
Linux 内核中的组播路由代码
在本文中,我将解释 Linux 内核如何管理组播流量,以及如何通过简单地修补一些内核代码来与之交互。虽然这是一个相当具体的主题,但对于任何对组播路由感兴趣的人来说,它可能很有用。如果您想监控或修改任何现有的组播协议,以下提供的信息将非常有用。
在米兰大学,我们正在开发一种新的协议 CAMP(呼叫准入组播协议),该协议使用组播内核代码提供的信息来做出一些重要的决策。我们必须能够接收重要事件的通知,例如 JOIN 或 LEAVE 请求。您可能知道,Linux 内核可以充当组播路由器,支持 PIM(协议无关组播,netweb.usc.edu/pim)的第 1 版和第 2 版。所有 MFC(组播转发缓存)更新操作都完全由与内核交互的外部用户模式进程提供服务。在本文中,我们将解释内核如何管理用户模式守护程序发送的消息,以便更新 MFC。在简要介绍之后,我们将更详细地描述我们的钩子实现。图 1 显示了我们测试网络的拓扑结构。正如您所看到的,SNOOPY 充当组播路由器,在 Linux 内核 2.4.18 之上运行 PIMd(版本 2.1.0-alpha 29.9)。
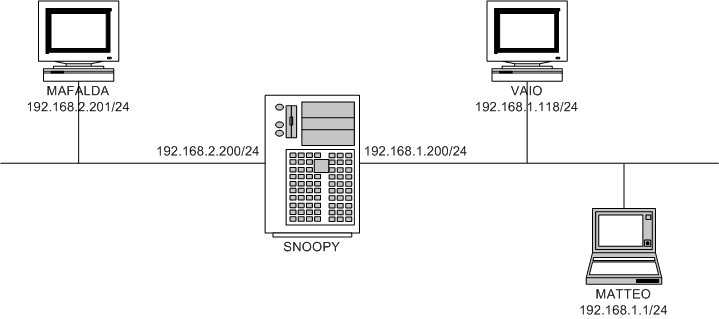
图 1. 测试网络拓扑
内核中所有与组播相关的代码都位于两个文件中:ipmr.c (net/ipv4/ipmr.c) 和 mroute.h (include/linux/mroute.h)。在我们开始查看代码之前,重要的是要提到另外两个文件:/proc/net/ip_mr_vif 和 /proc/net/ip_mr_cache。正如我们稍后将看到的,这两个文件对于理解组播路由器的当前状态特别有用。ip_mr_vif 文件列出了所有参与组播操作的虚拟接口,而 ip_mr_cache 则准确地表示了 MFC 的状态。
现在,举例来说,我们开始从 VAIO 向地址 224.225.0.1 发送组播流量。数据包被 SNOOPY 接收,但没有转发到 eth1,因为 MAFALDA 没有发出 JOIN 请求。当 MAFALDA 确实向 224.225.0.1 发出 JOIN 请求时,两个 proc 文件(在 SNOOPY 上)的内容如表 1 和表 2 所示。
表 2. /proc/net/ip_mr_cache 的内容
在 ip_mr_vif 中,列出了参与我们组播路由的两个接口(eth0 和 eth1),而第三个接口(pimreg)是由组播管理代码注册的虚拟设备。在表 2 中,您可以看到 PIMd 构建的路由。在这里,来自 eth0 (Iif: 0)、源地址等于 192.168.1.118 (Origin: 7601A8C0) 且 направленный 到 224.225.0.1 (Group: 0100E1E0) 的数据包被转发到 eth1 (Oifs: 1:--暂时忽略第二个数字)。现在,我们从 MAFALDA 发出 LEAVE 消息。几秒钟后,/proc/net/ip_mr_cache 的内容被更新,结果如表 3 所示。
表 3. LEAVE 消息后 /proc/net/ip_mr_cache 的内容
我们仍然有相同的源和组,但现在输入接口已更改为 -1,并且我们没有输出接口。这是因为数据包仍然从 eth0 进入,但由于没有人希望在其他接口上接收它们,所以它们被丢弃。当数据包以这种方式被丢弃时,一个新的条目被存储在一个特殊的未解析地址队列中。为了表明这是一个未解析的地址,输入接口被设置为 -1,并且没有列出输出接口。
排队未解析数据包的操作对于一个特殊的原因是必要的:接收 IGMP 数据包并添加相应的 MFC 条目需要很长时间(在我们的测试网络上大约 2-3 秒,在具有互连组播路由器的更大网络上大约 20-30 秒)。当 VAIO 在我们之前的示例中开始传输组播数据包时,MAFALDA 的 JOIN 消息很可能尚未被 SNOOPY 处理,并且转发数据包所需的相应 MFC 条目尚未设置。因此,为了不丢失在处理 JOIN 请求和添加新 MFC 条目时从 VAIO 接收的数据包,它们被排队到这个特殊缓存中。一旦添加了 MFC 条目,队列就会被清除,并且等待在其中的数据包将被转发到正确的目的地。显然,由于性能和内存限制,这个队列不能增长得太大。这可以通过简单地添加一个定时器函数来解决,该函数定期清除未解析条目的缓存 (ipmr_expire_process())。
现在,让我们看一下此过程中涉及的数据结构(清单 1)。
清单 1. 组播路由代码使用的 vif_device 和 mfc_cache 结构。
vif_device 是链接到真实网络适配器的虚拟设备。dev 字段是指向表示真实硬件接口的 net_device 结构的指针。更有趣的是 mfc_cache 结构。它的字段是不言自明的,并反映了表 2 和表 3 中显示的所有数据。
ipmr.c 中使用的三个主要变量如下
/* Devices */ static struct vif_device vif_table[MAXVIFS]; /* Forwarding cache */ static struct mfc_cache *mfc_cache_array[MFC_LINES]; /* Queue of unresolved entries */ static struct mfc_cache *mfc_unres_queue;
vif_table 只是 PIMd 创建的所有虚拟设备的数组;mfc_cache_array 表示 MFC;而 mfc_unres_queue 是上述未解析条目的列表。在分析组播管理代码之前,值得花几句话介绍一下 TTL 数组,它是 mfc_cache 结构的成员。数组的每个值都直接链接到 vif_table。实际上,对于分配给每个接口的每个组播地址,我们都有一个单字节值来标识 TTL 阈值。正如我们稍后将看到的,在决定是否转发数据包时,会将此值与每个 IP 数据包的 TTL 字段进行比较。
我们已经看到了组播路由的基本数据结构,现在让我们看一下内核如何操作它们。所有函数都在一个单独的文件 ipmr.c 中实现。请记住,此文件中的代码并未实现路由协议本身。您可以在 ipmr.c 中找到的函数由组播路由守护程序(在本例中为 PIMd)使用,以管理这些数据结构。简而言之,每当 PIMd 决定是时候添加或删除路由时,它只会向内核发送一条消息,指定应采取的操作。PIMd 为了做到这一点,必须能够接收 IGMP 数据包;这些数据包由内核传递到用户空间。PIMd 通过两种不同的方式与内核通信:使用 ioctl 和通过 setsockopt() 系统调用。vif 和 mfc 表都使用 setsockopt() 系统调用处理。
为了更好地理解这是如何实现的,我们还看一下 PIMd 的一些代码。特别是,所有与内核通信的函数都位于 PIMd 发行版的 kern.c 文件中。在这里,函数 k_chg_mfc() 负责添加或修改现有的 MFC 条目,而删除现有条目则由 k_del_mfc() 执行。为了告诉内核应如何转发组播数据包,用户守护程序必须提供一些类似于 mfc_cache 结构中列出的信息。特别是,此信息被封装在一个新定义的结构 mfcctl 中(清单 2)。
本例中的字段应该是自解释的。但重要的是要提到 mfc_ttls 数组在此结构中的作用。如前所述,此值表示 TTL 阈值;但是,用户模式守护程序以稍微不同的方式处理它。函数 k_chg_mfc() 必须向内核指定应在哪些接口上转发组播数据包。为了做到这一点,必须提供输出接口列表;mfcc_ttls 承担了此角色。下面的代码片段显示了这一点
for (vifi = 0, v = uvifs;
vifi < numvifs; vifi++, v++)
{
if (VIFM_ISSET(vifi, oifs))
mc.mfcc_ttls[vifi] = v->uv_threshold;
else
smc.mfcc_ttls[vifi] = 0;
}
在这里,如果一个接口确实是特定组播地址的输出接口,则其 TTL 阈值设置为实际值;否则设置为零。内核将值零解释为该特定组的非输出接口,因此,它会将 mfc_cache 结构的相应字节设置为等于 255(十进制)并且不转发数据包。
现在,让我们看看当内核收到添加新条目到 MFC 的请求时会做什么。类型请求由 ipmr_mfc_add() 函数处理。内核通过在 MFC 中查找当前条目来检查这是否是更新请求。如果找到匹配项,则新的 TTL 值将复制到现有的 mfc_cache 结构中,并且 minvif 和 maxvif 值也会更新。这些值指示特定组播地址的所有输出接口的最小和最大索引值。执行此工作的函数是 ipmr_update_thresholds()。为了您的方便,我们包含了清单 3 中显示的函数,因为它更好地解释了 minval 和 maxval 字段的含义。
回到我们的 ipmr_mfc_add() 函数;现在我们考虑找不到现有 MFC 条目的情况。在这种情况下,将分配一个新的结构并将其插入到 MFC 表中。完成此操作后,内核必须执行最后一个操作:转发当前在 mfc_unres_queue 中排队的任何可能 направленный 到新添加的目标节点的未解析组播数据包。如果是肯定的情况,则数据包将从该队列中删除并转发到新接口。仍然需要执行的另一个操作是 MFC 删除。这一个非常简单——数据结构基本上与之前看到的相同。为了删除缓存条目,用户模式守护程序调用 k_del_mfc() 函数,而内核模式的处理程序调用 impr_mfc_delete()。此函数只是从 MFC 中删除指定的条目。
现在我们已经确定了 MFC 条目在哪里添加、修改和删除,我们可以开始挂钩组播路由代码了。函数挂钩是一个简单的概念。基本上,插入到先前显示的代码中间的函数会导致系统切换到在内核模块中实现的外部函数。在某种程度上,在模块中实现的函数可以被视为回调,每次添加、修改或删除 MFC 条目时都会调用它。为了实现这种挂钩机制,我们的代码基于 2.4.x 内核中已实现的众所周知的挂钩架构:Netfilter 接口。如果您以前从未使用过它,只需说它是在内核中实现的流行接口,用于允许数据包过滤。Netfilter 对数据包执行的相同操作可以很容易地使用任意数据结构完成——在本例中为 mfc_caches。特别是,以下是回调函数的原型
typedef void nf_nfy_msg(
unsigned int hook,
unsigned int msgno,
const struct net_device
*dev,
void* moreData);
这里,hook 表示域(此值始终假定 PF_INET 值);msgno 表示消息号(内核采取的操作,例如添加 mfc_cache 条目);dev 可以假定为操作期间涉及的任何当前 net_device 的值;而 moreData 是指向通用数据结构的 void* 指针。此指针实际上是指向 mfc_cache 数据结构的指针。
现在我们已经看到了回调的格式,让我们看看内核如何调用它。实际上非常简单;将以下内容放在内核代码中将为指定的操作调用任何已注册的钩子函数
#ifdef NF_EVT_HOOK && NF_MCAST_HOOK
NF_NFY_HOOK(
PF_INET,
NF_NFY_IP_MCAST_MSG,
IPMR_MFC_ADD,
NULL,
(void*) c);
#endif
但是,关于我们的钩子架构的详细信息超出了本文的范围。读者可以通过查看我们修改后的内核文件 [可从 Linux Journal FTP 站点获取,网址为 ftp.linuxjournal.com/pub/lj/listings/issue103/6070.tgz] 或原始 Netfilter 实现来更好地理解代码。
现在我们已经对 Linux 中的组播路由实现进行了完整的概述,并对如何实现挂钩机制进行了一些说明,有必要指出我们在测试期间观察到的一些概念。
让我们回到我们的测试网络,并想象以下场景:SNOOPY 正在发送组播流量,MAFALDA 和 VAIO 都发出 JOIN 请求。您希望看到一个新的组播路由,其中 eth0 和 eth1 作为输出接口。不幸的是,情况并非如此。查看 /proc/net/ip_mr_cache,您只能看到到 MAFALDA 的单条路由,但 MAFALDA 和 VAIO 都在正确接收组播流量。原因如下:来自 SNOOPY 的传出数据包使用 192.168.1.200 作为源地址。因此,当在 eth0 上发送数据时,SNOOPY 的行为就像在 LAN 上发送组播流量一样。这意味着 SNOOPY 甚至会在 VAIO 发出 JOIN 之前就开始在 eth0 上发送数据包,因为内核不知道是否存在能够解释来自其他 PC 的 IGMP 数据包的 PIM 守护程序。为了使其他工作站接收组播流量,它只是发送数据包。这样,同一网段上的任何其他机器都可以打开组播硬件过滤器并从线路中拾取所需的数据。在类似的情况下,组播 JOIN 和 LEAVE 请求无法在主接口上挂钩,因为在该接口上,内核并非完全执行组播路由。


