
Reiser4,第二部分:设计良好缓存的树
本文是关于 Reiser4 文件系统设计的系列文章的第二篇。第一篇文章[LJ, 2002年12月]定义了基本概念:树、节点和项。本文解释了为什么平衡树比非平衡树更好,以及为什么 B+ 树比 B 树更好,方法是解释和应用缓存原理。然后,本文将这些相同的原理应用于 ReiserFS v3 中使用的一种经典数据库技术,称为二进制大对象 (BLOB)。它表明 BLOB 通过使树不再真正平衡,降低了内部节点缓存的有效性。它还展示了 Reiser4 如何在不破坏树平衡的情况下存储大于节点的对象。
对于本文的延迟发布,我向读者致歉,这是由于 2.6 版本的万圣节功能冻结以及当时需要快速稳定 Reiser4 所致。
扇出率 (n) 指的是每个级别的节点指向的下一级别节点的数量(图 1)。如果每个节点可以指向下一级别的 n 个节点,那么从顶部开始,根节点指向下一级别的 n 个内部节点,每个内部节点又指向其下一级别的 n 个内部节点,依此类推。 m 级内部节点可以指向 nm 个叶节点,叶节点包含最后一级别的项。您想在树中存储的内容越多,您就必须使键中的字段越大,这些字段首先区分对象,然后选择对象的各个部分(偏移量)。这意味着您的键必须更大,这将降低扇出(除非您压缩您的键,但这将在我们的下一个版本中讨论)。

图 1. 三个四层高度平衡树
在图 1 中,第一个图是一个四层树,扇出率为 n = 1。它只有四个节点,从(红色)根节点开始,遍历(酒红色)内部节点和(蓝色)枝节点,最后到达(绿色)叶节点,叶节点包含数据。第二个树,具有四层和扇出率 n = 2,从一个根节点开始,遍历两个内部节点,每个内部节点指向两个枝节点(总共四个枝节点),而每个枝节点又指向两个叶节点,总共八个叶节点。最后,展示了一个四层、扇出率 n = 3 的树,它有一个根节点、三个内部节点、九个枝节点和 27 个叶节点。
您不仅可以在内部节点中存储指针和键,还可以存储这些键对应的对象。这是原始 B 树算法所做的(图 2)。
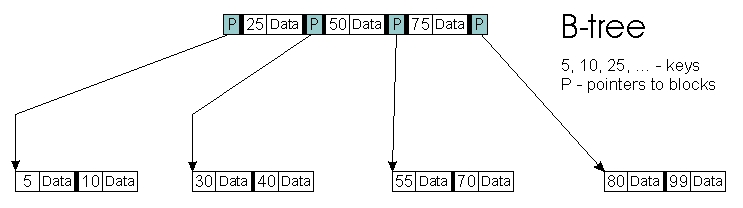
图 2. B 树
然后,发明了 B+ 树,它只在内部节点中存储指针和键,而所有对象都存储在叶级别(图 3)。
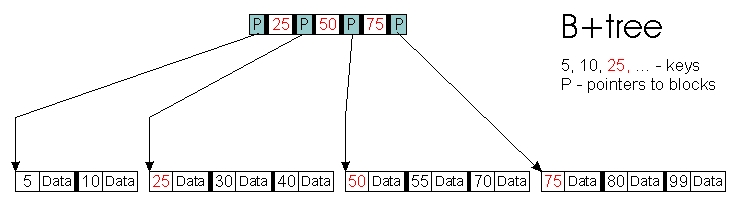
图 3. B+ 树
当我们在内部节点中仅放置指针和键,而不使用对象数据稀释它们时,扇出就会增加。扇出的增加提高了我们缓存所有内部节点的能力,因为内部节点更少。人们经常对此回应说,“但是 B 树缓存对象,而缓存对象也同样有价值。” 平均而言,这不是答案。当然,讨论平均值会使讨论变得更加困难。
但是,在讨论这个问题之前,我们需要介绍一些缓存设计原则。让我们假设以下情况:
您有两组事物,A 和 B。
您需要从这两组事物中半随机地获取事物,某些事物比其他事物更频繁地被需要,但哪些事物是更频繁的可能会随时间而变化。
您可以在使用后将事物保存在大小有限的缓存中。
您将来自 A 的每个事物的缓存与来自 B 的某个特定事物的缓存联系起来。这意味着,每当您从 A 中获取某事物到缓存中时,您都会将其来自 B 的伙伴也获取到缓存中。
这增加了存储最近从 A 访问的所有事物所需的缓存量。如果对每个配对中绑定的两个特定对象的需求之间存在很强的相关性,并且这种相关性强于通过根据 LRU(最近最少使用)算法将这些缓存资源用于缓存更多 A 和 B 成员所获得的收益,那么这可能是值得的。如果不存在如此强的相关性,那就不好。LRU 意味着当我们需要腾出更多空间时,我们选择最近最少使用的事物从缓存中丢弃。LRU 的各种近似算法是操作系统设计中最常用的缓存算法。
但是等等,您可能会说,您也需要来自 B 的事物,所以缓存它们中的一些事物是好的。是的,您需要 B 的一些随机子集。问题在于,在没有相关性的情况下,您需要的来自 B 的事物不太可能是那些与需要的来自 A 的事物绑定的相同来自 B 的事物。根据 LRU 以外的其他依据选择将 B 中的哪些事物带入缓存并保留在缓存中可能会降低缓存的有效性,除非它是根据至少与 LRU 一样好的算法完成的。通常,根据 A 的哪些成员已被缓存来选择缓存 B 的哪些成员不如 LRU,因此我们遇到了问题。
这种低效地将随机需要的事物联系起来的趋势在计算机行业之外也存在。例如,假设您既喜欢爆米花又喜欢寿司,您在特定某天对它们的需求是随机的。假设您随机地喜欢电影。假设一家电影院要求您在观看您随机发现最适合观看的电影时只能吃爆米花,而不能在观看同一部电影时吃角落餐厅的寿司。这是一个社会最优系统吗?假设质量在所有热狗摊贩中随机分布。如果您只能在您想看电影的特定晚上吃最佳电影放映商生产的热狗,并且您不允许从电影院外带入热狗,这是一个社会最优系统吗?对您来说最优吗?
然而,将强相关的事物联系在一起有时可能对性能有好处。许多文件系统将对文件大小信息的访问与对文件名称信息的访问联系起来。这似乎效果很好,比 LRU 更好。
将不相关的事物联系在一起是设计缓存时常见的错误,但这仍然不足以描述为什么 B+ 树更好。对于内部节点,我们每个节点存储多个指针,这意味着指针不是单独缓存的。您可能会争辩说,指针和它们指向的对象比不同的指针更强相关。我希望我们在此处讨论的内容具有启发性,但我们仍然需要另一个缓存设计原则。
让某事物的缓存温度等于您访问它的频率,乘以从磁盘获取它的平均成本,再除以它消耗的缓存字节数。您可能会注意到这个定义中某种程度的谨慎和缺乏精确细节——特别是,由于执行寻道的成本,单独读取的小对象往往更热。缓存温度的其他定义也是可能的,但这个定义对于本文来说是最方便的。
如果有两种类型的事物缓存在节点中,它们的平均温度不同,则将它们隔离到单独的节点中有助于缓存。假设您有 R 字节的 RAM 用于缓存,D 字节的磁盘。假设 80% 的访问是针对存储在 H(热集)字节节点中的最近使用的事物。减小 H 的大小,使其小于 R 对于性能至关重要。如果您均匀分散您频繁访问的数据,则需要更大的缓存,并且缓存效率会降低。
如果所有其他条件都相同,我们增加所有节点之间温度的变化,我们就会提高使用快速小缓存的效率。
如果两种类型的事物具有不同的平均温度,则将它们分离到单独的节点中会增加整个系统中温度的变化。
如果所有其他条件都相同,并且如果缓存在一个节点中的两种类型的事物具有不同的平均温度,则将它们隔离到单独的节点中反而有助于缓存。
相对于缓存它们所需的字节数而言,指向节点的指针往往会被频繁访问。考虑到您必须使用指针进行所有到达其下方节点的树遍历,并且它们比它们指向的节点小。
仅将节点指针和分隔键放入内部节点中会集中指针。由于指针的每字节大小的访问频率往往比存储文件主体的项高两个数量级,因此指针和对象数据之间存在较高的平均温度差异。
根据前面描述的缓存原则,隔离这两种平均温度不同的事物(指针和对象数据)会提高缓存效率。
现在您可能会说,为什么不按实际温度而不是按类型隔离,因为类型仅与温度相关?我们尽我们所能轻松有效地编码,而不仅仅考虑温度隔离。一些树设计重新排列树,使温度较高的对象在树中的位置高于温度较低的指针。对象数据和指向节点的指针之间的平均温度差异非常大,以至于我不认为这种设计是一种引人注目的优化,而且它们增加了复杂性。考虑到两个数量级的平均温度差异,我怀疑如果我错了,那也不值得关注。
顺便说一句,尽管这些提到的其他树设计只是根据温度将对象迁移到树的更高位置,但如果仅仅是按温度隔离而不改变级别,可能会更有效。如果对于将对象聚集在一起没有令人信服的语义基础(对于某些应用程序来说是这样),并且如果人们希望按节点而不是单独访问对象,那么将对象数据按温度排序到节点中将是一件有趣的事情。
B+ 树将指针和数据分离到不同的节点中。平均而言,树节点的指针比存储在树中的事物的数据更热(大约两个数量级)。因此,根据前面解释的缓存原则,通过将指向节点的指针与存储在树中的事物的数据分离,可以提高缓存效果。
在行业中,实践证明 B+ 树比 B 树更好,正如该理论预测的那样。高度平衡树比非平衡树性能更好也是公认的常识。
目前尚未被广泛接受,但通过应用这些原则可以预测的是,数据库行业所谓的 BLOB 的使用会损害性能。稍后会详细介绍(以及 BLOB 是什么)。
术语“平衡”在平衡树文献中用于几个不同的目的。最常见的两个是树节点内的高度平衡和空间使用平衡。不幸的是,这些不同的定义是文献读者经典困惑的来源,我将尽力避免在本文中出现这种情况。
高度平衡树是指从根节点到叶节点的每条可能的搜索路径都具有完全相同的长度;长度等于从根节点到叶节点遍历的节点数。例如,图 1 中树的高度为 4,图 4 中树的高度为 3,单节点树的高度为 1。

图 4. 三层树
大多数实现高度平衡的算法都是通过仅在顶部增长树来实现的。因此,树永远不会失去高度平衡。
图 5 显示了一个非平衡树。它最初可能是平衡的,然后由于删除而丢失了一些内部节点,或者它可能曾经是平衡的,但现在正在通过插入而增长,但尚未进行重新平衡。
图 5. 非平衡树
用于存储大于节点的对象(BLOB)的传统数据库方法使树变得不平衡。BLOB 是一种通过存储指向包含对象的节点的指针来存储大于节点的对象的方法。这些指针通常存储在所谓的“B*”树的叶节点(级别 1,除了 BLOB 然后有点像地下室“级别 B”)中。
在图 6 中,一个 BLOB 已被插入到四层树的叶节点中,这意味着指向包含文件数据的块的指针已被插入到叶节点中。这就是 ReiserFS v3 树的样子。
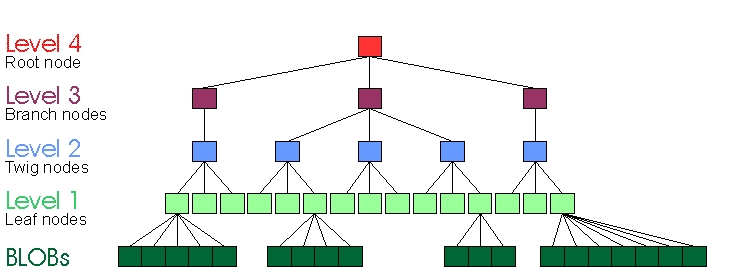
图 6. 插入 BLOB 后的四层树
这是一个重要的定义漂移,尽管整个数据库社区都接受它。根据此处描述的缓存原则,这减少了指针和对象数据的分离,进而降低了缓存的有效性。我建议这些缓存原则表明这是一个糟糕的设计。由于 B+ 树比 B 树更好,Reiser4 树也比 ReiserFS v3 树更好,尽管程度较小。
相比之下,图 7 是一个扇出率为 3 的 Reiser4 树,在级别 1 叶节点中有一个 BLOB,在级别 3 枝节点中有一个指向它的指针。在这种情况下,BLOB 的块都是连续的。出于空间原因,它设置在其他叶节点下方,但其范围指针位于级别 2 枝节点中,就像每个其他项的指针一样。
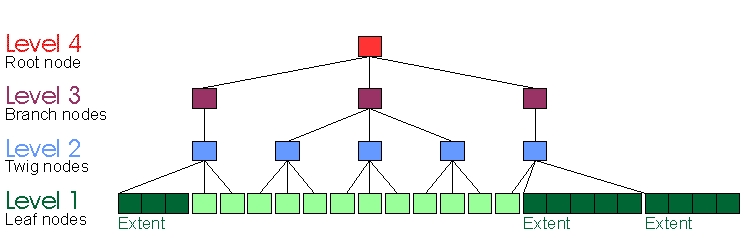
图 7. Reiser4 树将 BLOB 存储在级别 1 叶节点中。
尽管 B+ 树比 B 树更好是公认的,但 BLOB 是糟糕的设计尚未被广泛接受,事实上,它是数据库行业中的主导范例。
Gray 和 Reuter 说,搜索外部存储器的标准是“最小化平均(或最长)搜索路径上不同页面的数量……通过减少任意搜索路径的不同页面数量,可以降低必须从磁盘读取块的概率”(请参阅参考资料)。
我对这种对高度平衡方法有效性的解释的问题是,它没有传达出即使您有一个适度不平衡的树,只要您没有显着增加内部节点的总数,您也可以摆脱困境。实际上,大多数不平衡的树确实具有明显更多的内部节点。实际上,大多数适度不平衡的树在内存中树遍历的成本方面有适度的增加,并且由于缓存中剩余的内部节点数量过多,导致 I/O 量不成比例地增加。
但是,如果将所有 BLOB 放在树中的同一位置,因为内部节点的数量不会显着增加,那么将它们放在树的较低级别而不是所有其他叶节点上的性能损失将不会是一个显着的额外 I/O 成本。树遍历时间成本中依赖于 RAM 速度的部分会适度增加,但这不会那么关键。隔离 BLOB 可能会显着恢复架构师没有注意到树的高度平衡定义漂移而造成的性能损失。对于隔离 BLOB,可能还存在与树考虑因素无关的显着 I/O 相关性能影响。也许有一天有人会尝试一下并告诉我们结果如何。
Reiser4 返回到高度平衡树的经典定义,其中到所有叶节点的路径长度相等。它并没有假装所有存储大于节点的对象的节点在某种程度上不是树的一部分,即使树存储了指向它们的指针。
Reiser4 减少了内部节点(包含指针的节点)的数量,使其少于 ReiserFS v3 所需的数量。ReiserFS v3 存储 188MB Linux kernel 2.4.1 源代码树所需的内部节点数为 1,629 个。Reiser4 仅需要 164 个。因此,Reiser4 中存储节点指针所需的 RAM 量大大减少。
Hans Reiser (reiser@namesys.com) 在完成八年级后于 1979 年进入加州大学伯克利分校,并主修“系统化”,这是一个基于理论模型发展研究的个人专业。他的毕业论文讨论了硬科学哲学与计算机科学哲学的不同之处,并以命名系统的发展作为案例研究。他仍在实施该命名系统,Reiser4 是该命名系统的存储层。

