
降低 Linux 中的延迟:引入可抢占内核
性能衡量有两种形式:吞吐量和延迟。前者就像高速公路的宽度:高速公路越宽,可以行驶的车辆就越多。后者就像速度限制:速度越快,车辆从 A 点到 B 点的时间就越短。显然,这两个量对于任何任务都很重要。然而,许多工作对其中一种质量的要求高于另一种。继续我们的道路类比,长途货运可能对吞吐量更敏感,而快递服务可能对延迟要求更高。通过良好的传统内核工作来降低延迟和提高系统响应速度是本文的主题。
音频/视频处理和播放是降低延迟的两个常见受益者。然而,对 Linux 而言,越来越重要的是它对交互性能的好处。在高延迟的情况下,用户操作(如鼠标点击)会被忽略太久——这不是用户期望的快速响应的桌面。系统无法足够快地处理重要的进程。
至少就内核而言,问题在于内核本身的不可抢占性。通常,如果发生足够重要的事情,例如交互事件,接收应用程序将获得优先级提升,并随后发现自己在运行。这就是抢占式多任务操作系统的工作方式。应用程序运行直到它们用完一些默认的时间量(称为时间片),或者直到发生重要事件。另一种选择是协作式多任务处理,在这种处理方式中,应用程序必须明确地说“我完成了!”,然后才能运行新进程。当在内核中运行时,问题是调度实际上是协作式的。
应用程序在两种模式之一中运行:要么在用户空间中执行自己的代码,要么在内核中执行系统调用或以其他方式让内核代表它们工作。当在内核中运行时,进程会继续运行,直到它决定停止,忽略时间片和重要事件。如果一个更重要的进程变为可运行状态,则它必须等到当前进程(如果在内核中)退出后才能运行。这个过程可能需要数百毫秒。
解决延迟问题的第一个也是最简单的解决方案是重写内核算法,使其花费最少且有界的时间量。问题在于这已经是目标;系统调用被编写为快速返回到用户空间,但我们仍然存在延迟问题。有些算法根本无法很好地扩展。
第二个解决方案是在整个内核中插入显式的调度点。低延迟补丁采用了这种方法,它在内核中找到问题区域,并插入类似于“有人需要运行吗?如果需要,就运行!”的代码。这种解决方案的问题在于,我们不可能希望找到并修复所有问题区域。尽管如此,测试表明这些补丁做得很好。然而,我们需要的是解决问题本身的方案,而不是权宜之计。
一个合适的解决方案是通过使内核可抢占来完全消除问题。因此,如果需要运行更重要的内容,它将运行,而不管当前进程正在做什么。这里的障碍,以及 Linux 从一开始就没有这样做的原因,是内核需要是可重入的。值得庆幸的是,抢占问题已通过现有的 SMP(对称多处理)支持得到解决。通过利用 SMP 代码,并结合其他一些简单的修改,内核可以变得可抢占。
MontaVista 的程序员提供了内核抢占的初始实现。首先,自旋锁的定义被修改为包含标记“不可抢占”区域。因此,我们在持有自旋锁时不会抢占,就像在 SMP 下我们不会并发进入锁定区域一样。当然,在单处理器系统上,我们实际上并没有使自旋锁成为除抢占标记之外的任何东西。其次,修改了代码以确保我们不会在 bottom half 或调度程序本身内部进行抢占。最后,修改了从中断代码路径返回的代码,以便在需要时重新调度当前进程。
在 UP 上,spin_lock 定义为 preempt_disable,spin_unlock 定义为 preempt_enable。在 SMP 上,它们也执行正常的锁定。那么这些新例程有什么作用呢?
可嵌套的抢占标记 preempt_disable 和 preempt_enable 对 preempt_count 进行操作,preempt_count 是存储在每个 task_struct 中的新整数。preempt_disable 实际上是
++current->preempt_count; barrier();
而 preempt_enable 是
--current->preempt_count;
barrier();
if (unlikey(!current->preempt_count
&& current->need_resched))
preempt_schedule();
结果是当计数大于零时我们不会抢占。由于自旋锁已经到位以保护 SMP 机器的关键区域,因此可抢占内核现在也具有其保护。preempt_schedule 实现了对 schedule 自身的入口。它在当前进程中设置一个标志以表示它被抢占,调用 schedule,并在返回时取消设置该标志
asmlinkage void preempt_schedule(void)
{
do {
current->preempt_count += PREEMPT_ACTIVE;
schedule();
current->preempt_count -= PREEMPT_ACTIVE;
} while (current->need_resched);
}
preempt_schedule 的另一个入口是通过中断返回路径。当中断处理程序返回时,它会检查 preempt_count 和 need_resched 变量,就像 preempt_enable 所做的那样(尽管 entry.S 中的中断返回代码是用汇编编写的)。理想的情况是在此处引起抢占,因为通常是中断由于硬件事件而设置 need_resched。然而,并非总是可以立即从中断中抢占,因为可能持有锁。这就是为什么我们还要检查 preempt_enable 的抢占。
因此,通过可抢占内核补丁,我们可以尽快重新调度需要运行的任务,而不仅仅是在它们位于用户空间时。结果是什么?
在某些情况下,进程级响应提高了二十倍。(参见图 1,标准内核,与图 2,可抢占内核。)这些图表是 Benno Senoner 的实用延迟测试工具的输出,该工具模拟负载下音频样本的缓冲。图中的红线表示超过该延迟量,人类可以感知到音频丢失。请注意图 1 中的图表中的多个峰值,而图 2 中的图表则平滑且低。
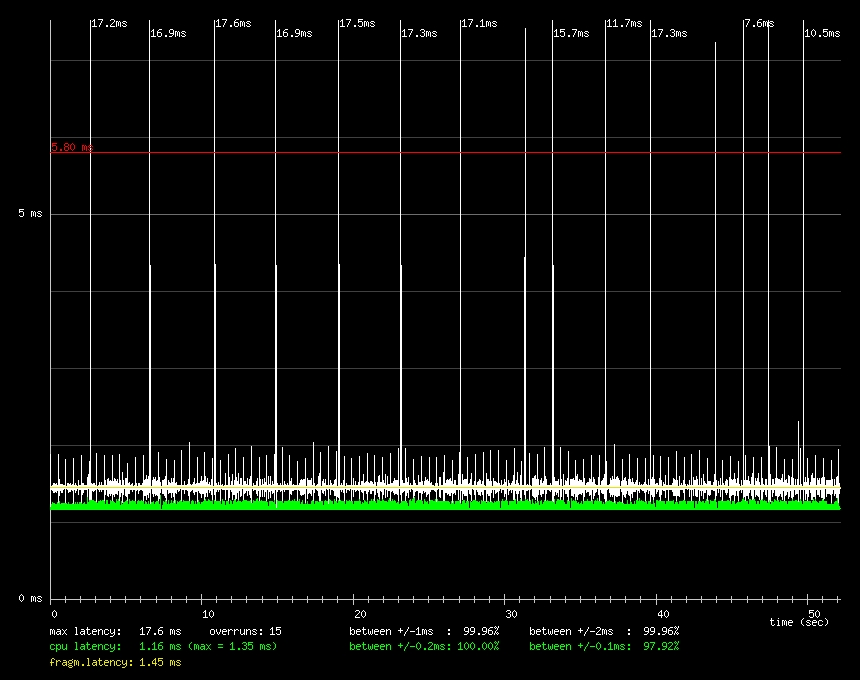
图 1. 标准内核上的延迟测试基准测试结果
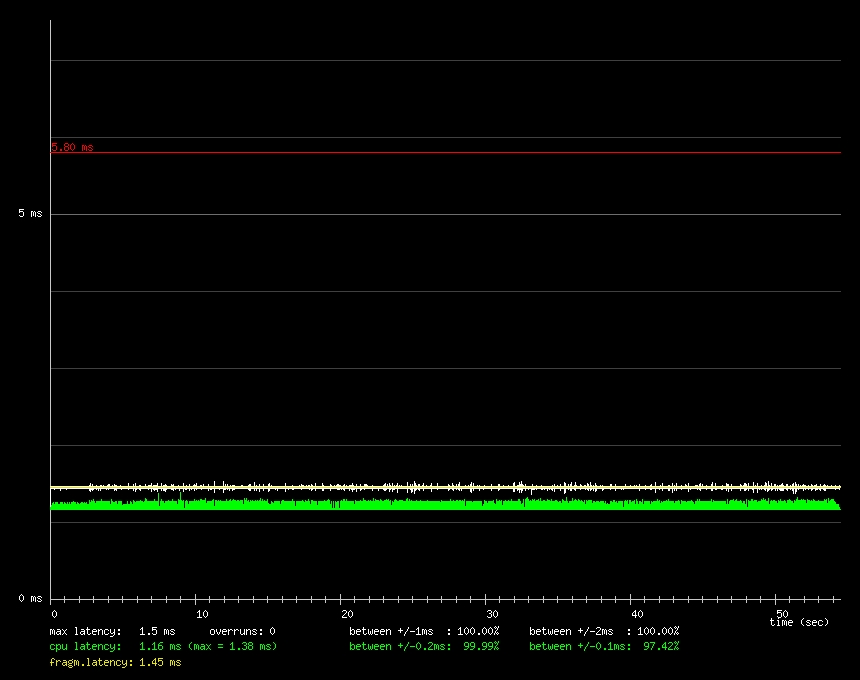
图 2. 可抢占内核上的延迟测试基准测试结果
latencytest 的改进对应于最坏情况和平均延迟的减少。进一步的测试表明,在一系列工作负载下的平均系统延迟现在在 1-2 毫秒范围内。
对可抢占内核的常见抱怨集中在增加的复杂性上。反对者认为,复杂性会降低吞吐量。幸运的是,可抢占内核补丁在许多情况下提高了吞吐量(见表 1)。理论是,当 I/O 数据可用时,可抢占内核可以更快地唤醒 I/O 绑定进程。结果是更高的吞吐量,这是一个不错的额外好处。最终结果是更流畅的桌面、负载下更少的音频丢失、更好的应用程序响应以及对高优先级任务的改进的公平性。
内核黑客可能会想,“这会如何影响我的代码?” 如上所述,可抢占内核利用了现有的 SMP 支持。这使得可抢占内核补丁相对简单,并且对编码实践的影响相对较小。但是,需要进行一项更改。目前,每个 CPU 数据(每个 CPU 唯一的数据结构)不需要锁定。因为它们对每个 CPU 都是唯一的,所以另一个 CPU 上的任务无法破坏第一个 CPU 的数据。但是,通过抢占,同一 CPU 上的进程可能会发现自己被抢占,然后第二个进程可能会践踏第一个进程的数据。虽然这通常受到现有 SMP 锁的保护,但每个 CPU 数据不需要锁。由于其性质而受到保护的数据被认为是“隐式锁定”的。隐式锁定的数据和抢占不兼容。值得庆幸的是,解决方案很简单:在访问数据时禁用抢占。例如
int catface[NR_CPUS];
preempt_disable();
catface[smp_processor_id()] = 1; /* index catface
by CPU number */
/* operate on catface */
preempt_enable();
当前的抢占补丁为内核中现有的隐式锁定数据提供了保护。值得庆幸的是,这种情况相对较少。但是,如果新的内核代码在可抢占内核中使用,则将需要保护。
我们还有工作要做。一旦内核可抢占,就可以开始减少长时间持有的锁的持续时间。由于在持有锁时内核是不可抢占的,因此锁的持续时间对应于系统的最坏情况延迟。有益于 SMP 可扩展性(更细粒度的锁定)的相同工作将降低延迟。我们可以重写算法和锁定规则,以最大限度地减少锁持有时间。消除 BKL 也将有所帮助。
识别长时间持有的锁可能与重写它们一样困难。幸运的是,有一个 preempt-stats 补丁,可以测量不可抢占时间并报告其原因。此工具对于查明特定工作负载(例如,Quake 游戏)的延迟原因非常有用。
需要的是一个目标。内核开发人员需要将任何超过某个阈值的锁持续时间视为错误,例如,在相当现代的系统上为 5 毫秒。考虑到这个目标,我们可以查明并最终消除高延迟和锁争用区域。
Linux 社区庞大而多样化,Linux 的应用范围从嵌入式系统到大型服务器。抢占式内核技术提供的优势超越了实时应用程序。桌面用户、游戏玩家和多媒体开发人员都将从降低的延迟中受益。2.4 和 2.5 内核树都需要解决方案;也许每个内核树的最佳解决方案不是相同的。然而,随着 2.5 的开发,现在是实施一项既能提供立竿见影的效果,又能为进一步改进提供框架的功能的时候了。结果将是一个更好的内核。

