
Linux 数据包过滤器内幕,第二部分
在上期中,我们开始跟踪数据包从线路到网络堆栈更高层处理的旅程。我们将数据包停留在第 3 层处理的末尾,此时 IP 已经完全完成了它的工作,并将把数据包传递给 TCP 或 UDP。在本文中,我们将完成我们的分析,考虑第 4 层、PF_PACKET 协议实现和套接字过滤器挂钩。
除了在内核中处理的 IGMP 和 ICMP 处理之外,数据包朝向应用程序的旅程通过 tcp_v4_rcv() 或 udp_rcv() 进行。 TCP 处理有点复杂,因为此协议的 FSM(有限状态机)必须处理许多中间状态(只需考虑 TCP 套接字可以承担的各种状态:监听、已建立、已关闭、等待等等)。为了简化我们的描述,我们可以将其简化为以下步骤
在 tcp_v4_rcv() (net/ipv4/tcp_ipv4.c) 中,执行 TCP 报头完整性检查。
查找愿意接收此数据包的套接字(使用 __tcp_v4_lookup())。
如果未找到,则采取适当的操作(其中包括,导致 IP 生成 ICMP 错误)。
否则,调用 tcp_v4_do_rcv(),将数据包 (sk_buff) 和套接字 (sock 结构) 都传递给它。
在此后一个函数内部,根据套接字当前状态执行不同的接收操作。
从 LSF 的角度来看,TCP 处理中最有趣的方面出现在我们提到的最后一个函数中;在其最开始,tcp_v4_do_rcv() 调用 sk_filter(),正如我们将看到的,它执行所有与过滤器相关的魔法。内核如何知道它应该为在给定套接字上接收的数据包调用过滤器?此信息存储在与套接字关联的 sock 结构内部。如果已使用 setsockopt() 系统调用将过滤器附加到套接字,则结构内部的相应字段不为 NULL,并且 TCP 接收函数知道它必须调用 sk_filter()。
对于那些精通套接字编程并记得监听 TCP 套接字在接收到连接消息时被 fork 的人来说,必须说明过滤器首先附加到监听套接字。然后,当建立连接并将新套接字返回给用户时,过滤器将被复制到新套接字中。有关详细信息,请参阅 net/ipv4/tcp_minisocks.c 中的 tcp_create_openreq_child()。
回到数据包接收。在过滤器运行之后,数据包的命运取决于过滤器结果;如果数据包与过滤器规则匹配,则处理照常进行。否则,数据包将被丢弃。此外,过滤器可以指定将保留用于进一步处理的最大数据包长度(超出部分将通过 skb_trim() 剪切)。
数据包的行程根据套接字当前状态在不同的路径上进行;如果连接已建立,则数据包将传递给 tcp_rcv_established() 函数。此函数的重要任务是处理复杂的 TCP 确认机制和报头处理,这当然与这里不太相关。唯一有趣的一行是对属于当前 sock (sk) 的 data_ready() 函数的调用,通常指向 sock_def_readable(),它使用 wake_up_interruptible() 唤醒接收进程(在套接字上接收的进程)。
幸运的是,UDP 处理要简单得多; udp_rcv() 仅在选择接收 sock (udp_v4_lookup()) 并调用 udp_queue_rcv_skb() 之前执行一些完整性检查。如果未找到 sock,则数据包将被丢弃。
后一个函数调用 sock_queue_rcv_skb()(在 sock.h 中),它将 UDP 数据包排队到套接字的接收缓冲区中。如果缓冲区上没有更多空间,则数据包将被丢弃。过滤也由此函数执行,它像 TCP 一样调用 sk_filter()。最后,调用 data_ready(),UDP 数据包接收完成。
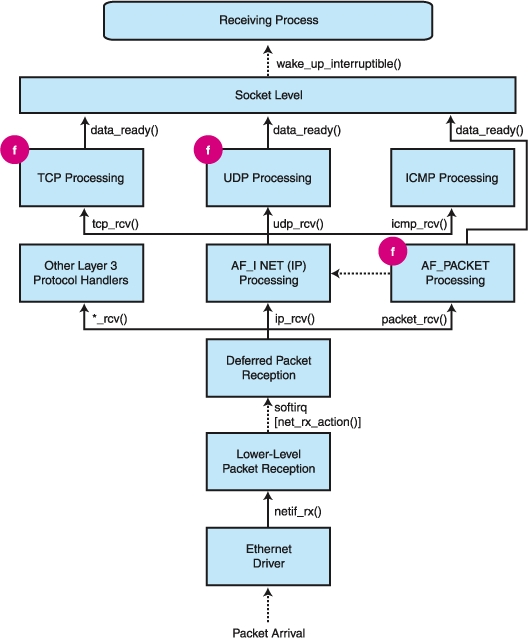
图 1. 完整接收路径,包含功能块和相关函数调用
PF_PACKET 族值得特殊处理。数据包必须直接发送到应用程序的套接字,而无需由网络堆栈处理。鉴于我们在前面章节中概述的数据包处理机制,这实际上并不是一项困难的任务。
当创建 PF_PACKET 套接字时(请参阅 net/packet/af_packet.c 中的 packet_create()),新的协议块被添加到 NET_RX softirq 使用的列表中。与此协议族相关的数据包类型被放置在通用列表 (ptype_all) 或协议特定的列表 (ptype_base) 中,并将 packet_rcv() 作为接收函数。出于稍后将清楚的原因,新创建的 sock 的地址被写入数据包类型数据结构内部。此地址在逻辑上不属于内核的这一部分,因为通常套接字信息由第 4 层代码处理。因此,在这种情况下,它被作为私有不透明信息写入正在注册的协议块的数据字段中——结构内部为协议特定的机制保留的字段。
从那时起,每个进入机器并经过通常的接收过程的数据包将在 net_rx_action() 执行期间被拦截,并传递给 PF_PACKET 接收函数。
此函数做的第一件事是尝试恢复链路层报头,如果套接字类型是 SOCK_RAW(回想一下我在 2001 年 6 月的 LJ 文章“Linux 套接字过滤器:嗅探网络上的字节”中提到的,SOCK_DGRAM 套接字将看不到链路层报头)。此报头已被网卡(或接收数据包的任何其他通用链路层设备)或其驱动程序(中断处理程序)移除。在处理以太网卡时,几乎总是后一种情况。如果移除发生在硬件级别,则无法恢复链路层报头,因为该信息永远不会进入系统主内存,并且在网络设备外部不可见。由于内核内部 skbuff 的智能处理,报头恢复的计算成本非常低。
下一步是检查是否已将过滤器附加到接收套接字。这部分有点棘手,因为过滤器信息存储在 sock 结构内部,而我们尚不知道 sock 结构,因为我们位于协议栈的底部。但是对于 PF_PACKET 套接字,它必须能够跳过协议栈,因此必须 先验 知道接收 sock 结构地址。这解释了为什么在套接字创建阶段,sock 结构的地址被不透明地写入协议块的私有数据字段中;这提供了一种相对干净的方式,以便在数据包接收期间检索该信息。
有了 sock 结构,内核就能够确定是否存在过滤器并调用它(通过 sk_run_filter() 调用)。像往常一样,过滤器将决定数据包的命运是丢弃 (kfree_skb())、修剪到给定长度 (pskb_trim()) 还是按原样接受。
如果数据包未被丢弃,则下一步包括克隆包含数据包的 sk_buff。此操作是必要的,因为一个副本将被 PF_PACKET 协议消耗,而另一个副本必须可用于稍后可能执行的合法协议。例如,想象一下运行一个程序,该程序在同时浏览 Web 的机器上打开一个 PF_PACKET 套接字。对于属于 Web 连接的每个数据包,net_rx_action() 函数将在调用正常的 IP 例程之前调用 PF_PACKET 处理例程。在这种情况下,将需要数据包的两个副本:一个用于合法的接收套接字,它将转到 Web 浏览器,另一个用于 PF_PACKET,它将转到嗅探器。请注意,数据包仅在被过滤器处理后才被复制。这样,只有实际匹配过滤器规则的数据包才会占用 CPU。另请注意,在应用程序级别执行的数据包过滤(即,使用没有套接字过滤器的 PF_PACKET)将需要克隆内核接收的所有数据包,从而导致性能不佳。幸运的是,数据包克隆仅涉及复制 sk_buff 的字段,而不复制数据包数据本身(数据包数据在克隆和原始 sk_buff 中由同一指针引用)。
PF_PACKET 接收函数最终通过调用接收套接字上的 data_ready() 函数来完成其工作,就像 TCP 和 UDP 处理函数所做的那样。此时,在 recv() 或 recvfrom() 系统调用上休眠的应用程序被唤醒,数据包接收完成。
作为旁注,您可能想知道,当用户进程调用 recv()、recvfrom() 或 recvmesg() 系统调用时,它是如何进入在给定套接字上休眠状态的?该机制实际上非常简单:所有 recv 函数都在内核内部通过或多或少直接调用 sock_recvmsg()(在 net/socket.c 中)来实现。此函数又调用在 sock 结构内部的协议特定操作中注册的 recvmsg() 函数。例如,在 PF_PACKET 协议的情况下,此函数是 packet_recvmsg()。
协议特定的 recvmsg 函数,除其他外,迟早会调用 skb_recv_datagram(),这是一个通用的函数,用于处理所有协议的数据报接收。后一个函数通过调用 wait_for_packet()(在 net/core/datagram.c 中)来获得进程阻塞,它将进程状态设置为 TASK_INTERRUPTIBLE(即,休眠任务)并将其排队到套接字的休眠队列中。进程在那里休眠,直到如我们在前面段落中看到的那样,通过新数据包的到达触发对 wake_up_interruptible() 的调用。
主要的过滤器实现在 core/filter.c 中,而 SO_ATTACH/DETACH_FILTER ioctl 在 net/core/sock.c 中处理。过滤器最初通过 sk_attach_filter() 函数附加到套接字,该函数将其从用户空间复制到内核空间,并对其运行完整性检查 (sk_chk_filter())。检查旨在确保过滤器解释器不执行不一致的代码。最后,过滤器基地址被复制到 sock 结构的过滤器字段中,正如我们之前看到的那样,它将在那里用于过滤器调用。
数据包过滤器本身在 sk_run_filter() 函数中实现,该函数被赋予一个 skb(当前数据包)和一个过滤器程序。后者只是一个 BPF 指令数组(请参阅资源),它是一系列数字操作码和操作数。 sk_run_filter() 函数所做的只不过是以一种非常直接的方式实现 BPF 代码解释器(或者如果您喜欢,可以称为虚拟 CPU);一个长的 switch/case 语句区分操作码,并相应地对模拟寄存器和内存执行操作。模拟内存空间(过滤器代码在其中运行)当然是数据包的有效负载 (sk->data)。当遇到 BPF RET 指令时,过滤器执行流程终止,导致退出函数。
请注意,sk_run_filter() 函数仅从 PF_PACKET 处理例程直接调用。套接字级接收例程(即,TCP、UDP 和原始 IP 例程)通过包装函数 sk_filter()(在 sock.h 中),除了在内部调用 sk_run_filter() 之外,它还将数据包修剪为过滤器返回的长度。
我们对内核数据包处理函数的巡视现在已完成。关于数据包过滤器调用点,得出一些结论是很有趣的。正如我们所见,内核内部有三个不同的调用点可以调用过滤器:TCP 和 UDP(第 4 层)接收函数,以及 PF_PACKET(第 2.5 层)接收函数。原始 IP 数据包也被过滤,因为它们通过与 UDP 数据包相同的路径(即,sock_queue_rcv_skb())传递,该路径用于面向数据报的接收)。
重要的是要注意,在每一层,过滤器都应用于该层的有效负载。也就是说,随着数据包向上移动,过滤器可以看到的信息越来越少。对于 PF_PACKET 套接字,过滤器应用于第 2 层信息,其中包括 SOCK_RAW 套接字的整个链路层数据帧或整个 IP 数据包;对于 TCP/UDP 套接字,过滤器应用于第 4 层信息(基本上是端口号和其他很少的有用数据)。因此,第 4 层套接字过滤很可能毫无用处。当然,在任何情况下,应用程序级有效负载(用户数据)始终可用于过滤器,即使它通常很少或根本没有用处。
清单 1 [可在 ftp.linuxjournal.com/pub/lj/listings/issue95/5617.tgz 找到] 和清单 2 给出了第 4 层无用性的一个鲜明例子,清单 2 展示了一个简单的 UDP 服务器,它带有一个附加的套接字过滤器和一个关联的简单 UDP 数据发送器。过滤器将仅接受有效负载以 “lj”(十六进制 0x6c6a)开头的数据包。要测试该程序,请编译并运行清单 1,称为 udprcv。然后编译清单 2 (udpsnd),并像这样启动它
./udpsnd 127.0.0.1 "hello world"
udprcv 不会打印任何内容。现在,尝试写入以 “lj” 开头的字符串,如
./udpsnd 127.0.0.1 "lj rules"这次,字符串被 udprcv 正确打印,因为数据包有效负载与过滤器匹配。
过滤器编写者应该注意的另一个重要问题是,过滤器必须根据要附加过滤器的套接字类型(PF_PACKET、原始 IP 或 TCP/UDP)来编写。实际上,过滤器内存访问使用相对于特定级别看到的数据包有效负载中第一个字节的偏移量。表 1 中报告了与最常见族对应的过滤器内存基地址。
此外,如果使用非 PF_PACKET 套接字,则 2001 年 6 月的文章中描述的获取过滤器代码的方法(即,使用 tcpdump -dd)不再适用,因为它生成的过滤器仅适用于第 2 层(因为它假设地址 0 是链路层帧的开始)。
跟踪数据包在内核中的旅程可能是一次有趣的体验。在我们的旅程中,我们遇到了典型的内核数据结构(例如 skbuff),发现了惯用的编程技术(例如使用带有函数指针的结构作为 C++ 对象的有效替代方案),并遇到了一些新的 2.4 机制 (softirqs)。
如果您渴望了解更多关于该主题的信息,请用内核源代码和一个舒适的编辑器武装自己,喝一杯好咖啡,然后开始在这里和那里窥视。价格便宜,乐趣有保证!

