
在 156GB PC 集群上模拟地震波传播
人口稠密地区的大地震可能是致命的,并对当地经济造成严重破坏。最近在萨尔瓦多(2001 年 1 月 13 日,震级 7.7 级)、印度(2001 年 1 月 26 日,震级 7.6 级)和西雅图(2001 年 2 月 28 日,震级 6.8 级)发生的地震说明需要更好地了解地震的物理原理,并促使人们尝试预测地震风险以及对建筑物和基础设施的潜在破坏。
地震期间强烈的地面震动受地震运动方程控制,该方程支持三种类型的波:压力波(或声波)、剪切波和表面波。数值技术可用于求解复杂三维 (3-D) 模型的地震波动方程。地震学中感兴趣的两类主要问题是:区域模拟(例如,地震多发的人口稠密的沉积盆地中的波传播,如洛杉矶或墨西哥城)以及整个地球尺度的地震波传播。每次发生地震时,全球数百个地震台站都会记录到这些波,并提供有关地球内部结构的有用信息。
在加州理工学院地震实验室,我们开发了一种高精度的数值技术,称为谱元法,用于模拟 3-D 地震波传播。该方法基于工程中广泛使用的经典有限元法。每个单元包含数百个点,在局部网格上求解地震波动方程,并将其计算结果传递给网格中的邻居。为了模拟地震波在地球中的传播,我们创建了一个地球网格,并将其划分为大量切片(见图 1 和图 2)。每个切片包含大量单元(通常为数万个)。我们的目标是在并行计算机上运行计算,因为网格的大小使得在共享内存机器或工作站上运行我们的应用程序成为不可能。因此,该方法非常适合在 PC 集群上实现,这样每台 PC 处理网格中所有单元的一个子集。我们使用消息传递技术在网络中的 PC 之间传递结果。这种 Linux 下并行处理的想法在科学界发展迅速(参见 M. Konchady 和 R. A. Sevenich 在“资源”中列出的文章)。
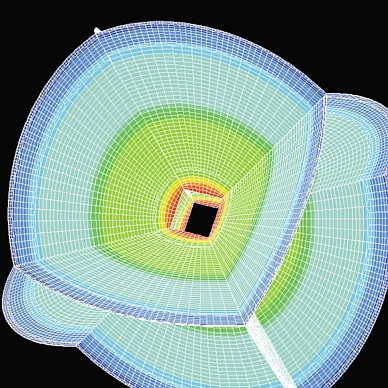
图 1. 地球网格

图 2. 分配给处理器的切片
关于如何将大型 PC 集群用于科学目的的研究始于 1994 年 NASA 的 Beowulf 项目 (beowulf.org),随后是加州理工学院的 Hyglac 项目和洛斯阿拉莫斯的 Loki 项目(参见 Tom Sterling 及其合作者的著作 如何构建 Beowulf 和 cacr.caltech.edu/resources/naegling)。普林斯顿大学的 Hans-Peter Bunge 是最早使用此类集群解决地球物理问题的人之一,而法国巴黎地球物理研究所的 Emmanuel Chaljub 提出了使用消息传递研究地球中波传播的想法。集群现在已在学术界和工业界的许多领域中使用。M. Lucas 在最近一期的 Linux Journal 上介绍了远程传感这个完全不同领域的应用(参见“资源”)。
对于我们的项目,我们决定从头开始使用标准 PC 零件构建集群。“COTS”(商用现成技术)这个缩写词通常用于描述这种方法。主要约束是我们需要大量的 PC 和大量的内存,因为我们想在模拟中使用大型网格。通信和 I/O 对我们来说不是大问题,因为 PC 大部分时间都在进行计算,并且 PC 之间交换的信息量始终相对较小。因此,我们的特定应用程序不会从使用高性能网络(如千兆以太网或 Myrinet)中获益太多。相反,我们使用了标准的 100Mbps 快速以太网。由于需要大量的处理器(总共 312 个),我们使用了双处理器主板来减少机箱数量至 156 个,从而最大限度地减少了存储所需的空间(以及集群的占地面积)。这种结构会影响性能,因为两个处理器共享内存总线(这会导致总线争用,但降低了硬件成本),因为两个处理器只需要一个机箱、主板、硬盘驱动器等。我们排除了机架式节点的选项,主要是为了降低成本,但选择在架子上使用标准中塔式机箱,如图 3 所示。这种方法有时被称为 LOBOS(“架子上有很多盒子”)。货架系统放置在已经配备了强大的空调系统和 156 台双处理器 PC 的计算机房中。

图 3. 156 台双处理器 PC 集群。这些盒子使用标准的 100Mbps 快速以太网网络连接(绿色和蓝色电缆)。在后面,可以看到 192 端口的思科交换机。货架系统的高度约为八英尺。
在奔腾 III 和 AMD Athlon 处理器之间做出决定很困难。据说 Athlon 在浮点运算方面速度更快,而浮点运算是大多数科学应用程序(包括我们的应用程序)中使用的主要运算类型。在构建时,没有双处理器 Athlon 主板可用。如上所述,使用单节点会增加集群的总成本。因此,我们选择了奔腾 III。
在组装 PC 时,很想使用最新技术。然而,新处理器的价格比六个月前的技术更贵,但性能提升幅度很小。三到六个月前的处理器在价格和性能之间提供了最佳的权衡。当我们在 2000 年夏天组装机器时,我们使用了 733MHz 的处理器。

图 4. 奔腾 III 的性价比
图 4 显示了奔腾 III 处理器的性价比。显示的价格是美国零售商的平均典型价格。可以看出,旧处理器便宜但相对较慢。新处理器速度更快,但价格贵得多。最佳性价比介于两者之间。
我们决定在主板上安装尽可能多的内存,即每个 PC 完全填充内存插槽,配备 1GB RAM,集群总内存为 156GB。每台 PC 也称为“节点”或“计算节点”。请注意,内存占集群总成本的 50% 以上。
其余硬件相当标准:每台 PC 都有一个快速 IDE 20GB 硬盘驱动器、一块快速以太网网卡和一块廉价的 1MB PCI 显卡,这是 PC 正常启动所必需的,并且可以在需要时用于监控节点。我们使用高质量的中塔式机箱,带有滚珠轴承机箱风扇,因为集群中的机械部件(如风扇和电源)最容易发生故障。请注意,集群中的总磁盘空间非常大(20GB × 156 = 3,120GB = 3TB)。为了进一步降低集群的成本并完全控制安装部件的质量,我们决定从不同的供应商订购零件并自己组装节点,而不是订购预组装的机箱。三个人花了一个星期左右的时间组装了整个结构。一台名为前端的 PC 在集群中扮演着特殊的角色:它包含用户的主文件系统(SCSI 驱动器通过 autofs 自动挂载在其他节点上)、编译器、消息传递库等等。模拟从此机器启动和监控。前端也用于登录节点进行维护。这些节点都使用思科的 192 端口 Catalyst 4006 交换机连接,该交换机的背板带宽为 24Gbps(见图 5)。

图 5. Catalyst 4006 思科交换机
集群中的所有节点都运行 Linux Red Hat 6.2。Linux 完全符合我们应用程序的需求;我们需要非常高的可靠性,因为该机器被需要运行作业的研究人员使用,他们不必担心节点崩溃。自该机器建成九个月以来,我们还没有发生过一次系统崩溃。需要调整操作系统以适应硬件,以便达到最佳性能;凭借开源理念,我们已经能够使用对应于我们硬件配置的最少选项重新编译内核。我们最近安装了 2.4.1 内核,它比 2.2 内核更好地支持双节点 SMP 机器。性能非常出色;通过从 2.2 切换到 2.4,我们应用程序的 CPU 时间减少了 25%。在网络配置方面,156 个节点位于 192.168.1.X 地址的私有网络上。出于安全原因,集群未连接到外部世界,所有结果的后处理和分析都在前端本地完成。我们每天在每个节点的 cron 表中使用 rdate 一次,以将时间与前端同步。
我们为使用 PC 集群付出的最大代价是将现有的串行代码转换为基于消息传递理念的并行代码。在我们的例子中,代价是巨大的,因为我们的小组由非专业程序员的研究人员组成。这种情况意味着我们不得不花费几个月的时间来修改数万行串行代码。消息传递理念的主要困难在于,需要确保控制节点(或主节点)在所有其他节点(计算节点)之间均匀地分配工作负载。由于所有节点都必须在每个时间步同步,因此每台 PC 都应在大致相同的时间内完成其计算。如果负载不均匀(或者负载平衡不良),PC 将在最慢的节点上同步,从而导致最坏的情况。另一个障碍是可能导致死锁的通信模式。一个典型的例子是,如果 PC A 正在等待接收来自 PC B 的信息,而 B 也正在等待接收来自 A 的信息。为了避免死锁,需要使用主/从编程方法。
我们使用 MPI(消息传递接口)库来实现消息传递。具体来说,我们安装了在 Argonne 国家实验室开发的开源 MPICH 实现(参见 W. Gropp 及其合作者 1996 年的文章,可在 www-unix.mcs.anl.gov/mpi/mpich 找到)。该软件包已被证明在 Linux 上非常可靠。MPI 正在成为并行计算社区的标准。MPI 的许多功能类似于 R. A. Sevenich 在 1998 年 1 月的 Linux Journal 文章中描述的旧版 PVM(并行虚拟机)库。
我们项目的另一个困难是我们必须处理的大量遗留代码。许多现代代码都基于包含 20 世纪 70 年代和 80 年代开发的遗留代码的库。几乎所有的科学库都是用 Fortran77 编写的,Fortran77 是当时的首选语言;C 语言的使用尚未普及。我们决定不将 40,000 多行代码转换为 C 语言,而是从 Fortran77 升级到现代 Fortran90。新版本具有动态内存分配、指针等功能,并且向后兼容 Fortran77。我们编写了一个 Perl 脚本来自动执行大部分转换,手动修复了一些细节并将内存分配从静态更改为动态。不幸的是,据我们所知,目前 Linux 下没有免费的 Fortran90 编译器可用。GNU g77 和 f2c 软件包仅支持 Fortran77。因此,我们不得不购买商业软件包,即来自 Portland Group 的 pgf90,pgroup.com。这是我们集群中唯一的非开源组件。
PC 集群的一个局限性是系统管理和维护问题。使用数百台 PC 会增加节点硬件或软件故障的可能性。在硬件问题的情况下,PC 的优点是零件是标准的,可以在几个小时内购买和更换。因此,与研究人员过去为经典超级计算机需要的昂贵维护合同相比,与维护相关的成本较低。
软件维护更是一个问题——拥有 156 个节点,如何确保它们都正常工作?如何安装新软件?如何监控正在运行的作业的性能?当我们安装集群时,我们编写了脚本,通过发送 rsh 命令从节点收集信息。从那时起,伯克利大学和 VA Linux 等公司开发了用于集群监控的高效软件包,并将其开源。我们使用来自 VA Linux (valinux.com) 的名为 SystemImager 的节点克隆软件包来进行软件升级。使用此软件包,我们只需要手动升级第一个节点。然后,该软件包使用 rsync 和 tftp 命令在几分钟内将更改复制(或克隆)到其他 155 个节点。为了监控集群和正在运行的作业,我们使用了伯克利的 Matt Massie 的 Ganglia 软件包 (millennium.berkeley.edu/ganglia),这是一个快速便捷的软件包,它使用守护进程系统将有关每个节点状态的信息发送到前端,并在前端收集和显示这些信息。
在图 6 中,我们展示了 Ganglia 软件包的 Tcl/Tk 界面。我们使用的 GUI 基于另一个开源软件包,即 Jacek Radajewski 的 bWatch (sci.usq.edu.au/staff/jacek/bWatch)。我们根据自己的需求对其进行了修改,并使用 Ganglia 而不是标准的 rsh 命令,以便更快地访问节点。此外,VA Linux 最近发布了 VACM 软件包(VA 集群管理),我们尚未安装该软件包。
图 6. 使用 Ganglia 监控
1994 年 6 月 9 日,玻利维亚发生了一场里氏震级 8.2 级的特大地震,震源深度为 641 公里(400 英里)。大多数地震发生在较浅的深度,通常小于 30 公里。玻利维亚的这次地震是有记录以来最大的深源地震之一。由于其不寻常的特性,这次地震已成为地震学界众多研究的主题。我们尝试在我们的集群上模拟此事件。
图 7 显示了地面震动的静止图像(地震产生的地震波通过时地球在给定位置的位移)。玻利维亚的震中用紫色三角形表示。波浪在地球内部和地表沿线传播。例如,可以看到它们在美国各地传播。在玻利维亚周围的地球表面可以看到永久位移,向北延伸至亚马逊河。这种效应被称为“静态偏移”,已被玻利维亚的几个地震台站记录下来。地震非常大,以至于永久性地移动了地面几毫米。垂直位移达到 7 毫米(即向南 ¼ 英寸)。我们的代码正确地再现了这一点。

图 7. 8.2 级玻利维亚地震期间的地震波
由于波浪在全球范围内传播,其他国家的地震记录台站也能够检测到玻利维亚地震。图 8 显示了来自加利福尼亚州帕萨迪纳台站的实际记录以及我们的方法模拟的相应记录。同样,两者吻合良好。在每个时间步,此模拟都需要求解具有 5 亿个未知数(也称为系统自由度)的方程组。在集群上使用一半的节点(150 个处理器)模拟地震发生后一个半小时的地震波传播花费了 48 小时。

图 8. 帕萨迪纳记录的垂直速度
毋庸置疑,我们的研究极大地受益于 Linux 的强大功能和可靠性以及开源理念。通过使用大型 PC 集群,我们能够模拟大型地震产生的地震波传播,并达到前所未有的分辨率。
Luis Rivera 为该项目提供了宝贵的信息和帮助。我们感谢 Jan Lindheim、Tom Sterling、Chip Coldwell、Ken Ou、Jay Nickpour 和 Genevieve Moguilny 就集群结构进行的讨论。Matt Massie 在他出色的 Ganglia 软件包中添加了几个选项,以帮助我们监控集群上的更多参数。Rusty Lusk 就如何在大型集群上运行 MPICH 提供了一些有用的见解。


