
2.6 内核简介
自从 Linus 在 2001 年 11 月 22 日从 2.4.15 分支创建 2.5.0 以来,内核已经走过了漫长的道路。从那时起,快速的开发随之而来,产生了一个截然不同且大为改进的内核。本文讨论了更有趣、更重要的功能及其对 Linux 性能和可靠性的影响。
在 Linux 内核术语中,内核的次版本号表示该内核属于稳定系列还是开发系列。偶数次版本号表示稳定内核,奇数次版本号表示开发内核。当开发内核完全成熟并被认为是稳定时,其次版本号会递增为偶数值。例如,2.3 内核开发系列让位于 2.4 稳定系列。
当前的开发内核是 2.5。开发系列的初始工作非常迅速,并融入了许多新功能和改进。当 Linus 和内核开发人员对新功能集感到满意时,就会声明功能冻结,其目的是减缓开发速度。上次功能冻结发生在 2002 年 10 月 31 日。理想情况下,当声明功能冻结时,Linus 将不会接受新功能——仅接受对现有工作的补充。当现有功能完成并接近稳定时,就会声明代码冻结。在代码冻结期间,仅接受错误修复,以便为稳定版本发布做准备。
当开发系列完成时,Linus 会将内核作为稳定版本发布。这一次,稳定内核很可能将是 2.6.0 版本。尽管官方发布日期是“完成时”,但一个好的估计是 2003 年第三季度或第四季度。
在 2001 年 3 月和 2002 年 6 月,核心内核开发人员在内核峰会上会面,讨论内核。2.5 的主要目标是将老化的块层(内核中负责块设备(如硬盘驱动器)的部分)带入 21 世纪。其他关注点集中在可扩展性、系统响应和虚拟内存 (VM) 上。内核黑客们实现了所有这些目标以及更多。重要的新功能列表包括
O(1) 调度器
抢占式内核
延迟改进
重新设计的块层
改进的 VM 子系统
改进的线程支持
新的声音层
在本文中,我将讨论许多已融入 2.5 内核并将出现在 2.6 中的新技术和创新。开发是许多个人辛勤工作的成果。我将避免提及姓名,因为如果我开始给予赞扬,我不可避免地会遗漏一些人,我宁愿不列名单,也不愿列出不完整或不正确的名单。《Linux 内核邮件列表》存档是了解谁做了什么的好来源。
进程调度器(或简称调度器)是内核中负责分配处理器时间的子系统。它决定哪个进程何时运行。这并非总是一件容易的工作。从可能大量的进程列表中,调度器必须确保最值得运行的进程始终在运行。当有大量可运行进程时,选择最佳进程可能需要一些时间。具有多个处理器的机器只会增加挑战。
改进调度器在需要的改进列表中名列前茅。具体来说,开发人员有三个具体目标
调度器应提供完整的 O(1) 调度。调度器中的每个算法都应在恒定时间内完成,而与正在运行的进程数量无关。
调度器应具有完美的 SMP 可扩展性。理想情况下,每个处理器都应具有自己的锁定和单独的运行队列。运行队列是调度器从中选择的可运行进程列表。
调度器应具有改进的 SMP 亲和性。它应自然地尝试将任务分组在特定的 CPU 上并在那里运行它们。它仅应在解决运行队列长度的不平衡时才将任务从一个 CPU 迁移到另一个 CPU。
新的调度器实现了所有这些目标。第一个目标是完整的 O(1) 调度。O(1) 表示在恒定(固定)时间内执行的算法。系统上可运行的任务数量——或任何其他变量——对执行调度器的任何部分所需的时间都没有影响。考虑一下决定接下来应运行哪个任务的算法。这项工作涉及查看优先级最高、剩余时间片的可运行任务。在之前的调度器中,该算法类似于
for (each runnable process on the system) {
find worthiness of this process
if (this is the worthiest process yet) {
remember it
}
}
run the most worthy process
使用此算法,必须检查每个进程的价值。这意味着对于 n 个进程,算法循环 n 次。因此,这是一个 O(n) 算法——它随着进程数量线性扩展。
相反,新的调度器相对于进程数量是恒定的;系统上是否有 5 个或 5,000 个可运行进程都无关紧要。选择并开始执行新进程始终需要相同的时间
get the highest priority level that has processes get first process in the list at that priority level run this process
在此算法中,可以简单地“获取最高优先级级别”和“获取列表中的第一个进程”,因为调度器会跟踪这些内容。它只需要查找而不是搜索这些值。因此,新的调度器可以选择要调度的下一个进程,而无需循环遍历所有可运行进程。
第二个目标是完美的 SMP 可扩展性。这意味着调度器在给定处理器上的性能与向系统添加更多处理器时保持不变,而之前的调度器并非如此。相反,由于锁争用,调度器的性能随着处理器数量的增加而降低。保持调度器及其所有数据结构一致的开销相当高,而这种争用的最大来源是运行队列。为了确保只有一个处理器可以同时操作运行队列,它受到锁的保护。这意味着,实际上,只有一个处理器可以同时执行调度器。
为了解决这个问题,新的调度器将单个全局运行队列划分为每个处理器唯一的运行队列。这种设计通常称为多队列调度器。每个处理器的运行队列都有系统上可运行任务的单独选择。当特定处理器执行调度器时,它仅从其运行队列中选择。因此,运行队列接收到的争用少得多,并且性能不会随着系统中处理器数量的增加而降低。图 1 是具有全局运行队列的双处理器机器与具有每个处理器运行队列的双处理器机器的示例。

图 1. 左图,2.4 运行队列;右图,2.5/2.6 运行队列
第三个也是最后一个目标是改进的 SMP 亲和性。之前的 Linux 调度器具有在多个处理器之间反弹进程的不良特性。开发人员将此行为称为乒乓效应。表 1 展示了这种效应的最坏情况。
新的调度器解决了这个问题,这要归功于新的每个处理器运行队列。由于每个处理器都有唯一的运行进程列表,因此进程保留在同一处理器上。表 2 显示了这种改进行为的示例。当然,有时进程确实需要从一个处理器移动到另一个处理器,例如当每个处理器上的进程数量不平衡时。在这种情况下,特殊的负载均衡器机制会将进程迁移到均匀分配运行队列。此操作发生频率相对较低,因此 SMP 亲和性得到了很好的保留。
新调度器具有比其名称暗示的更多的功能。表 3 是一个基准测试,展示了新调度器的性能。
内核抢占的目的是降低调度延迟。结果是改进的系统响应和系统交互的 感觉。Linux 内核在 2.5.4 版本中变为抢占式内核。以前,内核代码以协作方式执行。这意味着进程(即使是实时进程)也无法抢占在内核中执行系统调用的另一个进程。因此,较低优先级的进程可以通过在较高优先级的进程请求处理器时拒绝其访问来使较高优先级的进程发生优先级反转。即使较低优先级进程的时间片已到期,它也会继续运行,直到它完成在内核中的工作或自愿放弃控制。如果等待运行的较高优先级进程是用户正在键入的文本编辑器或准备重新填充其音频缓冲区的 MP3 播放器,则结果是交互性能较差。更糟糕的是,如果较高优先级的进程是专用的实时进程,则结果可能是灾难性的。
为什么内核一开始不是抢占式的?因为提供抢占式内核需要更多的工作。如果内核中的任务可以随时重新调度,则必须采取保护措施来防止并发访问共享数据。值得庆幸的是,抢占式内核创建的问题与对称多处理 (SMP) 引起的问题相同。为 SMP 提供保护的机制很容易适应于为内核抢占提供保护。因此,内核只是利用 SMP 自旋锁作为抢占标记。当代码持有锁时,抢占也会被禁用。否则,可以安全地抢占当前任务。
很可能,现在可以看到下一个瓶颈。抢占式内核只是将调度延迟从整个内核执行时间缩短到自旋锁的持续时间。当然,它肯定更短了,但这仍然是一个潜在的问题。值得庆幸的是,可以缩短锁持续时间,这等于禁用内核抢占的时间长度。
内核开发人员优化了内核算法以降低延迟。他们主要专注于 VM 和虚拟文件系统 (VFS),因此大大缩短了锁持续时间。结果是出色的系统响应。用户观察到 2.5 中的最坏情况调度延迟,即使在普通机器上,也小于 500 纳秒。
块层是内核中负责支持块设备的部分。传统的 UNIX 系统支持两种通用类型的硬件设备,字符设备和块设备。字符设备(如串行端口和键盘)一次处理一个字符或字节的数据流。相反,块设备以固定大小(称为块)的组处理数据。块设备不仅仅发送或接收数据流;相反,它们的任何块都是可访问的。从一个块移动到另一个块称为寻道。块设备的示例包括硬盘驱动器、CD-ROM 驱动器和磁带备份设备。
管理块设备是一项重要的工作。硬盘驱动器是复杂的硬件部件,操作系统需要支持对其进行任意读写任何有效块。此外,由于寻道成本很高,因此操作系统必须智能地管理和排队对块设备的请求,以最大程度地减少寻道。
Linux 中的块层迫切需要重新设计。值得庆幸的是,从内核 2.5.1 开始,改造开始了。最有趣的工作包括创建新的灵活和通用的结构来表示块 I/O 请求,消除反弹缓冲区并支持直接 I/O 到高内存,使全局 io_request_lock 每个队列一个,并构建新的 I/O 调度器。
在 2.5 之前,块层使用 buffer_head 结构来表示 I/O 请求。这种方法效率低下,原因有几个,最大的原因是块层通常必须将数据结构分解成更小的块,然后才能在 I/O 调度器中重建它们。在 2.5 中,内核使用新的数据结构 struct bio 来表示 I/O。此结构更简单,适用于原始和缓冲 I/O,可与高内存一起使用,并且可以轻松拆分和合并。块层始终如一地使用新的 bio 结构,从而产生更简洁、更高效的代码。
下一个问题是消除在执行 I/O 到高内存时使用的反弹缓冲区。在 2.4 内核中,从块设备到高内存的 I/O 传输必须进行一次不幸的额外停止。高内存是内核必须提供特殊支持的非永久映射内存。在 Intel x86 机器上,这是任何超过约 1GB 的内存。任何到高内存的 I/O 请求(例如,将文件从硬盘驱动器读取到大于 1GB 的内存地址)都必须使用驻留在低内存中的特殊反弹缓冲区。理由是一些设备可能无法理解高内存地址。结果是设备始终必须将其 I/O 传输到低内存。如果最终目的地实际上是高内存,则数据必须从块设备反弹到低内存,最后进入高内存(图 2)。这种额外的复制引入了巨大的开销。2.5 内核现在自动支持直接传输到高内存,从而消除了适用于设备的bounce buffer逻辑。

图 2. 2.4 内核中的反弹缓冲区
开发人员解决的下一个瓶颈是全局 I/O 请求锁。每个块设备都与一个请求队列相关联,该队列存储块 I/O 请求,即表示每个块读取或写入的单个 bio 结构。内核不断更新队列,因为驱动程序添加或删除请求。io_request_lock 保护队列免受并发访问——代码只能在持有锁时更新队列。在 2.5 之前的内核中,单个全局锁保护系统中的所有请求队列。全局锁阻止并发访问 任何 队列,而锁只需要阻止并发访问任何单个队列。在 2.5 中,每个队列的细粒度锁取代了全局请求锁(图 3)。因此,内核现在可以同时操作多个队列。
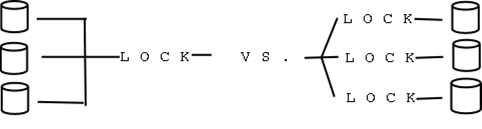
图 3. 2.5 内核为每个请求队列引入一个锁。
最后,新的 I/O 调度器解决了剩余的块层低效问题。I/O 调度器负责合并块请求并将它们发送到物理设备。由于寻道成本很高,因此 I/O 调度器更喜欢为连续请求提供服务。为此,它按扇区对传入请求进行排序。这对于磁盘性能和寿命而言都是一项重要功能。但是,问题是,对连续扇区的重复 I/O 请求可能会阻止为非相邻扇区的请求提供服务。新的 I/O 调度器通过为 I/O 请求实施截止日期来解决此问题。如果 I/O 调度器使请求超过其截止日期,则 I/O 调度器将为超时的请求提供服务,而不是继续合并当前扇区的请求。新的 I/O 调度器还通过优先处理读取请求而不是写入请求来解决写入饿死读取的问题。此更改大大提高了读取延迟。最后但并非最不重要的一点是,请求队列现在是一棵红黑树,这是一种易于搜索的数据结构,而不是线性列表。
在 2.5 期间,VM 最终成为现实。VM 子系统是内核中负责管理每个进程的虚拟地址空间的组件。这包括内存管理方案、页面驱逐策略(内存不足时要换出什么)和页面调入策略(何时将内容换回)。VM 长期以来一直是 Linux 的一个难题。在特定工作负载下良好的 VM 性能通常意味着在其他地方性能较差。公平、简单、经过良好调整的 VM 似乎总是难以实现——直到现在。
新的 VM 是三个主要更改的结果
反向映射 (rmap) VM
重新设计、更智能、更简单的算法
与 VFS 层更紧密的集成
最终结果是在常见情况下具有卓越的性能,而 VM 在极端情况下也不会惨败。让我们简要了解一下这三个更改中的每一个。
任何虚拟内存系统都具有物理地址(物理 RAM 芯片上实际页面的地址)和虚拟地址(呈现给应用程序的逻辑地址)。具有内存管理单元 (MMU) 的架构允许方便地从虚拟地址查找物理地址。这是理想的,因为程序不断访问虚拟地址,并且硬件需要将其转换为物理地址。但是,反向移动并不容易。为了从物理地址解析为虚拟地址,内核需要扫描每个页表条目并查找所需的地址,这非常耗时。反向映射 VM 提供从虚拟地址到物理地址的反向映射。因此,代替
for (each page table entry)
if (this physical address matches)
we found a corresponding virtual address
rmap VM 只需通过跟踪指针即可查找虚拟地址。这种方法速度更快,尤其是在 VM 压力密集的情况下。图 4 是反向映射的图表。

图 4. 反向映射将一个物理页面映射到一个或多个虚拟页面。
接下来,VM 黑客重新设计并改进了许多 VM 算法,同时考虑到简化性、出色的平均情况性能和可接受的极端情况性能。由此产生的 VM 得到了简化,但更加强大。
最后,VM 和 VFS 之间的集成得到了极大的改进。这至关重要,因为这两个子系统密切相关。文件和页面写回、预读和缓冲区管理得到了简化。内核线程 pdflush 池取代了内核线程 bdflush。新线程能够提供大大改进的磁盘饱和度;一位开发人员指出,该代码可以保持 六十个 磁盘主轴同时饱和。
Linux 中的线程支持似乎总像是事后才想到的。线程模型与典型的 UNIX 进程模型不太吻合,因此,Linux 内核在使线程感觉受欢迎方面做得很少。作为 glibc(GNU C 库)一部分的用户空间 pthread 库(称为 LinuxThreads)没有从内核获得太多帮助。结果是线程性能不佳。有很多改进的空间,但前提是内核和 glibc 黑客协同工作。
欢呼吧,因为他们做到了。结果是大大改进的内核对线程的支持和一个新的用户空间 pthread 库,称为本机 POSIX 线程库 (NPTL),它取代了 LinuxThreads。NPTL 就像 LinuxThreads 一样,是 1:1 线程模型。这意味着每个用户空间线程都存在一个内核线程。开发人员在不诉诸 M:N 模型(其中内核线程的数量可能动态地少于用户空间线程的数量)的情况下实现了出色的性能,这令人印象深刻。
内核更改和 NPTL 的组合带来了改进的性能和标准合规性。一些新的更改包括
线程本地存储支持
O(1) exit() 系统调用
改进的 PID 分配器
clone() 系统调用线程增强
线程感知代码转储支持
线程信号增强
一种新的快速用户空间锁定原语(称为 futex)
结果不言自明。在给定的机器上,使用 2.5 内核和 NPTL,同时创建和销毁 100,000 个线程所需的时间不到两秒。在同一台机器上,如果不进行内核更改和 NPTL,相同的测试大约需要 15 分钟。
表 4 显示了 NPTL、NGPT(IBM 的 M:N pthread 库,下一代 POSIX 线程)和 LinuxThreads 之间线程创建和退出性能的测试结果。此测试还创建了 100,000 个线程,但并行增量要小得多。如果您还没有印象深刻,那您真是太难被说服了。
期待已久的高级 Linux 声音架构 (ALSA) 合并于内核 2.5.5 开始。ALSA 比之前的声音层开放声音系统 (OSS) 有许多改进。最重要的是,ALSA 提供了比 OSS 更强大且功能更丰富的 API。ALSA 驱动程序和随附的用户空间库 (alsa-lib) 允许以最少的努力创建高级音频应用程序。
ALSA 支持大量声音设备,并提供向后兼容的 OSS 接口。但是,对于仍然需要或喜欢 OSS 的用户,驱动程序很可能会保留到 2.6。
在 2.6 甚至发布之前就开始展望 2.6 之后可能有点不负责任。但是,考虑一下我们可能会在 2.7 开发内核中看到(或至少希望看到)的内容很有趣。如果运气好的话,我们将看到期待已久的 tty(终端)层重写。tty 层已经发展成为一个庞大而令人困惑的 hack。
每个人愿望清单上的另一个重要事项是 SCSI 层重写。目前,SCSI 层太笨,其驱动程序太智能。也可能将 IDE 和 SCSI 层的部分统一到通用磁盘层中。无论如何,SCSI 层都需要进行一些清理。
在这些项目之后,其余的都是不确定的。做出任何预测都是有风险的;以上仅仅是我们今天需要的观察结果。与往常一样,2.7 中的实际工作将取决于开发人员想要解决的难题。
无论未来如何,2.6 内核看起来都很棒——出色的可扩展性、快速的桌面响应、改进的公平性以及愉快合作的 VM 和 VFS 层。

Robert Love 是一位内核黑客,致力于各种项目,包括抢占式内核和调度器。他是佛罗里达大学数学与计算机科学专业的学生,也是 MontaVista Software 的内核工程师。他讨厌鱼。
