
将 Linux 集群集成到生产高性能计算环境
1999 年 8 月,俄亥俄超级计算机中心 (OSC) 与 SGI 达成协议,OSC 将购买一个由 33 台 SGI 1400L 系统(运行 Linux)组成的集群。这些系统将通过 Myricom 的 Myrinet 高速网络连接,并用作“打了兴奋剂的 Beowulf 集群”。该计划是使这个集群系统最终成为生产质量的高性能计算 (HPC) 系统,并作为 OSC、SGI、Myricom 和其他地方的研究人员进行集群软件开发的试验平台。
OSC 对集群并不陌生,早在 1995 年就构建了其第一个工作站集群(Beakers,八台运行 OSF/1 并通过 FDDI 连接的 DEC Alpha 工作站)。此外,MPI 的 LAM 实现始于 OSC,并在那里存放了多年。这甚至不是 OSC 的第一个 Linux 集群;Pinky,一个由五台双处理器 Pentium II 系统组成的小型集群,通过 Myrinet 连接,于 1999 年初构建,并在有限的基础上提供给 OSC 用户使用。然而,这个新的集群系统有所不同,因为它将被期望成为生产 HPC 系统,就像 OSC 的 Cray 和 SGI 系统一样。
新集群,昵称 Brain(以 Animaniacs 中 Pinky 更聪明的另一半命名),由 33 台 SGI 1400L 系统组成,每台系统配备四个 550MHz 的 Pentium III Xeon 处理器、2GB 内存、一个 10/100Mbps 以太网接口和一个 18GB UW-SCSI 系统磁盘。一个系统配置为前端或交互式节点,具有更多磁盘、第二个以太网接口和一个 800Mbps 高性能并行接口 (HIPPI) 网络接口。其他 32 个系统配置为计算节点,每个节点有两个 1.28Gbps Myrinet 接口。在每个系统中放置两张 Myrinet 卡的原因是为了增加节点之间可用的网络带宽;SGI 1400 系统有两个 33MHz 32 位 PCI 总线,因此每条 PCI 总线安装了一张 Myrinet 卡(一张 Myrinet 卡可以轻松饱和 33MHz 32 位 PCI 总线,因此在单条 PCI 总线中安装两张不是一个好主意)。最初,64 张 Myrinet 卡连接到由八个 16 端口 Myrinet 交换机组成的复杂排列中,旨在最大化平分带宽(如果一半网络端口同时尝试与另一半通信,则可用的带宽量),但在最终安装中,这些交换机被单个 64 端口 Myrinet CLOS-64 交换机取代。还购买了一个 48 端口 Cisco 以太网交换机,用于连接到每个系统中的以太网卡。这个以太网网络是私有的;从外部可访问集群的唯一网络接口是前端节点上的第二个以太网接口。
在集群中拥有三种不同的网络类型(以太网、Myrinet 和 HIPPI)似乎有点过分,但实际上每种网络都有充分的理由。以太网主要用于使用 TCP/IP 协议的系统管理任务。HIPPI 在前端用于高带宽访问海量存储(稍后详细介绍)。另一方面,Myrinet 旨在供使用 MPI 消息传递库的并行应用程序使用。对于 Brain 集群(以及它的前身 Pinky),使用的 MPI 实现是 Argonne 国家实验室的 MPICH。选择 MPICH 而不是 LAM 的原因是 Myricom 的开发人员为 MPICH 开发了一个 ch_gm 驱动程序,该驱动程序直接与 Myrinet 卡的 GM 内核驱动程序对话,完全绕过 Linux TCP/IP 堆栈,从而实现比 TCP/IP 更高带宽和更低延迟。还有其他几种 Myrinet 的 MPI 实现,例如 FM(快速消息传递)和 AM(主动消息传递),但这些实现似乎不如 MPICH/ch_gm 那样健壮或得到良好的支持。
该系统最初于 1999 年 10 月在加利福尼亚州山景城的 SGI HPC 系统实验室之一组装和测试。然后运往俄勒冈州波特兰,在那里它在 Supercomputing '99 会议的 SGI 展位上突出展示和演示。SC99 之后,该集群被拆除并运往 OSC 位于俄亥俄州哥伦布市的设施,在那里永久安装。
最终安装在占地面积、电力和冷却方面值得讨论。最终安装的集群由七个机架组成,六个机架各有五个 1400 节点,一个机架有三个 1400 节点、Myrinet CLOS-64 交换机、以太网交换机和控制台服务器(见图 1)。SGI 的一位现场计算机工程师 (CE) 估计,每个机架的重量约为 700 磅,他坚持要求加固安装集群区域的架空地板(为了说明这一点,唯一需要地板加固的 OSC 系统是 Cray T94,重约 3,800 磅)。每个 SGI 1400 单元都有三个额定功率为 400 瓦的冗余电源,总共需要安装 20 个 20 安培电路来供电。前端节点放置在 UPS 上,而计算节点放置在建筑电力上。发现房间的冷却效果足够;33 个 1400L 产生的热负荷最终与 OSC 的 Cray 系统和俄亥俄州立大学的主机的冷却要求相比微不足道,所有这些系统都安置在同一设施中。

图 1. 最终安装的集群
在 Brain 集群安装时,OSC 的其他 HPC 系统包括以下系统
mss:一台 SGI Origin 2000,配备八个 300MHz 的 MIPS R12000 处理器、4GB 内存、1TB 光纤通道 RAID,以及 IBM 3494 磁带库中约 60TB 的磁带,带有四个磁带驱动器
origin:一台 SGI Origin 2000,配备 32 个 300MHz 的 MIPS R12000 处理器和 16GB 内存
osca:一台 Cray T94,配备四个 450MHz 的定制向量处理器和 1GB 内存
oscb:一台 Cray SV1,配备 16 个 300MHz 的定制向量处理器和 16GB 内存
t3e:一台 Cray T3E-600/LC,配备 136 个 300MHz 的 Alpha EV5 处理器和 16GB 内存
后四个系统都使用 HIPPI 网络通过 NFS 从 mss 挂载其用户主目录。当集群安装时,其前端节点(称为 oscbw 或 node00)被添加到 HIPPI 网络(见图 2)。此外,为了让最终用户更容易将文件暂存到计算节点中,计算节点被配置为通过专用以太网挂载用户主目录,使用 mss 上以前未使用的以太网端口(见图 3)。
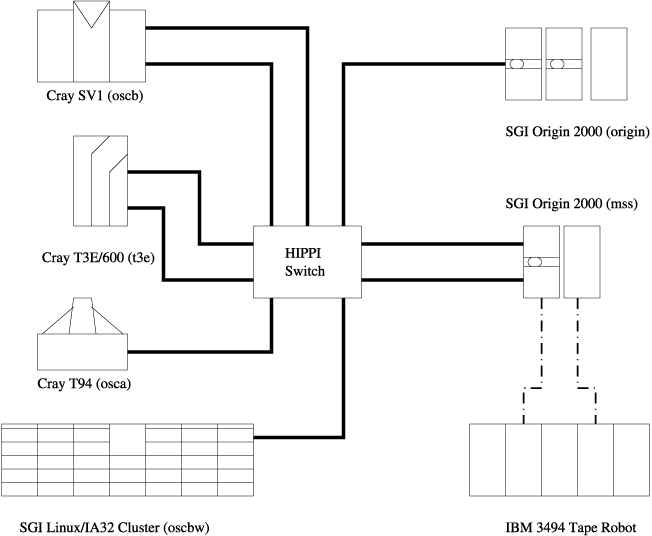
图 2. HIPPI 网络
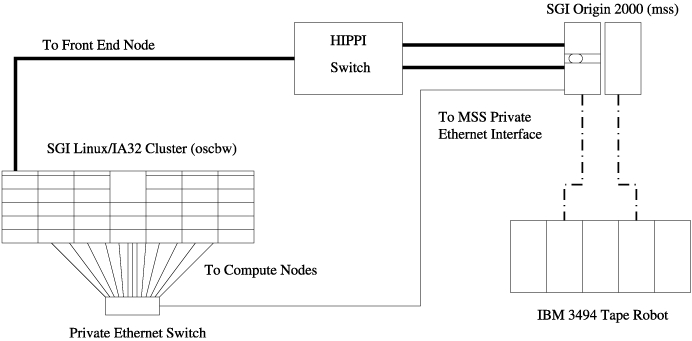
图 3. 通过专用以太网与 mss 联网的计算节点
这种安排遇到的一个困难涉及 Linux NFS 客户端实现和分层存储管理 (HSM) 之间的交互。mss 系统运行 SGI 的 HSM 产品,称为磁带迁移工具 (TMF)。TMF 定期扫描存储在选定文件系统(在本例中为用户的主目录)上的所有文件,查找长时间未访问过的大文件,因此可以将其迁移到 3494 磁带库中的磁带。当用户尝试读取已迁移到磁带的文件时,初始 read() 系统调用会阻塞,直到 TMF 能够将文件内容迁移回磁盘。不幸的是,Linux 2.2 NFS 客户端实现按 NFS 服务器而不是按文件系统对 NFS 文件读取进行排队,因此尝试读取迁移的文件通常会导致前端节点在从磁盘检索文件时锁定。
与 OSC 的其他 HPC 系统一样,Brain 集群代表了俄亥俄州各学术和工业机构研究人员共享的资源。选择 Portable Batch System (PBS) 2.2 版来处理集群上的资源管理和作业调度。此选择基于以下几个因素
之前的经验:在 Pinky 集群上使用了 PBS 2.0 版,此前曾与 Platform Computing 的 LSF 套件进行了广泛的比较。
大型站点的使用:许多大型 Linux 集群站点使用 PBS 作为其调度软件,包括 NASA Ames 的国家航空动力学模拟 (NAS) 设施,PBS 在那里开发。
源代码可用性:PBS 是一个开源产品,具有相当大的 Linux 支持,而 LSF 是闭源的,Platform 当时对在 Linux 下提供 LSF 的所有功能几乎没有兴趣。
成本:PBS 是免费提供的(尽管可以从 MRJ 获得支持合同),而 LSF 对于生产用途则会产生大量按处理器许可的成本。
PBS 2.2 版还有另一个功能,是对 2.0 版的重大改进:每个处理器分配集群节点。在 2.0 版中,PBS 将系统分类为可以是分时主机(例如,Cray 向量系统或大型 SMP),可以多任务处理多个作业,也可以是空间共享集群节点(例如,Beowulf 集群或 IBM SP 中的单处理器节点),只能分配给单个作业。PBS 2.2 使用“虚拟处理器”属性扩展了集群节点概念;具有多个虚拟处理器的集群节点可以分配多个作业,用户可以专门请求每个节点具有多个虚拟处理器的节点。
然而,PBS 需要进行一些调整才能使其按照 OSC 的管理员和用户在使用 Cray 系统上的 NQE 十年后所期望的批处理系统的方式工作。首先,每个作业都分配了一个唯一的工作目录(通过 $TMPDIR 环境变量访问)。编写了 PBS 作业序言和尾声脚本,以在作业开始时创建这些目录,并在作业结束时删除它们(见列表 1 和 2)。还在每个计算节点上的 /etc/profile.d 目录中添加了脚本,以在批处理作业中设置 $TMPDIR(见列表 3 和 4)。开发了一个分布式复制命令 pbsdcp,允许用户将文件复制到分配给其作业的每个节点上的 $TMPDIR,而无需预先知道将分配给他们哪些节点(见列表 5)。
为了方便使用图形程序(例如 Totalview 并行调试器),开发了一种从集群的专用网络内部进行远程 X 显示的机制。该机制依赖于 ssh 的 X 显示端口转发功能,以及 PBS 的交互式批处理作业功能。PBS 中的交互式作业就像普通的批处理作业一样,只是它运行交互式 shell 而不是 shell 脚本。借助 ssh 在前端节点上的 X 伪显示,可以使用一些非传统的 xauth 操作使 X 程序在集群的专用网络上运行(见列表 6 和 7)。
Brain 集群的目标应用程序是基于 MPI 的并行程序。为了提高这些程序的启动时间并使其 CPU 时间核算准确,MPICH 中基于 rsh 的 mpirun shell 脚本被替换为一个名为 mpiexec 的 C 程序,该程序使用 PBS 中的任务管理 API 在各个节点上启动 MPI 进程。该程序还允许用户指定其作业运行的 MPI 进程数,可以每个虚拟处理器一个、每个 Myrinet 接口一个或每个节点一个(有关示例,请参见列表 8)。OSC mpiexec 程序在 GNU GPL 下可用(详细信息请参见资源)。
根据使用的处理器数量和使用时长,向用户收取时间分配费用。对于 Brain 集群,在资源是空间共享的情况下,收费是通过将作业使用的挂钟时间乘以请求的处理器数量来完成的。PBS 提供了包含挂钟时间和使用的处理器记录的计费日志,这些日志由一个简短的 Perl 程序处理并插入到 OSC 的用户计费数据库中。(读者应记住,对于 OSC 系统的学术用途,不涉及金钱交易;研究人员只是根据对其研究计划的同行评审结果获得时间。)
我们非常注意确保集群上的交互式环境尽可能友好,并尽可能与其他 OSC 系统相似。集群的节点从 mss 挂载其主目录,就像其他系统一样。OSC 的 Cray 系统使用模块工具来动态修改环境变量,以指向不同版本的编译器、库和其他软件;集群节点被赋予了类似的功能,最初是在洛斯阿拉莫斯国家实验室开发的。此外,还从 Portland Group 购买了 C、C++、Fortran 77 和 Fortran 90 的完整编译器套件,以及调试器和分析工具。选择这些编译器是基于其出色的优化器,该优化器最初是为 Sandia 国家实验室的基于 Pentium Pro 的 ASCI Red TFLOPS 系统开发的。集群上提供了各种数值库,包括开源库(FFTw、PETSc 和 ScaLAPACK)和闭源库(NAG Fortran 和 C)。
Brain 集群相当独特的一个领域是并行性能分析。与 Cray T3E 等真正的超级计算机上可用的性能分析工具相比,Linux 下的性能分析工具在历史上一直相当原始。然而,OSC 工作人员能够获得或开发出 Brain 集群的体面的性能分析工具集合。对于串行(即非并行)代码的分析,安装了 GNU gprof 命令行分析器和 Portland Group 的 pgprof 图形分析器。对于基于 MPI 的并行代码的分析,MPICH 发行版提供了一个分析日志记录工具和一个名为 jumpshot 的基于 Java 的图形分析工具。最后,为了进行真正深入的性能分析,作者开发了一个用于硬件性能计数器数据的分析程序,称为 lperfex。
硬件性能计数器是内置于大多数现代微处理器中的一项功能,基于 P6 内核的 Intel 处理器(即 Pentium Pro、Pentium II、Pentium III、Celeron 和 Xeon 处理器)将它们作为特定于型号的寄存器的一部分。Erik Hendriks,最初的 Beowulf 程序员之一,现在在 Scyld Computing 工作,他开发了一个内核补丁和用户空间库来访问这些计数器。lperfex 使用这个库制作了一个命令行性能计数器界面,基于 SGI Origin 2000 系统上的 perfex 实用程序的示例。这个工具的优点是它不需要特殊的编译;它只是运行另一个程序并记录性能计数器数据(有关示例,请参见列表 9)。它也可以与 MPI 并行应用程序一起使用(有关列表 10,请访问 ftp://ftp.linuxjournal.com/pub/lj/listings/issue87/)。与 OSC mpiexec 程序一样,lperfex 在 GNU GPL 下可用。并行工具联盟的 PAPI instrumentation library 的最新版本也已作为 lperfex 发行版的一部分发布。
Brain 集群于 2000 年 2 月向友好用户开放,并在 OSC 用户社区中迅速获得了一小批忠实用户。令 OSC 工作人员有些失望的是,并非所有这些用户都对运行并行 MPI 应用程序感兴趣。许多人对运行较旧的计算化学代码(如 Amber 和 Gaussian 98)感兴趣,这两者都不支持 Myrinet 上的 MPI。在集群上运行的另一个相当新颖的应用程序是基因序列分析工具 NCBI BLAST,俄亥俄州立大学医学院人类癌症基因组学项目的研究员 Bo Yuan 博士使用该工具在大约一周的时间内注释了来自人类基因组数据集草案版本的约 60,000 个基因。虽然不是用 MPI 编写的,但 BLAST 通过使用 pthreads 和共享内存在一个节点上的四个处理器上并行运行,并且通过运行多个同时进行的作业(每个作业分析不同的序列)实现了进一步的并发。BLAST 使用的模式匹配算法主要是整数运算,并且发现 Brain 集群节点中的 Intel 处理器在性能上显着优于 OSC 的 Origin 2000 系统中的 MIPS 处理器(见图 4)。

图 4. BLAST 性能
一个在 Brain 集群的 Myrinet 网络上使用 MPI 的用户应用程序是俄亥俄州立大学物理系的 Greg Kilcup 博士编写的量子色动力学 (QCD) 代码。该代码模拟亚原子粒子中夸克的相互作用,并且是通信密集型的,每个进程大约每 200 次浮点运算发送一条小消息。此应用程序对 MPI 延迟和可用内存带宽非常敏感。在 Brain 集群上,MPI 延迟非常可接受(约 13 微秒),内存带宽成为主要的性能瓶颈。由于四个处理器共享一个 800MB/s 峰值内存管道,每个处理器被限制在约 150MB/s 的持续内存带宽。这限制了每个处理器的浮点性能约为 60 MFLOPS。每个节点使用两个处理器提高了持续内存带宽和每个处理器的浮点性能(见图 5),同时允许比每个节点仅使用一个处理器运行更高的处理器计数。

图 5. 每个节点使用两个处理器的性能
另一个在 Brain 集群上使用 Myrinet 上的 MPI 的用户代码是辛辛那提大学物理系的 Mark Jarrell 博士编写的凝聚态物理学的 Monte Carlo 模拟。此应用程序是“令人愉快地”(也称为“令人尴尬地”)并行的,这意味着它执行的通信非常少。然而,与上面描述的 QCD 代码一样,此代码对内存带宽非常敏感。此应用程序的最内层循环执行两个大(1,000 多个元素)数组的外部乘积。这往往会导致低 L2 缓存重用,从而增加了已经饱和的有限内存总线上的压力(见图 6)。与 QCD 代码一样,此应用程序的理想点是每个节点两个处理器。OSC 正在进行工作以尝试提高此应用程序的性能。

图 6. Jarrell 代码性能
总的来说,OSC 对迄今为止拥有的两个 Linux 集群非常满意,并且在中心看来,Linux 集群是高性能计算未来发展的主要方向之一。然而,Linux 在支持高性能计算方面还有许多可以改进的领域。从 OSC 的角度来看,其中最关键的可能是并行性能优于 NFS 的并行文件系统。这的主要用途是作业的临时存储;目前在 Brain 集群上通过在每个节点上都有一个 $TMPDIR 目录来处理,但全局可访问的暂存区域对用户来说会容易得多。目前 Linux 下有两个潜在的集群并行文件系统开源候选者:明尼苏达大学的 GFS 和克莱姆森大学的 PVFS(参见“Linux 集群的并行虚拟文件系统”,LJ 2000 年 12 月)。GFS 是一个基于光纤通道的日志式、无服务器存储区域网络 (SAN) 文件系统。它有望成为一个出色的执行者,其无服务器方面也极具吸引力。然而,在撰写本文时,GFS 代码正处于重新设计其锁定机制后的变动状态,并且大型拓扑结构所需的光纤通道交换机仍然相对昂贵。另一方面,PVFS 不需要特殊的硬件;实际上,它实现了跨多个 I/O 节点系统的 RAID-0(条带化)。PVFS 的主要缺点是它目前不支持数据冗余,因此如果 I/O 节点发生故障,并行文件系统可能会损坏。
可以改进高性能计算集群的开源解决方案的另一个领域是作业调度和资源管理。虽然 PBS 已被证明是资源管理的足够框架,但其默认调度算法仍有许多不足之处。幸运的是,PBS 的设计允许将第三方调度程序插入 PBS,以允许站点实施自己的调度策略。其中一个第三方调度程序是 Maui High Performance Computing Center 的 Maui Scheduler。OSC 最近在 PBS 之上实施了 Maui Scheduler,并发现它在作业周转时间和系统利用率方面比默认的 PBS 调度程序有了显着改进。然而,Maui Scheduler 的文档目前有点粗糙,尽管 Maui 的主要作者 Dave Jackson 对我们的问题非常积极响应。
Linux 用于高性能计算的第三个工作领域是进程检查点和重启。在 Cray 系统上,可以将正在运行的进程的状态写入磁盘,然后在重启后用于重启进程。Linux 集群的类似设施将是集群管理员的福音;然而,对于使用像 Myrinet 这样的网络的集群系统,由于 MPI 实现和网络硬件本身中存储的大量状态信息,因此很难实现。威斯康星大学的 Condor 和耶路撒冷希伯来大学的 MOSIX 等许多软件包支持 Linux 的进程检查点和迁移(参见“MOSIX:Linux 的集群负载平衡解决方案”,LJ 2001 年 5 月);然而,它们目前都不支持使用 Myrinet 网络的任意 MPI 进程的检查点。
OSC 集群未来发展的主要问题是将使用什么硬件平台。迄今为止,主要由于可用的丰富软件,一直使用基于 Intel IA32 的系统。然而,Intel 的 IA64 和 Compaq 的 Alpha 21264 都承诺比 IA32 具有大大提高的浮点性能。OSC 一直在试验 IA64 和 Alpha 硬件,目前的计划是在 2001 年初安装一个由双处理器 SGI Itanium/IA64 系统组成的集群,该集群通过 Myrinet 2000 连接。这引出了另一个问题:当旧的集群硬件退役时,您该怎么办?对于 Brain 集群,计划是在俄亥俄州的研究人员中举行拨款竞赛,以选择一些实验室,这些实验室将从 Brain 接收较小的节点集群。这将包括硬件和软件环境,条件是其他研究人员可以使用空闲周期。OSC 还在开发针对 Totalview 和 Portland Group 编译器等商业集群软件的全州许可计划,以使集群计算在俄亥俄州更加普及。

