
学习 iTunesDB 文件格式
逆向工程是许多 Linux 软件项目所需的一项技能,因为许多文件格式没有公开规范。即使我们有规范,我们也可能需要逆向工程某些部分以了解所有细节。逆向工程是一项有益的经验。我们不仅可以详细了解一些东西,而且为 Linux 用户提供对以前不支持的设备的访问权限也令人满意。
本文讨论了逆向工程 Apple iPod 便携式 MP3 播放器使用的 iTunesDB 文件格式的具体示例。虽然此示例涵盖文件格式,但我们可以对设备驱动程序和网络流使用类似的技术。
逆向工程的关键策略是假设、模式识别和验证。我们使用假设来猜测文件中将包含什么。所有文件都包含重复的模式,而识别这些模式是逆向工程的关键。验证包括开发软件以检查文件是否符合格式。如果我们能判断文件是否有效,我们就理解了该格式。
我们需要对未知文件格式包含的信息类型做出假设。我们知道 iPod 播放数字音乐,并且歌曲可以组织成播放列表。因为我们在 iPod 硬盘上找不到任何其他文件来存储此信息,所以我们猜测它将在 iTunesDB 文件中。当我们查找文件中的模式时,尝试查找歌曲和播放列表信息的目标缩小了我们的搜索范围。
虽然每个文件格式都包含重复的模式,但诀窍在于识别这些模式并学习如何解析它们。在十六进制编辑器中打开文件使我们能够检查原始数据中的模式。图 1 包含 iTunesDB 文件的前 256 个字节,如 Emacs 在 hexl-mode 中所示。第一列是文件位置;然后有八列,每列包含两个字节。最后一列是数据非常有用的 ASCII 表示形式。

图 1. iTuneDB 文件的前 256 个字节
仅从前 256 个字节来看,就出现了一种模式:三个 5 字节序列以 “mh”(0x6d68)开头。当我们扫描文件的其余部分时,我们发现它散布着 5 字节的 mh 序列(参见图 2)。根据我们在文件中看到的 mh 字节序列的数量,我们假设这些序列是数据结构的标记。我们不知道数据结构是否具有固定或可变的大小。也许它只有五个字节长,并且 mh 序列之间的信息由其他数据结构组成。为了帮助我们确定此信息,我们将从文件中提取前 15 个 mh 序列(图 3)。

图 2. 5 字节 mh 序列

图 3. 前 15 个 mh 序列
数字 0x9c 和 0x18 使用 ASCII 无法转换为 “.”(. 的 ASCII 代码为 0x2e)。因此,我们遵循 Emacs 示例,对于超出标准 ASCII 字符范围的任何内容,我们都使用 .。
尽管我们只有几个数据点,但我们发现了多种潜在的模式。某些序列是重复的,例如 “mhod.” 和 “mhit.”。实际上,mhit. 序列之后都是 mhod. 序列。也许这些模式贯穿整个文件。在十六进制编辑器中筛选数百 KB 的数据之前,最好考虑使用第三个逆向工程策略:验证。
测试假设的一个好方法是编写验证程序,而且越早越好。验证程序的目标是解析文件,并使用从模式识别和假设中得出的各种测试来确定其是否有效。验证程序的首次迭代将很少有(如果有的话)正确的测试,但是随着我们开始理解格式,该程序将演变为合规性测试器。然后,它对于检查修改此格式文件的软件很有用,因为我们可以使用它来确保我们的更改是有效的。
我们的第一个验证程序将显示有关文件中所有 mh 块的信息(如图 4 所示),以帮助我们找到模式。我们看到的第一个明显的模式与 mh 块的文件位置之间的差异有关。除了 mhod 块之外,第五个字节包含直到下一个 mh 块的字节数。我们可以向我们的验证程序添加代码来检查此模式,我们发现情况几乎如此:除了 mhod 块之外,还有一些块未通过我们的测试。iTunesDB 文件格式的创建者不太可能将数据结构的大小限制为 256 字节,因此我们可能正在处理多字节数字。
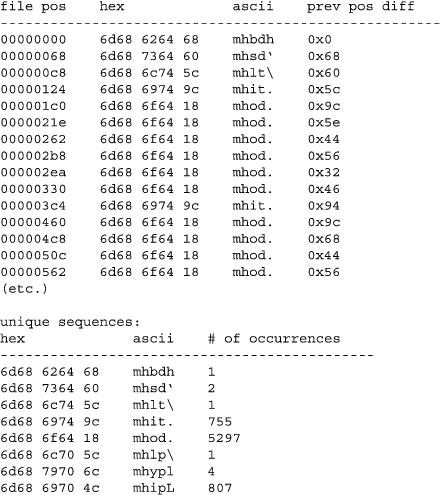
图 4. 验证程序的结果
一旦 “多字节” 这个词出现在我们脑海中,我们就必须考虑文件的字节序。如果第一个字节是多字节数字的一部分,则它是最低有效字节,因此是小端数字。如果文件中的一个数字是小端,则整个文件将是小端。只有虐待狂的设计师才会创建混合字节序文件格式。字节六、七和八几乎总是零,因此我们猜测块大小为 4 字节数字。
图 5 包含我们关于文件格式基本构建块的理论图。当我们更改我们的验证程序以对块大小使用 4 字节数字时,该测试对于所有非 mhod 块都成功。

图 5. 文件格式理论
逆向工程要求我们在我们的三个策略之间来回切换,以便解密文件格式。我们将继续采用这些策略来发现更多细节。我们编写了可以将文件格式解析为可变大小和类型的数据块的软件。我们想知道块中的每个字节都表示什么,这需要更多的假设、模式识别和验证。
我们从文件的顶部开始,重点关注 mhbd 块。鉴于它的频率及其在文件开头的位置,它可能包含整个文件的标头信息。我们知道它的长度为 0x68 字节,并且我们使用标准标签和块长度字段仅解释了其中的八个字节。到目前为止,其他所有内容都由 4 字节数字组成,并且我们还剩下四个字节的倍数,因此我们将剩余的 96 个字节分解为 24 个 4 字节数字,如图 6 所示。

图 6. 剩余的 96 个字节
示例 iTunesDB 文件的大小为 571,616 字节。我们可以向验证程序添加一个测试,并验证 n1 是否是所有 iTunesDB 文件的文件大小。n2、n3、n4 三元组类似于版本号 (1.1.2)。查看多个 iTunesDB 文件告诉我们,对于来自较新 iPod 的 iTunesDB 文件,n2 到 n4 会更改为 1.2.2。n5 到 n24 始终为零。
将文件大小存储在标头中是一个奇怪的操作。我们确定了 mh 块的前八个字节的统一模式;也许字节 9-12 对于所有 mh 块都是一致的。我们修改了我们的验证程序,以输出所有 mh 块的字节 9-12 的值(有关结果,请参见图 7)。

图 7. 字节 9-12 的值
当我们将 n1 添加到 mhbd 块的文件位置时,我们到达了文件末尾。将 n1 添加到 mhod 块位置是下一个 mh 块的位置。对于 mhsd,将 0x73048 添加到 0x68 是 0x730b0。在我们的十六进制编辑器中转到该文件位置,向我们表明 0x730b0 是另一个 mhsd 块的开始。
mhit、mhyp 和 mhip 块的 n1 加文件位置值与 mhbd、mhsd 和 mhod 的值一致。图 8 包含这些块之间关系的示例。对于 mhlt 和 mhlp,n1 加上 mhlt/mhlp 文件位置的位置位于块的中间。在此示例中,mhlt 的 n1 值为 755,它是文件中 mhit 块的数量。mhlp 的 n1 值为 4,它是 mhyp 块的数量。这些关系表明嵌套的数据结构。如果我们使用 n1 大小来确定 mh 块之间的父子关系,我们可以创建如图 9 所示的树状图。这种对称性看起来太好了,不可能是错误的,因此我们将坚持将其作为我们的理论,除非我们稍后找到数据来说服我们否则。

图 8. mhit、mhyp 和 mhip 块与 mhbd、mhsd 和 mhod 块之间的关系
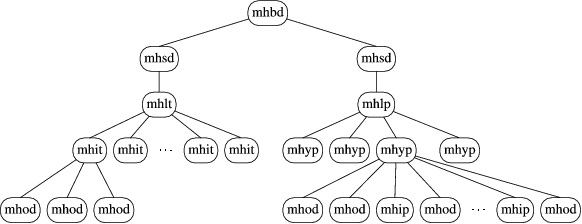
图 9. 父子 mh 块
从 mhbd 向下树状结构一层,我们有一对 mhsd 节点,每个节点长 104 字节。将初始 12 个字节后的数据分解为 4 字节数字向我们表明,只有第一个 4 字节数字包含任何非空数据。当子节点为 mhlt 时,它等于 1,当子节点为 mhlp 时,它等于 2。图 10 包含 mhsd 块的描述。

图 10. mhsd 块
继续向下到下一层,我们找到 mhlt 和 mhlp 节点。我们可以验证,在子节点数量之后,它们以 80 个空字节结尾,如图 11 所示。

图 11. mhlt 和 mhlp 节点
mhlt 节点的子节点是 mhit 节点。mhit 节点的数量对应于 iPod 上的歌曲数量。将第一个 mhit 块划分为 4 字节无符号整数会产生图 12 中的图表。

图 12. 将第一个 mhit 块划分为 4 字节无符号整数
仅从数量级来看,唯一看起来有点熟悉的数字是 n6。在 UNIX 中,时间通常确定为自 Epoch(1970 年 1 月 1 日 00:00:00 UTC)以来的秒数。但是,在 Apple 的 HFS+ 文件系统中,时间存储为自 1904 年 1 月 1 日 00:00:00 UTC 以来的秒数。将 3090924135 转换为日期得到 2001 年 12 月 11 日 06:02:15。我们还不能理解其余这些数字的含义,但是通过查看许多 mhit 块,我们注意到 n1 等于 mhod 子节点的数量,n3 始终为 1,n4 始终为零。
也许通过查看 mhit 块的 mhod 子节点,我们可以了解未知的 mhit 值表示什么。实际上,粗略查看一些 mhod 块(参见图 13)表明它们在后面包含可变长度的文本。

图 13. mhit 块的 mhod 子节点
我们知道 mhod 块的 n1(参见图 14)告诉我们 mhod 块的长度,包括文本数据。我们需要一个关于剩余 12 个字节包含什么内容的假设。

图 14. mhod 块的 n1
通过阅读文本,我们看到其中包含艺术家、专辑和标题字符串等。软件需要知道字符串的类型,字符串才有用。此信息可以通过始终按相同顺序排列字符串来提供:专辑、标题、艺术家、流派等等,但是如果歌曲没有专辑怎么办?那么,字符串的类型更有可能在块中的某个位置进行编码。n2 看起来是一个不错的选择。查看字符串和 n2 值,我们确定了表 1 中所示的关系。
文本数据不是纯 ASCII,因为字母(在本例中)由空字节分隔。由于每个字母都有两个字节,我们假设我们正在处理文本的多字节表示形式,最可能是 Unicode 编码。但是,在文本开始之前有 16 个字节,我们还没有解释它们。图 15 包含图 13 中所示的四个 mhod 块的 16 个未知字节。

图 15. 图 13 中所示的四个 mhod 块的 16 个未知字节
我们找到一个始终为 1 的 4 字节数字、一个可变的 4 字节数字和 64 位零。仔细检查后,第二个数字似乎随后续字符串的长度而变化,实际上是它的字节长度。我们将向我们的验证程序添加一个测试,以检查这是否对所有 mhod 字符串都成立。
我们的验证程序找到文本数据块,其中第一个数字为零而不是一。这些文本数据块紧跟类型为 100 的 mhod 块,可能是一个空字符串类型。图 16 包含 mhod 块的完整描述。

图 16. 完整的 mhod 块
我们可以使用 mhit 块的 mhod 子节点来弄清楚哪些歌曲与哪些 mhit 块相关。这有助于我们弄清楚 mhit 块的其余部分:n5 根据文件类型而变化;n7 是歌曲文件的大小。n8 是歌曲的持续时间(以毫秒为单位)。n9 是曲目编号。n12 是比特率。有关 mhit 数据块的图表,请参见图 17。

图 17. mhit 数据块
我们对树的左侧的分析已完成,使用它可以找到 iPod 上所有歌曲的信息。早些时候,我们假设 iTunesDB 文件的另一个主要用途是播放列表,因此我们将在树的右侧查找播放列表信息。
希望具有对称性,我们希望为每个播放列表找到一个 mhyp 块,就像每首歌曲都有一个 mhit 块一样。环顾四周,我们知道此 iPod 有三个播放列表,但有四个 mhyp 块。当我们在各种 iTunesDB 文件上运行我们的验证程序时,我们了解到 mhyp 块的数量总是比播放列表的数量多一个。
我们将使用我们的验证程序来显示有关 mhyp 块的子节点的信息。它向我们表明,每个 mhyp 块都有一个第一个子节点,它是一个空字符串 mhod 块(类型 100),带有神秘的额外 604 个空字节。然后它有一个带有字符串的 mhod 块。对于第一个 mhyp 块,这是 iPod 的名称;对于每个其他 mhyp 块,它是播放列表的名称。
在名称 mhod 块之后,是一系列 mhip 和 mhod 对,直到下一个 mhyp 块。该对的 mhod 部分是一个空字符串。这些对的数量等于播放列表中的歌曲数量。就第一个播放列表而言,它具有与 iPod 上的歌曲数量相同的 mhip/mhod 对。因此,我们可以推测,第一个播放列表是一个主播放列表,其中包含 iPod 上每首歌曲的一个条目。
我们知道播放列表是带有标题的歌曲的命名列表。我们已经找到了名称,但是我们需要弄清楚歌曲列表是如何存储的。我们首先查看图 18 中的 mhip 块。n5 与我们之前找到的日期的数量级相同。我们在 n2 的 mhit 数据中看到了 n4 (2626)。因此,我们可以猜测 n4 是歌曲标识号,并且 mhip 块使用歌曲标识号来指定播放列表中包含哪些歌曲。我们可以向验证程序添加一个测试,以将 mhip 块中的 n4 与 mhit 块中的 n2 匹配,以确认我们的理论。

图 18. mhip 块
剩余的 mhip 神秘之处在于 n3 数字在数量级上与歌曲键 n4 相似。如果我们更改我们的测试程序以查找其键是我们已经找到的键后面的数字的歌曲,我们将不会在任何 iTunesDB 文件中找到任何具有这些标识号的歌曲。因此,我们可以推断出,它是这些块的唯一标识号。向我们的验证程序添加一个测试证实它们确实是唯一的。图 19 包含 mhip 数据块的图表。

图 19. mhip 数据块
mhyp 块(参见图 20)是我们需要评估的最后一个块。n1 始终为 2。n2 是播放列表中的歌曲数量。主播放列表的 n3 设置为 1;所有其他播放列表都将其设置为 0。n4 是一个日期,可能是播放列表的创建日期。n5 和 n6 对于每个 mhyp 块都相同,并且 72 个空字节始终跟随它们。

图 20. mhyp 块
使用假设、模式识别和验证这三种逆向工程策略,我们解密了 iTunesDB 文件格式。希望此处介绍的想法将帮助 Linux 用户逆向工程更多设备和文件格式,以使其与 Linux 兼容。

