
高可用 LDAP
随着组织添加应用程序和服务,集中身份验证和密码服务可以提高安全性,并减少管理和开发人员的麻烦。然而,将任何服务整合到单个服务器上都会产生可靠性问题。高可用性对于企业身份验证服务尤其重要,因为在许多情况下,当身份验证停止工作时,整个企业都会陷入停顿。
本文介绍了一种创建可靠的身份验证服务器集群的方法。我们使用 LDAP(轻型目录访问协议)服务器来提供可以被各种应用程序订阅的身份验证服务。为了提供高可用的 LDAP 服务器,我们使用了 Linux-HA 倡议的 heartbeat 软件包 (www.linux-ha.org)。
我们正在使用 OpenLDAP 软件包 (www.openldap.org),它是包括 Red Hat 7.1 在内的多个 Linux 发行版的一部分。Red Hat 7.1 附带 2.0.9 版本,当前的下载版本(截至撰写本文时)是 2.0.11。OpenLDAP 基金会成立的目的是“协作开发一个健壮的、商业级的、功能齐全的开源 LDAP 应用程序和开发工具套件”(来自 www.openldap.org)。OpenLDAP 1.0 版本于 1998 年 8 月发布。当前的 major 版本是 2.0,它于 2000 年 8 月底发布,并增加了 LDAPv3 支持。
LDAP,像任何优秀的网络服务一样,被设计为跨多个服务器运行。LDAP 使用两个主要特性:复制和引用。引用机制允许您将 LDAP 命名空间拆分到多个服务器上,并将 LDAP 服务器安排在层次结构中。LDAP 对于特定的目录命名空间只允许一个主服务器(见图 1)。

图 1. LDAP 对于每个命名空间允许一个主服务器。
复制由 OpenLDAP 复制守护进程 slurpd 驱动,它定期唤醒并检查主服务器上的日志文件以查找任何更新。然后,更新被推送到从服务器。读取请求可以由任何服务器响应;更新只能在主服务器上执行。对从服务器的更新请求会生成一个引用消息,其中给出了主服务器的地址。客户端有责任追逐引用并重试更新。OpenLDAP 没有内置的方法来跨复制的服务器分发查询;您必须使用 IP 喷射器/扇出程序,例如 balance。
为了实现我们的可靠性目标,我们将一对服务器集群在一起。我们可以在这些服务器之间使用共享存储,并维护数据的一个副本。但是,为了简单起见,我们选择使用无共享实现,其中每个服务器都有自己的存储。LDAP 数据库通常都很小,并且它们的更新频率很低。(提示:如果您的 LDAP 数据集确实很大,请考虑使用引用将命名空间划分为更小的部分。)无共享设置在重新启动故障节点时确实需要一些注意:任何新的更改都必须在重新启动之前添加到故障节点上的数据库中。稍后我们将展示这种情况的示例。
首先,让我们澄清一个小的混淆。大多数 HA(高可用性)集群都有一个系统保持活动功能,称为 heartbeat。Heartbeat 用于监视集群中节点的健康状况。Linux-HA (www.linux-ha.org) 组提供了名为 Heartbeat 的开源集群软件,这非常贴切。这种命名情况可能会导致一些混淆。(好吧,它有时会让我们感到困惑。)在本文中,我们将 Linux-HA 软件包称为 Heartbeat,并将一般概念称为 heartbeat。清楚了吗?
Linux-HA 项目始于 1998 年,是 Harald Milz 编写的 Linux-HA HOWTO 的衍生产品。该项目目前由 Alan Robertson 领导,并有许多其他贡献者。Heartbeat 0.4.9 版本于 2001 年初发布。Heartbeat 通过通信介质(通常是串行和以太网链路)监视节点健康状况。最好有多个冗余介质。每个节点都运行一个名为 heartbeat 的守护进程。主守护进程为每个 heartbeat 介质派生子读取和写入进程,以及一个状态进程。当检测到节点死亡时,Heartbeat 运行 shell 脚本以在辅助节点上启动或停止服务。按照设计,这些脚本使用与系统 init 脚本(通常在 /etc/init.d 中找到)相同的语法。默认脚本为文件系统、Web 服务器和虚拟 IP 故障转移提供。
从两台相同的 LDAP 服务器开始,可以使用几种配置。首先,我们可以进行“冷备”,其中主节点将具有虚拟 IP 和正在运行的服务器。辅助节点将处于空闲状态。当主节点发生故障时,服务器实例和 IP 将移动到冷节点。这是一个简单的设置来实现,但主服务器和辅助服务器之间的数据同步可能是一个问题。为了解决这个问题,我们可以改为在两个节点上配置具有活动服务器的集群。这样,主节点运行主 LDAP 服务器,辅助节点运行从实例。对主服务器的更新会立即通过 slurpd 推送到从服务器(图 2)。

图 2. slurpd 将更新从 LDAP 主服务器推送到 LDAP 从服务器。
主节点的故障使我们的辅助节点可用于响应查询,但现在我们无法更新。为了适应更新,在故障转移时,我们将重新启动辅助服务器并将其提升为主服务器位置(图 3)。
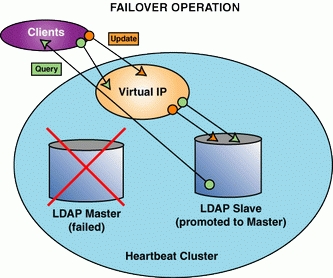
图 3. LDAP 从服务器重新启动为主服务器。
第二种配置为我们提供了完整的 LDAP 服务,但增加了一个陷阱。如果对辅助服务器进行了更新,我们将不得不在允许主服务器重新启动之前修复它。Heartbeat 支持一个很好的故障恢复选项,该选项禁止故障节点在故障转移后重新获取资源,这是一个更可取的选项。因此,我们将手动展示重新启动。我们的示例配置使用了 Heartbeat 提供的虚拟 IP 功能。
如果需要支持繁重的查询负载,则虚拟 IP 可以替换为 IP 喷射器,该喷射器将查询分发到主服务器和从服务器。在这种情况下,对从服务器发出的更新请求将导致引用。引用后续操作不是自动的,因此该功能必须构建到客户端应用程序中。主节点和从节点的配置相同,除了复制指令 [请参阅 LJ FTP 站点上的侧边栏,ftp.linuxjournal.com/pub/lj/listings/issue104/5505.tgz]。主配置文件指示复制日志文件的位置,并包含从服务器的列表,这些服务器是具有凭据信息的复制目标
replica host=slave5:389 binddn="cn=Manager,dc=lcc,dc=ibm,dc=com"; bindmethod=simple credentials=secret
从配置文件不指示主服务器。相反,它列出了复制所需的凭据
updatedn "cn=Manager,dc=lcc,dc=ibm,dc=com"
有很多关于 Heartbeat 基本配置的优秀示例可用(请参阅资源)。以下是我们配置中的相关部分。我们的配置非常简单,因此没有太多部分。默认情况下,所有配置文件都保存在 /etc/ha.d/ 中。
包含集群全局定义的 ha.cf 文件如下
# Timeout intervals keepalive 2 # keepalive could be set to 1 second here deadtime 10 initdead 120 # serial communications serial /dev/ttyS0 baud 19200 # Ethernet communications udpport 694 udp eth1 # and finally, our node ids # node nodename (must match uname -n) node slave5 node slave6
文件 haresources 是配置故障转移的地方。有趣的东西在文件的底部
slave6 192.168.10.51 slapd通过这一行,我们指示了三件事。首先,资源的主要所有者是节点 slave6(此名称必须与您打算作为主机的机器的 uname -n 的输出匹配)。其次,我们的服务地址,即虚拟 IP,是 192.168.10.51(此示例是在专用实验室网络上完成的,因此是 192.168 地址)。最后,我们指示服务脚本名为 slapd。因此,Hearbeat 将在 /etc/ha.d/resource.d 和 /etc/init.d 中查找脚本。
对于简单的冷备情况,我们可以使用标准的 /etc/init.d/slapd 脚本而无需修改。但是,我们想做一些特殊的事情,因此我们创建了自己的 slapd 脚本,该脚本存储在 /etc/ha.d/resource.d/ 中。[该脚本本身可从 Linux Journal FTP 站点获得,网址为 ftp.linuxjournal.com/pub/lj/listings/issue104/5505.tgz。] Heartbeat 将此目录放在其搜索路径中的首位,因此我们不必担心 /etc/init.d/slapd 脚本会被运行。但是,您应该检查以确保 slapd 不再在启动时启动(从您的 /etc/rc.d 树中删除任何 S*slapd 文件)。
在启动脚本中,我们为 slapd 服务器指示了两个不同的启动配置文件,允许我们将机器启动为主服务器或从服务器。当脚本运行时,它首先停止当前正在运行的任何 slapd 实例。然后,如果主节点和辅助节点都已启动,如果我们正在主节点上运行,则启动 slapd 作为主服务器,或者如果我们正在辅助节点上运行,则启动 slapd 作为从服务器。如果只有一个节点启动,无论我们正在哪个节点上运行,我们都启动 slapd 作为主服务器。我们这样做是因为虚拟 IP 与 slapd 主服务器绑定。
为了实现这一点,我们必须知道哪个节点正在执行脚本。如果我们是主节点,我们还需要知道辅助节点的状态。重要信息在脚本的“start”分支中。因为我们在 Heartbeat 配置中指示了主节点,所以我们知道当 test_start() 函数运行时,它正在 Heartbeat 主节点上运行。(因为 Heartbeat 使用 /etc/init.d/ 脚本,所以所有脚本都使用参数 start|stop|restart 调用。)
在调用脚本时,Heartbeat 设置了许多环境变量。我们感兴趣的一个是 HA_CURHOST,它的值为 slave6。我们可以使用 HA_CURHOST 值来告诉我们何时在主节点 slave6 上执行,以及何时处于故障转移状态(HA_CURHOST 将是 slave5)。
现在我们需要知道另一个节点的状态,所以我们询问 Heartbeat。我们将使用提供的 api_test.c 文件并创建一个简单的客户端来询问节点状态。(api_test.c 文件使用客户端做了更多的事情;我们只是删除了我们不需要的部分,并添加了一个输出语句。)编译后,我们将其安装在 /etc/ha.d/resource.d/ 中,并将其命名为 other_state。
我们现在可以在两台服务器上启动 Heartbeat。Heartbeat 文档包含一些关于测试基本设置的信息,因此我们不会重复这些信息。使用两个 heartbeat 介质,以太网和串行连接,您应该看到六个 heartbeat 进程正在运行。为了验证故障转移,我们进行了多次测试。为了提供用于测试的客户端,我们创建了一个简单的 KDE 应用程序,该应用程序查询服务器并显示连接状态。在这种情况下,真正的客户端将仅查询虚拟 IP,但为了说明目的,我们查询所有三个 IP。我们在此测试中每小时发送 10,000 个查询(图 4)。

图 4. S6(主服务器)和 S5(备用服务器)都在运行。
S6 是我们的主 LDAP 服务器,图 4 显示 S5 是活动的备用服务器。虚拟 IP 是下方的框。在正常状态下,S5 和 S6 都显示绿色,表示查询成功。
我们通过停止主节点上的 heartbeat 进程来开始测试。在这种情况下,从机器在十秒节点超时发生后获取资源,如日志摘录所示。接管包括启动脚本内的两秒额外延迟(图 5)。
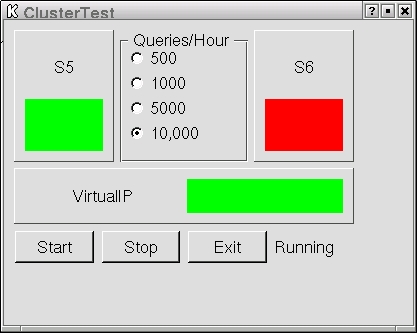
图 5. 当主服务器关闭时,辅助服务器接管虚拟 IP 地址。
当主服务器关闭时,虚拟 IP 由辅助服务器提供服务,如图 5 所示。S5 和虚拟 IP 显示绿色;服务器 S6 不可用,指示器为红色。重新启动集群后,我们通过断开主节点的电源来创建故障。同样,资源在十秒超时到期后被辅助节点获取。
最后,我们通过拔下串行和以太网接口来模拟两个节点之间互连的完全故障。这种节点间通信的丢失导致两台机器都试图充当主节点。这种情况被称为“脑裂”。在这种情况下,Heartbeat 的默认行为显示了为什么它需要使用单独介质的多个互连介质。在共享存储设置中,存储互连也可以用作 heartbeat 介质,这降低了脑裂的可能性。
在选择超时值时应考虑此问题。如果超时时间太短,负载过重的系统可能会错误地触发接管,从而导致明显的脑裂关闭。有关此问题的更多信息,请参阅 Linux-HA FAQ 文档。
如果在主 LDAP 服务器关闭时对 LDAP 命名空间进行了更新,则必须在重新启动主服务器之前重新同步 LDAP 数据库。有两种方法可以做到这一点。如果可能发生服务中断,则可以在停止 LDAP 服务器后手动复制数据库。(数据文件默认保存在 /usr/local/var 中。)
您还可以使用 OpenLDAP 复制来恢复数据库,而不会中断服务。首先,在前主节点上启动 LDAP 服务器作为从服务器。然后在当前主服务器上启动 slurpd。在前主服务器停止服务期间收到的更改将从新主服务器推送。最后,停止前主节点上的从 LDAP 服务器,并启动 Heartbeat。这将导致故障恢复到原始配置。
本文概述了一个使用开源软件创建一些高可用性基本网络服务的简单示例。包括 LDAP 在内的网络服务很少需要大型服务器。集群提供的额外可靠性以及服务器和数据文件的重复可以提高整体服务可用性。该系统在所有测试下都工作正常,所有情况下的故障转移时间都少于 15 秒。如果对系统负载和利用率有很好的了解,则可以将故障转移时间减少到低于此阈值。
以上文章基于在实验室环境中进行的实验室测试。特定客户安装中的结果可能会因多种因素而异,包括每个特定安装中的工作负载和配置。因此,以上信息按“现状”提供。特此声明对适销性和特定用途适用性的保证。使用此信息的风险由用户自行承担。



