
Reiser4 文件系统中的树,第一部分
组织信息的一种方法是将其放入树结构中。当我们在计算机中组织信息时,我们通常将其分类到称为节点的堆中,每个堆都有一个名称(指针)。一些节点包含指针,我们可以查看这些节点以找到指向(通常是其他)节点的指针。
我们特别感兴趣的是如何组织,以便在搜索时实际找到东西。树是一种组织结构,它具有一些对此目的有用的属性。我们将树定义如下
树是组织成一个根节点和零个或多个附加节点集(称为子树)的节点集合。
每个子树都是一棵树。
树中没有节点指向根节点,并且树中恰好有一个来自节点的指针指向树中的每个非根节点。
根节点有一个指向其每个子树的指针,即指向子树的根节点的指针。
请注意,没有指针的单个节点是一棵树,因为它就是根节点。此外,树可以是无分支的节点线性树。

图 1. 写入性能(30 份 Linux Kernel 2.4.18 副本)

图 2. 读取性能(读取 Linux Kernel 2.4.18 源代码)
争论“有限”是否应该是树定义的一部分很有趣。定义树有很多种方法,哪种定义最好取决于您的目的。唐纳德·克努特教授提供了几个树的定义。作为他对树的主要定义,他甚至提供了一个在定义中没有指针、边或线,只有节点集合的定义。
克努特将树定义为有限的节点集合。互联网上有关于无限树的论文。我认为将“有限”视为树的附加限定词,而不是将其捆绑到定义中更合适。但是,我个人在我的研究中只处理有限树。
“边”是树定义中常用的术语。指针是单向的,意味着您可以从拥有它的节点跟随它到它指向的节点,但您不能从它指向的节点跟随它回到拥有它的节点。然而,边是双向的,意味着您可以沿两个方向跟随它。
以下是三个替代的树定义,它们在数学上彼此等价,这很有趣。它们与我提供的定义不等价,因为边与指针不等价。对于这三个定义,连接同一两个节点的边不超过一条
一组由边(又名线)连接的顶点(又名点),其中边的数量比顶点的数量少一;
一组由没有环的边连接的顶点(环是从一个顶点到自身的路径);
或一组由边连接的顶点,其中恰好有一条路径连接任意两个顶点。
这三个替代定义在其树中没有唯一的根,并且这样的树被称为自由树。
我提供的定义是根树的定义,而不是自由树。它也没有环,它的指针比节点少一个,并且从根到任何节点都只有一条路径。
考虑您可能想要使用图的目的以及您可能想要使用树的目的。在树中,从根到树中每个节点都只有一条路径,并且树具有连接所有节点所需的最小数量的指针。这使其成为一个简单而高效的结构。当需要以最小的复杂性实现效率并且不需要通过多条路径到达节点时,树非常有用。
Reiser4 既有图也有树,当文件系统选择组织方式时(在我们称之为存储层中,它试图简单高效),使用树,而当用户选择组织方式时(在语义层中,它试图具有表现力,以便用户可以做任何他或她想做的事情),使用图。
我们为存储在树中的所有内容分配一个键。我们通过它们的键找到事物,并且使用它们为我们提供了在排序事物方面的额外灵活性。如果键很小,我们就有了一种紧凑的方式来指定足够的信息来找到事物。它也限制了我们可以用于查找事物的信息。
这种限制限制了键的有用性,因此我们有一个存储层,它通过键查找事物,以及一个语义层,它具有丰富的命名系统(在本文的第二部分中描述)。存储层选择事物的键仅仅是为了以提高性能的方式组织存储,而语义层理解对用户有意义的名称。在您阅读时,您可能想思考一下,这种分离是否是一个有用的方法,它允许自由地添加有助于存储层性能的改进,同时避免为这些改进对语义层灵活命名目标产生的副作用付出代价。
我们从根开始搜索,因为从根我们可以到达每个其他节点。但是,我们如何选择从根到哪个根的子树?根包含指向其子树的指针。对于指向子树的每个指针,都有一个相应的左分隔键。指向子树的指针以及子树本身,按其左分隔键排序。子树指针的左分隔键等于子树中事物的最小键。其右分隔键大于子树中最大的键,并且它是此节点的下一个子树的左分隔键。
每个子树仅包含键至少等于其指针的左分隔键且不大于其右分隔键的事物。如果树中没有重复的键,则每个子树仅包含键小于其右分隔键的事物。如果没有重复的键,那么通过查看节点内指向子树的指针及其分隔键,我们就知道该节点的哪个子树包含我们想要的事物。
重复键是另一个时间的话题。现在我只会暗示,当搜索具有重复键的对象时,我们会在树中找到第一个对象。然后我们逐个搜索所有重复项,直到找到我们正在寻找的内容。允许重复键可以允许更小的键,因此有时会在键大小和这种低效线性搜索的平均频率之间进行权衡。
树中每个节点的内容都在节点内排序。因此,整个树按键排序,对于给定的键,我们确切地知道去哪里找到至少一个具有该键的事物。
我们选择使节点大小相等,这样更容易分配节点之间的未使用空间,因为它的大小将等于节点大小的某个倍数。这样,就不会出现空间空闲但不足以存储节点的问题。此外,磁盘驱动器有一个接口,它假定大小相等的块,他们发现这对于他们的纠错算法很方便。
如果节点大小相等不是很重要,可能是因为树适合放入 RAM,那么使用一类称为跳跃列表的算法值得考虑。
Reiser4 节点通常等于页面大小,如果您在 Intel CPU 上使用 Linux,则为 4,096 (4k) 字节。没有测量的经验理由认为此大小优于其他大小;它只是 Linux 使编程最容易和最简洁的大小。老实说,我们一直太忙而没有尝试其他尺寸。
如果节点大小相等,我们如何存储大型对象?我们将它们切成碎片,我们称这些碎片为项。项的大小适合放入单个节点中。
传统文件系统将文件存储在整个块中。粗略地说,这意味着,平均而言,每个文件浪费半个块的空间,因为并非文件的最后一个块的所有空间都被使用。如果文件远小于一个块,则浪费的空间占文件总大小的很大百分比。在传统文件系统中,将地址和电话号码等典型的数据库对象存储在单独命名的文件中是无效的,因为存储块中超过 90% 的空间被浪费了。通过在 Reiser4 中的单个节点内放置多个项,我们能够将多个小文件碎片打包到一个块中。我们小文件的空间效率约为 94%。这不包括每个项的格式化开销,其占总消耗空间的百分比取决于平均项大小,因此很难量化。
但是,将文件对齐到 4k 边界对于大型文件确实有优势。当程序想要直接对文件数据进行操作而无需通过系统调用来执行此操作时,它可以使用 mmap() 使文件数据成为进程直接可访问地址空间的一部分。由于某些实现细节,mmap() 需要文件数据是 4k 对齐的。如果数据已经是 4k 对齐的,则 mmap() 会高效得多。在 Reiser4 中,当前的默认设置是大于 16k 的文件是 4k 对齐的。我们还没有足够的经验数据和经验来了解 16k 是否是此截止点的最佳默认值。
继续我们的树比喻,叶节点是没有子节点的节点。内部节点是有子节点的节点。
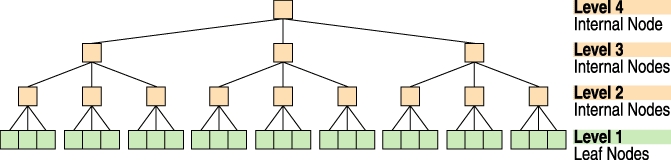
图 3. 高度 = 4,四层,扇出 = 3,平衡树
搜索从根节点开始,遍历另外两个内部节点,并以叶节点结束,叶节点是保存数据且没有子节点的节点。
项是一个数据容器,它完全包含在单个节点内。包含项的节点称为格式化节点。当我们在树中存储对象时,我们将它们的各个部分放入项和未格式化的叶节点中。未格式化的叶节点(unfleaves)是仅包含数据而不包含任何格式化信息的叶节点。只有叶节点可以包含未格式化的数据。指针存储在项中,因此所有内部节点必然是格式化节点。
指向 unfleaves 的指针在结构上与指向格式化节点的指针不同。为了澄清,范围指针指向 unfleaves。范围是属于同一对象的连续的、按块号顺序排列的 unfleaves 序列。范围指针包含范围的起始块号和长度。因为范围只属于一个对象,所以我们只能为范围存储一个键,并且我们可以计算该范围中任何字节的键。如果范围至少有两个块长,则范围指针比常规节点指针更紧凑。
节点指针是指向格式化节点的指针。我们还没有节点指针的压缩版本,但它们应该很快就会推出。请注意,对于范围指针,我们不必存储指向的每个节点的分隔键,而当使用节点指针时,我们需要这样做。我们可能会在添加压缩节点指针的同时引入键压缩。人们会期望键能够很好地压缩,因为它们按升序排序。我们期望我们的节点和项插件基础设施将使此类功能在以后易于添加。
枝节点是叶节点的父节点,范围指针仅存在于枝节点中。(这是一个非常有争议的设计决定,我将在本文的第二部分中讨论。)分支节点是不属于枝节点的内部节点。
您可能会认为我们会将根级别编号为 1,但由于树在顶部增长,因此将级别 1 设置为存储对象数据的叶节点级别会更有用。树的高度取决于我们需要存储多少对象以及内部节点和枝节点的扇出率(子节点的平均数量)是多少。
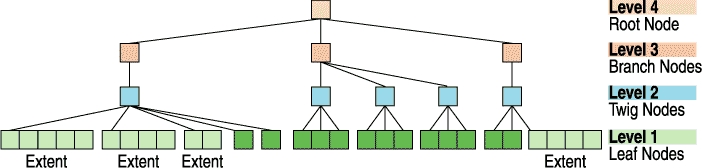
图 4. Reiser4 树,包括称为枝节点的内部节点
Reiser4 包括许多不同类型的项,旨在保存不同类型的信息
static_stat_data:保存所有者、权限、上次访问时间、创建时间、上次修改时间、大小以及文件的链接(名称)数量。
cmpnd_dir_item:保存目录条目和它们链接到的文件的键。
范围指针:如上所述。
节点指针:如上所述。
主体:保存不足以存储在 unfleaves 中的文件部分。
我们称之为单元,它必须作为一个整体放入项中,而不能跨多个项拆分。当遍历项的内容时,通常以单元为单位执行此操作很方便
对于主体项,单元是字节。
对于目录项,单元是目录条目。目录条目包含名称和命名文件的键(实际上,名称和键可能会被压缩)。
对于范围项,单元是范围。范围项仅包含来自同一文件的范围。
对于 static_stat_data,整个 stat 数据项是一个固定大小的不可分割的单元。
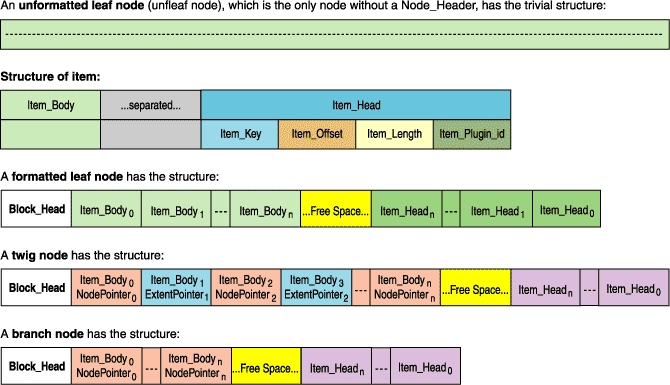
图 5. 节点格式的外观
我已经解释了 Reiser4 树的基本结构,但有趣的东西还在后头。我尚未解释其他研究人员如何构建他们的树。您也没有了解为什么对象内容存储在树的底部,为什么高扇出很重要,或者什么是不同的平衡类型。我还没有暗示为什么平衡树更好,而跳舞树是最好的。我最特别没有做的是解释一个微妙且有争议的树结构更改,您可以在本文描绘的树中看到,与 Reiser3 相比,Reiser4 的读取速度提高了一倍。这将(如果篇幅允许)在下一期《Linux Journal》的第二部分中介绍。
Hans Reiser (reiser@namesys.com) 在八年级毕业后于 1979 年进入加州大学伯克利分校,主修“系统化”,这是一个基于理论模型发展研究的个人专业。他的毕业论文讨论了硬科学的哲学与计算机科学的哲学有何不同,并将命名系统的发展作为一个案例研究。他仍在实施该命名系统,Reiser4 是该系统的存储层。1993 年,他去了俄罗斯,聘请了一个程序员团队来开发 ReiserFS。他全职工作以支付他们的工资,同时在晚上和周末争论算法。1999 年,它开始工作得足够好,以至于他的母亲不再建议他在一家不错的大公司找一份有薪工作。

