阵列没有太大区别。另一个令人欣慰的特点是THOR集群的可靠性,其他使用Beowulf型集群的团队也报告了这一点。自1999年3月以来,我们一直在运行PBS批处理排队系统,并且记录了超过80,000个CPU小时,只有一次系统故障是由于电源中断造成的,这促使我们为整个集群引入了不间断电源。另一个重要的发现是,THOR的构建和维护不需要一支高技能人员团队。我们发现,只需要“四分之一”个精通PC网络和Linux的人员即可实施该系统,Dolphin为SCI网络提供了一些初步帮助。此外,商品操作系统的使用允许在研究人员的桌面机器上开发程序,以便稍后在THOR上实施,从而简化了软件开发任务。
我们运行THOR的经验主要在三个领域:多串行蒙特卡罗(或令人尴尬的并行)生产作业、为ATLAS原型化事件过滤器子集群(使用为ATLAS高级触发系统开发的专用软件的时间关键型操作)以及作为完全并行处理器。当运行几乎不需要处理器间通信且网络不会成为瓶颈的应用程序时,大型Linux集群可能是最有效的。然而,许多需要完全并行机器进行大量消息传递的应用程序仍然将大部分时间用于计算。
由于并行计算是一个非常重要的主题,我们花了一些时间评估如何使用运行Linux的THOR多处理器来实现需要并行处理的应用程序。由于当前SMP Linux下对共享内存编程有很高的支持,因此我们已将THOR Linux集群与消息传递构造消息传递接口(MPI)一起使用。使用此编程模型有几个优点。例如,许多并行应用程序更多地受到浮点性能的限制,而不是受到处理器间通信的限制。因此,即使存在相对大量的消息传递,SCI甚至快速以太网也足够了。另一个优点是MPI是一个标准的编程接口,可以在许多并行计算机上运行,例如Cray T3系列、IBM SP系列、SGI Origin、Fujitsu和PC/Macintosh集群。因此,代码可以轻松地在平台之间移动。
参与等离子体物理研究的THOR小组之一开发了模拟程序,用于跟踪约1200万个带电粒子的运动。此代码的一部分利用了多维快速傅里叶变换。我们在THOR集群上为多达32个处理器(当时可用的所有处理器)实现了近乎完美的扩展性。遵循MPI模型的代码很容易从SGI Origin 2000平台转移到THOR Linux集群。如图3所示,此程序在THOR上的性能与其他平台相比。其他基准测试在图4中给出。在执行这些基准测试时,THOR仅由450MHz机器组成。
我们上述使用THOR Linux集群的经验表明,如果我们将机器的总成本除以处理器数量,那么每个处理器的成本约为1,500美元(加元)。假设应用合理的折扣,这比传统超级计算机便宜十倍以上。尽管在某些应用中传统超级计算机是不可替代的,但在性价比的基础上,THOR(或Beowulf)型多处理器更具吸引力。THOR Linux集群的另一个成本优势是软件成本低。GNU的编译器和调试器,以及免费的消息传递实现(MPI)和便携式批处理排队系统(PBS),没有年费,提供了良好的低成本解决方案。更好的编译器,包括FORTRAN90,例如Absoft产品,在MPI环境中提供了显着的性能增强和调试工具。
THOR Linux集群相对较小的前期成本与其低运行成本相匹配。我们的经验表明,至少对于像THOR这样大的机器而言,运行机器所涉及的人力成本很低。例如,THOR只需要大约30%的网络/Linux专家的时间。我们认为这是由于商品组件多处理器方法的可靠性、设计简单性和可访问性。可以在不重新启动任何机器的情况下动态地将新节点添加到THOR;此外,问题节点可以热插拔。节点是一台传统的PC,可能有一年的保修期,可以维修或丢弃。事实上,与大多数传统超级计算机生产商要求的年度维护费相比,THOR的硬件和软件维护成本已被证明是微不足道的。此类费用每年可能超过数万美元。像THOR这样运行Linux的Beowulf型集群的优势如此之多,以至于我们毫不奇怪越来越多的科学和商业用户正在采用这种方法。

James Pinfold (pinfold@phys.ualberta.ca) 是阿尔伯塔大学亚原子研究中心主任,也是THOR Linux集群(一个商品组件超级计算机项目)的负责人。他的主要研究工作在高能对撞机物理学领域,目前在瑞士日内瓦附近的欧洲核子研究中心(CERN)从事OPAL和ATLAS实验。
