
国际化编程简介
使用同一个程序,但根据不同民族的文化传统改变其属性的想法被称为国际化。然而,由于程序员喜欢缩短单词,他们只输入四个字符 i18n,而不是输入 20 个字符。I18n 意味着为处理多种语言而设计的编程。
一旦您编写了一个 i18n 程序,您可能想要添加一种新语言。这不是一个 i18n 问题。一般来说,您需要一个人来为特定国家/地区翻译程序中的消息。这个问题被称为本地化,或 i10n。I10n 指的是为国际化软件实现特定语言,或者换句话说,根据特定地区的规则创建 本地化对象。
尽管每个设计和分发软件的组织和公司都试图以自己的方式实现这一点,但总的来说,i18n 的想法很简单。软件的创建应考虑两个部分:通用部分和国家/地区依赖部分。第二部分被称为 本地化对象。
希望标准能让生活更舒适。 locale 的基本概念是由 ISO(国际标准组织)在 1990 年的 C 标准中引入的,并在 1995 年进行了扩展。POSIX 也有 i18n 规则,因此术语 POSIX locale 与国家语言支持 (NLS) 一起使用。从形式上讲,NLS 不是 POSIX 的一部分,但它有一些在使用 POSIX locale 时有帮助的功能。X11 有其自己的 i18n 实现,但程序员常用的方法是将 X11 i18n/i10n “提升一个级别” 到 POSIX/NLS locale。[其他软件有其自己的 i18n 和 i10n。有关处理方法之一,请参阅“弥合南非的数字鸿沟”。]
在谈论 locale 时,我们应该考虑什么?当然,语言的名称,但这还不够。每个人都知道美式英语和英式英语之间存在差异,因此我们还必须知道特定语言使用的地点,或者换句话说,考虑到个人传统和文化规则的地区。
每种语言都有自己的书写系统,有时甚至有几种。语言有字母表或字符库,但计算机处理的是数字。因此,一个字符应与一个数字关联。这种关联称为编码字符集 (CCS)。有很多这样的字符集,每个都有自己的名称,例如 ASCII、ISO-8859-1、KOI8-U。通常使用术语字符集代替 CCS。字符集的名称没有特殊的标准,因此 ISO-8859-1、ISO8859-1 和 iso8859-1 都指的是同一件事。IANA(也负责字符集注册的组织)有一些定义(请参阅资源)。您可能知道,X11 系统有其自己的字符集命名系统,他们的文档“逻辑字体描述转换”(在 Jim Flower 的文章中描述,请参阅资源)提供了一个很好的名称和别名字符集创建系统。
字符集非常重要。一些国家/地区对同一种语言有几种不同的字符集!例如,在乌克兰,相同的文本在 koi8-u 中可能显示良好,但如果终端使用乌克兰字符集 iso8859-5、cp1251 或 Unicode,则可能完全无法读取。在这些情况下,我们将不得不将文本从一个字符集转换为另一个字符集。
为了考虑到所有这些,POSIX locale 定义了一些统称为 locale 类别 的内容。它们在表 1 中显示。了解它们很重要;C 函数在不同的 locale 下工作方式不同!类别在 shell 中反映为同名的环境变量。清单 1 显示了使用 LC_ALL 的示例。
构建 locale 名称的语法如下所示
language[_territory][.codeset][@modifier]
其中 language 由两个小写字母表示,例如 en 表示英语,fr 表示法语;territory 由两个大写字母表示,例如 GB 表示英国,FR 表示法国,在这两种情况下,euro 将是 modifier。因此,您可以通过设置相应的环境变量来更改您的 locale。请参阅清单 1,我们在其中使用了程序 date、cat 和我们的示例程序 counter。请注意,我们仅使用语言和地区;我们无法使用此命令更改终端的字符集。现在想象一下,程序消息是用一种字符集编写的,但输出却使用另一种字符集。POSIX 没有确定当前字符集的函数,但 XPG 有 nl_langinfo()。在某些发行版中,此函数的 man 页面可能丢失(Debian 没有,但 SuSE 和 Red Hat 有)。在任何情况下,您都可以从 /usr/include/langinfo.h 获取更多信息。要确定当前字符集,请使用以下代码
#include <locale.h>
#include <langinfo.h>
...
setlocale(LC_ALL,"");
printf ("Current charset = %s\n",
nl_langinfo(CODESET));
要将一种编码转换为另一种编码以获得正确的输出,您可以使用 conv() 函数。有关更多详细信息,请查阅“i18n 简介”(请参阅资源)。为了提供输出信息,为该 locale 创建了一个消息目录。这意味着所有软件消息都与可能(并且必须)有自己的目录的程序分开保存。NLS 提供了一组用于创建和支持此类目录的实用程序,以及用于根据三个键提取信息的函数:1) 程序名称,2) 当前 locale 类别和 3) 指向要输出的特定消息的指针。
NLS机制通常有两种实现方式
X/Open 可移植性指南 XPG3/XPG4/XPG5,具有函数 catopen()、catgets() 和 catclose() 以及 gencat 实用程序。
SUN XView 具有函数 gettext() 和 textdomain()。GNU 项目有其自己完全兼容的版本,称为 GNU gettext。
通常,程序以及系统库都使用一个(甚至两个)NLS 系统。
尽管 XPG5 包含在 UNIX 规范版本 2 中,并且所有版本的 UNIX 系统都支持它,但在 Linux 中,GNU gettext 是最流行的解决方案。
POSIX locale 包含以下组件
Locale API,即 setlocale()、isalpha() 等子例程。
用于管理 locale 类别的 Shell 环境变量。
locale 实用程序,用于获取有关当前 locale 的信息;有关更多详细信息,请参阅 man locale。
本地化对象。它们的默认位置目录是 /usr/share/locale/。
如果您要编写一个真正的 i18n 程序,明智的做法是认为您对特定语言一无所知,并考虑字符集。表意语言的字母远不止 26 个:日语约有 2,000 个,中文约有 5,000 个。为了处理此类字符,POSIX locale 具有多字节和宽类 (wchar_t)。后者是为 Unicode 完成的。要将一个转换为另一个,可以使用 mblen()、mbstowcs()、wctomb()、mbtowc() 和 wcstombs() 等函数。但是,使用 Unicode 超出了本文的范围。
生成真正的多语言软件是一项复杂的任务。希望现在符合 SUN XView 的 GNU gettext 系统将帮助您编写 i18n 程序。
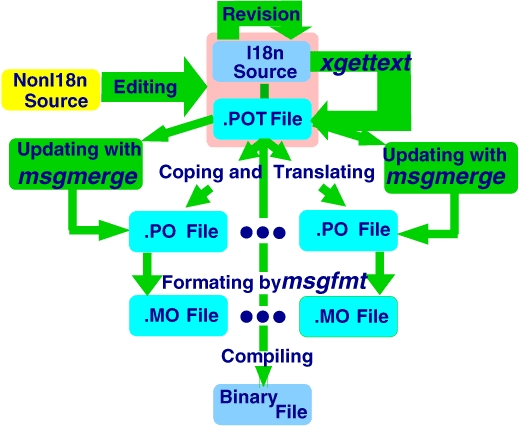
图 1. 生成 i18n 程序
图 1 代表了生成 i18n 程序的所有必要步骤
要创建 i18n 版本,您必须编辑一个非 i18n 程序。如果您使用特殊的编辑器模式,您将同时创建一个额外的文件,称为 POT 文件,其中 PO 代表可移植对象,字母 T 代表模板。
如果您只是对现有的 i18n 程序进行修订,或者如果 POT 文件不存在,则必须使用 xgettext 程序来生成它。
将模板文件复制到 ll.po 中,其中 ll 指的是某种语言。
将消息翻译成语言 ll。
使用 msgfmt 程序创建一个 ll.mo 文件(mo 代表机器对象)。有时您可以看到 gmo 文件(g 代表 GNU)。
编译您的源代码;将二进制程序和 ll.mo 文件放到正确的位置。此步骤和之前的步骤最好使用 Makefile 完成。
在简要了解一个简单程序的所有步骤之前,请阅读以下国际化黄金法则
1) 将以下行放入程序的非可执行部分,并在源文件中将消息标记为 _("message") 而不是程序可执行部分中的 "message" 和非可执行部分中的 N_("message")。请注意输出,以确保通过 gettext 传递声明为常量的字符串,即在非可执行部分中
#include <libintl.h> #include <locale.h> #define _(str) gettext (str) #define gettext_noop(str) (str) #define N_(str) gettext_noop (str)
2) 通过设置 locale 启动您的程序
setlocale (LC_ALL, "");3) 指示消息目录名称,并在必要时指示其位置
bindtextdomain(PACKAGE,LOCALEDIR); textdomain (PACKAGE);PACKAGE 和 LOCALEDIR 通常由 config.h 或 Makefile 文件提供。
4) 要检查符号的属性和转换,请使用诸如 isalpha()、isupper()、...、tolower() 和 toupper() 之类的调用。
5) 要比较字符串,请使用 strcoll() 和 strxfrm() 函数而不是 strcmp()。
6) 为了保证与旧版本 locale 的可移植性,请对符号使用 unsigned char 类型的变量,或者使用 -funsigned-char 键编译您的程序。
让我们创建一个简单的国际化程序,其中忽略了这些规则(清单 2)。该程序输出一个输入提示,从终端读取一个字符串并计算其中的数字。计数结果输出到终端,然后程序退出。
由于程序很小,我们可以使用您喜欢的编辑器根据规则轻松更改它;如果程序很大,最好使用特殊工具。像 (X)Emacs 或 vi 这样的编辑器与 po 模式可以同时在您更改程序源代码时创建一个 counter.pot 文件!
更改后的文件如清单 3 所示。第 4-8 行是根据规则 1 添加的。locale.h 文件中的定义可能不是必需的;它们可能包含在 libintl.h 定义中。多次编写 gettext 和 gettext_noop 很烦人,因此我们将使用宏,如第 6-8 行中定义的那样。使用 gettext_noop 是编译阶段预初始化字符串的示例。我们的程序中显示了一种可能的解决方案,其中使用 gettext_noop 允许在执行时被 gettext 识别字符串。
如果没有第 15 行(规则 2),程序将无法理解您的 locale 并将使用 C locale。请注意,有时需要设置特殊的 locale 类别,例如 LC_CTYPE 和 LC_MESSAGES。有关更多信息,请参阅 man setlocale 和本文中的表 1。
第 16 行和第 17 行是根据规则 3 插入的。通常,这些调用的参数在 Makefile 或保存配置信息的特殊文件(如 config.h)中提供,但在本程序中,我们直接输入名称。根据第 16 行,搜索将在当前目录中开始。如果省略带有调用的行,Linux 将使用默认位置 /usr/share/locale。
调用 textdomain() 必须 出现在任何 i18n 程序中。它将 gettext 系统指向带有 i10n 消息的文件名。
第 19 行、第 25 行和第 26 行根据规则 1 进行了更改。第 19 行和第 25 行很简单:我们没有直接使用字符串,而是通过 gettext 调用它们来使用消息目录。第 26 行演示了例外情况。我们无法通过 gettext 转换在非可执行部分中定义的字符串,因为那里的值是在编译器运行程序之前初始化的。问题根据规则 1 解决。我们在第 12 行中用 N_ 标记字符串,以使它们可被 xgettext 识别;我们在第 26 行中使用了 _(mess) 而不是 mess,就像普通字符串一样。由于 isdigit 函数(参见规则 4),我们不需要做更多的事情。
现在程序已经国际化了。然而,编译和运行它产生的结果与之前的非 i18n 程序完全相同。来自 counter.pot 文件的消息必须翻译成特定语言。
还有另一种创建初始 .pot 文件的方法。一旦您拥有一个 i18n 程序,就可以使用 xgettext。它扫描源文件并创建相应的字符串以进行翻译。在我们的例子中,我们可以这样调用它
xgettext -o counter.pot -k_ -kN_ counter.c
其中 -o 用于输出文件名,-k_ -kN_ 用于提取以相应符号开头的字符串。查阅 info xgettext 以获取更多详细信息。
通常,程序员处理源代码,而翻译人员处理相应的 .po 文件,该文件可以使用 copy 命令从 .pot 文件创建,也可以直接从带有 xgettext 程序的源代码创建。
浏览一下 .po 文件,您会看到它有一个标头和用于翻译的条目。这是一个条目的示例
# This is my own commentary #: counter.c:25 #, c-format msgid "You typed %d %s \n" msgstr "Vous avez tapé %d %s\n"
这很简单。您翻译来自 msgid 的短语,并将结果放入 msgstr 字段中。如果一行以 #:, 开头,则它是对源的引用;如果它以 #, 开头,则它显示条目的属性。您可以在以两个符号开头的行中添加您自己的注释:#(磅符号,然后是一个空格)。
在复制模板 .pot 文件信息 (.po) 或使用 xgettext 命令创建新文件后,您可以开始翻译。通常,这项工作可以由另一个人使用他或她喜欢的编辑器来完成。(X)Emacs 对于这项工作来说还不错,但 KBabel(KDE 的一部分)甚至更好。如果您要参与翻译团队,强烈建议您使用 KBabel。描述 KBabel 超出了本文的范围,但您可以在“KBabel 手册”(请参阅资源)中阅读有关它的更多信息。
翻译是一种艺术。编写正确的短语可能很困难,有时您可能会怀疑自己使用特定语言的能力。因此,您可能希望保留一些未翻译的条目,或者对翻译有疑问的条目,将它们标记为“模糊”。使用 KBabel 或 (X)Emacs,您可以轻松找到此类条目并在以后再次编辑它们。不用担心;只有完全翻译的条目稍后会被 msgfmt 编译并在程序中可用。这仅仅意味着一个条目可以标记为“已翻译”、“未翻译”或“模糊”,并且随着软件的快速变化,还有一个“过时”属性。
语言是灵活的。英语消息也并非总是完美。在我们的例子中,消息“You typed 0 digit”是不正确的。GNU gettext 可以管理翻译问题,例如词序、复数形式和歧义,但您必须使用比 gettext() 具有更多参数的额外函数。
一旦您翻译了文件,您应该将其转换为 .mo 文件,如果您使用相应的 locale 运行程序,gettext 将使用该文件。不要忘记将此文件放在正确的位置,在我们的例子中
mv counter.mo fr/LCMESSAGES/
现在 counter 可以说法语了!(请参阅清单 1。)
程序会不断发展,如果它们的源代码被更改,相应的 .po 文件也必须更新。在这种情况下,仅使用 xgettext 并非理想的解决方案。所有已翻译的消息都将丢失,因为它会覆盖 .po 文件。在这种情况下,您应该使用程序 msgmerge。该程序合并两个 .po 文件,保留已进行的翻译(如果新字符串与旧字符串匹配),更新条目的属性并添加新字符串。当然,这些新字符串将是未翻译的条目。一个典型的调用很简单
msgmerge old.po new.po > up-to-date.po
本文未描述输入法,尽管它也很重要。通常,非 X11 软件不需要担心 i18n 输入法,因为这是控制台和 X 终端仿真器的责任。
对于 X11 中的输入,存在三种方法:Xsi、Ximp 和 XIM。前两种方法已经过时;最后一种方法是事实上的标准。它们的描述超出了本文的范围;但是,rxvt 程序的源代码提供了一个很好的例子。
现代工具提供了它们自己的特殊子例程,用于输入国际化字符串,并使用 gettext 输出消息。为了使程序代码对于内部提案是 8 位透明的,使用了 Unicode。例如,Qt 以这种方式工作,提供了用于正确输入和输出 i18n 字符串的附加函数(请参阅资源)。
您可能还想查看 mutt 的源代码,它是一个很好的 i18n 程序 (www.mutt.org)。此程序支持字符集的别名。
Tomohiro Kubota 描述了在程序中使用 Unicode 的方法(请参阅资源)。祝您 i18n 愉快!

