
如何索引任何内容
您可能出于多种原因想要构建文档的自定义索引。一个被广泛引用的原因是为网站提供搜索功能,但您也可能想要索引您的电子邮件或技术文档。任何研究过实现这种功能的人可能都会发现它并不像看起来那么容易。各种因素共同作用,使搜索变得困难。
历史悠久且不可或缺的 grep 及其同类产品在扫描文本行方面非常有效。但是 grep、egrep 及其相关工具无法为您完成所有工作。它们无法跨行搜索,不会以排序顺序显示搜索结果,并且它们的线性搜索算法不适合搜索大量数据。
HTML 也没有帮助解决这种情况。其面向显示的特性、特殊的语法以及大量的格式和实体标签使其很难被正确解析。
在数据存储频谱的另一端是数据库中的数据槽。普遍的例子是 SQL 数据库,它允许某种程度的复杂搜索功能,但通常搜索速度不是特别快。一些数据库引擎,特别是 MySQL 4,通过允许快速和排序的搜索来解决这个问题,但它们可能不如期望的那样可定制。
在本文中,我们将探讨在 Linux 上使用 SWISH-E、Perl 和 XML 创建自定义索引的方法。通过示例,我们将展示如何使用 SWISH-E 构建 HTML 文件、PDF 文件和 man pages 的索引。
SWISH-E(simple web indexing system for humans—enhanced,人类增强型简单 Web 索引系统)是 SWISH 的后代,SWISH 由 Kevin Hughes 于 1994 年创建。SWISH 于 1996 年被移交给加州大学伯克利分校图书馆,以修复错误和添加功能,结果以 GPL 许可发布并更名为 SWISH-E。开发仍在继续,由当前项目维护者 Bill Moseley 领导,并由一个开发团队协助。
在 SkateboardDirectory.com,我们在研究索引工具包时偶然发现了 SWISH-E。我们发现它提供了一系列独特的功能组合,使其对我们的目的具有吸引力。SWISH-E 不仅提供了一个快速而强大的工具包,用于构建和查询索引,而且文档齐全,正在进行积极的开发和错误修复,并且包含 Perl 接口。我们也喜欢维护者 Moseley 和其他经验丰富的 SWISH-E 用户和开发人员通常会及时解决在 SWISH-E 邮件列表中提出的问题和错误。
在我们的示例中,我们从安装了软件包的软件开发包的库存 Red Hat 7.3 工作站开始。我们还在 Red Hat 6.2 工作站和 Debian Woody 上测试了这些示例。
目前,在 Red Hat 上安装 SWISH-E 意味着从源代码安装,并且需要 zlib 和 libxml2 库才能完全构建 SWISH-E。如果您发现需要安装其中任何一个,您可能会找到您的发行版提供的软件包。我们的示例中也使用了 xpdf 软件包,因此如果尚未安装,您可能需要立即安装它。我们的参考 Red Hat 7.3 工作站设置已安装了 SWISH-E 的所有先决条件。
在这里,我们描述 SWISH-E 2.4 的使用,根据开发团队的说法,该版本应该在您阅读本文时发布。您可以使用以下命令序列获取和设置 SWISH-E,将当前版本替换为 (x.x)
% wget \ http://swish-e.org/Download/swish-e-x.x.tar.gz % tar zxf swish-e-x.x.tar.gz % cd swish-e-x.x % ./configure % make % make test
要将 SWISH-E 二进制文件、C 库和 man pages 安装到 /usr/local 中的默认位置,请以 root 身份键入 make install。这会将 SWISH-E 可执行文件安装到 /usr/local/bin 中。如果此目录不在您的 PATH 中,请更改您的相应点文件以在 PATH 中包含 /usr/local/bin,或者始终通过完整路径名(如 /usr/local/bin/swish-e)调用 swish-e 可执行文件。
现在,让我们从源 Perl 目录中构建和安装 SWISH::API Perl 模块。稍后当我们为我们的 man pages 索引构建 Perl 客户端时,我们将需要它。SWISH::API 通过正常的 Perl 模块安装过程设置
% cd perl % perl Makefile.PL % make % make test
然后,通过以 root 身份键入 make install 来安装 SWISH-E Perl 模块。
现在 SWISH-E 和 SWISH::API Perl 模块已完全安装,让我们构建一个简单的 HTML 文件索引来测试 SWISH-E。对于此示例,我们索引 Linux 文档项目 (LDP) HOWTOs 的 HTML 单页分节版本,我们已将其解压缩到 ~/HOWTO-htmls/ 中。本文中使用的 LDP 文档 tarball 来自 www.tldp.org/docs.html。
使用 SWISH-E 构建索引的第一步是编写配置文件。创建一个目录,例如 ~/indices,cd 进入该目录并创建文件 ./howto-html.conf,内容如下
# howto-html.conf IndexDir ../HOWTO-htmls/ IndexOnly .html IndexFile ./howto-html.index
IndexDir 指令指定 SWISH-E 应在其中查找要索引的文件的目录。IndexOnly 指令请求仅索引以 .html 结尾的文件。最后,要创建的索引的位置由 IndexFile 指令指定。
现在,让我们使用以下命令构建我们的 HTML 文件索引
% swish-e -c howto-html.conf
-c 选项指定要使用的 SWISH-E 配置文件。在较旧的系统上,构建此索引可能需要几分钟左右;在现代系统上,它应该在一分钟内完成。图 1 说明了使用 SWISH-E 在文件系统上索引 HTML 文件的过程。
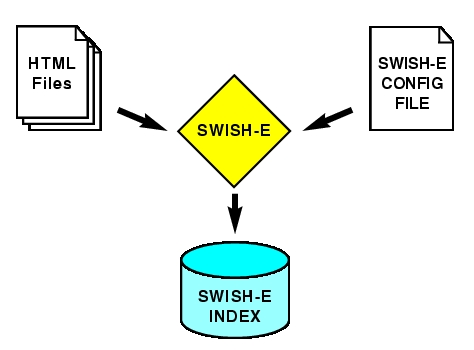
图 1. 使用 SWISH-E 在文件系统上索引 HTML
让我们通过简单搜索与术语 NFS 相关的 HTML 文件来测试我们的第一个索引。您可以使用 swish-e 可执行文件快速测试 SWISH-E 索引,方法是使用 -f 选项指定索引,并使用 -w 选项指定要搜索的文本;对 SWISH-E 索引的搜索不区分大小写。因为我们预计很多页面(或命中)会包含单词 NFS,所以我们使用 -m 3 选项仅请求三个
% swish-e -f howto-html.index -m 3 -w nfs
这将返回(已删节和重新格式化)
1000 ../HOWTO-htmls/NFS-HOWTO/performance.html
"Optimizing NFS Performance" 33288
998 ../HOWTO-htmls/NFS-HOWTO/intro.html
"Introduction" 10966
993 ../HOWTO-htmls/NFS-HOWTO/security.html
"Security and NFS" 35968不错——这些页面肯定是关于 NFS 的,并且输出是直观的。第一列是 SWISH-E 给每个命中的排名——被认为最相关的命中始终排名 1000,不太相关的文件按降序排名。第二列显示文件名,第三列给出页面的标题,第四列显示索引数据的字节计数。SWISH-E 使用其 HTML 解析引擎之一从每个文件中的 HTML 标签确定每个页面的标题。
内置的 SWISH-E 解析引擎称为 TXT、HTML 和 XML,每个引擎都旨在解析相应类型的内容。最新版本的 SWISH-E 还可以使用 libxml2 库作为 HTML2 和 XML2 解析后端。XML2 和 HTML2 解析器都优于其内置的对应物——尤其是 HTML2。这就是为什么最新版本的 libxml2,虽然在构建 SWISH-E 时技术上是可选的,但可能应该被视为先决条件。
SWISH-E 支持功能齐全的文本检索搜索语言,其语法包括 AND、OR、NOT 和括号分组,所有这些都可预测地工作。例如,以下搜索都具有预期的语义
% swish-e -f howto-html.index -w nfs AND tcp
% swish-e -f howto-html.index -w nfs OR tcp
% swish-e -f howto-html.index \
-w '(gandalf OR frodo) OR (lord AND rings)'SWISH-E 配置文件是简单的文本文件,其中每一行要么是指令,要么是注释。SWISH-E 会忽略任何第一个非空白字符为 # 的行作为注释。所有其他非空行应采用以下形式
Directive Options [Options] ...
如果您需要指定带有嵌入空格的选项,可以使用引号
Directive "Option With Spaces!"
如果选项中包含单引号,则可以使用双引号字符引用它,反之亦然,例如
Directive "Fred's Index Option" Directive 'By Josh "joshr" Rabinowitz'
数十个指令可以应用于 SWISH-E 配置文件。详尽的参考可以在 SWISH-E 文档中找到。
每个 SWISH-E 索引都存储在一对文件中。一个文件的名称在 IndexFile 指令中指定,另一个文件称为 indexname.prop。当谈论 SWISH-E 索引时,我们指的是这对文件。
索引可能会变得很大。在我们的 HTML 文件示例索引中,该索引占用约 11MB,约为原始索引文件大小的四分之一。
到目前为止,我们只讨论了索引 HTML、XML 和文本文件。这是一个更高级的示例:索引来自 Linux 文档项目的 PDF 文档。
为了让 SWISH-E 索引任意文件(PDF 或其他文件),我们必须将文件转换为文本,理想情况下类似于 HTML 或 XML,并安排 SWISH-E 索引结果。
我们可以通过将每个 PDF 文件转换为磁盘上的相应文件然后索引这些文件来索引 PDF 文件,但相反,我们将利用此机会介绍一种更灵活的索引数据方法:SWISH-E 的程序化访问方法(图 2)。
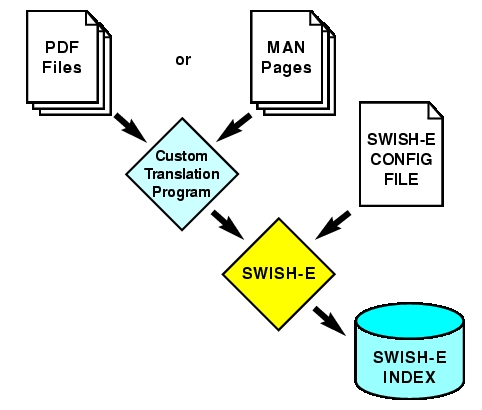
图 2. 使用外部程序和 SWISH-E 索引任意数据
要索引 PDF 文件,首先创建一个 SWISH-E 配置文件,将其称为 howto-pdf.conf 并为其赋予以下内容
# howto-pdf.conf
IndexDir ./howto-pdf-prog.pl
# prog file to hand us XML docs
IndexFile ./howto-pdf.index
# Index to create.
UseStemming yes
MetaNames swishtitle swishdocpath在这里,IndexDir 指令指定了 SWISH-E 所谓的外部程序,该程序将返回有关要索引内容的数据,而不是包含所有文件的目录。UseStemming yes 指令请求 SWISH-E 在索引和搜索之前将单词词干化为其词根形式。如果不进行词干化,则在包含单词“running”的文档上搜索单词“runs”将不匹配。通过词干化,SWISH-E 识别出“runs”和“running”都具有相同的词根或词干词,并找到相关文档。
在我们配置文件中,最后一个但绝对不是最不重要的是 MetaNames 指令。此行向我们的索引添加了一项特殊功能——仅搜索文件的标题或文件名的能力。
现在,让我们编写外部程序以返回有关我们正在索引的 PDF 文件的信息。方便的是,SWISH-E 源代码附带了一个示例模块 pdf2xml.pm,它使用 xpdf 软件包将 PDF 转换为 XML,并在前面加上 SWISH-E 的适当标头。我们在我们的外部程序 howto-pdf-prog.pl 中使用了这个模块,它被复制到 ~/indices。
#!/usr/bin/perl -w
use pdf2xml;
my @files =
`find ../HOWTO-pdfs/ -name '*.pdf' -print`;
for (@files) {
chomp();
my $xml_record_ref = pdf2xml($_);
# this is one XML file with a SWISH-E header
print $$xml_record_ref;
}配备了 SWISH-E 配置文件和上面的外部程序,让我们构建索引
% swish-e -c howto-pdf.conf -S prog
-S prog 选项告诉 SWISH-E 将指定的 IndexDir 视为返回有关要索引数据的信息的程序。如果您在使用带有 SWISH-E 的外部程序时忘记包含 -S prog,您将索引外部程序本身,而不是它描述的文档。
构建 PDF 索引后,我们可以执行搜索
% swish-e -f howto-pdf.index -m 2 -w boot disk
我们应该得到类似于以下的结果
1000 ../HOWTO-pdfs/Bootdisk-HOWTO.pdf
"Bootdisk-HOWTO.pdf" 127194
983 ../HOWTO-pdfs/Large-Disk-HOWTO.pdf
"Large-Disk-HOWTO.pdf" 85280MetaNames 指令还允许我们搜索 PDF 文件的标题和路径
% swish-e -f howto-pdf.index -w swishtitle=apache % swish-e -f howto-pdf.index -w swishdocpath=linux
支持所有相应的搜索组合。例如
% swish-e -f howto-pdf.index -w '(larry and wall)
OR (swishdocpath=linux OR swishtitle=kernel)'上面的引号是必要的,以保护括号免受 shell 的解释。
在我们的最后一个示例中,我们将展示如何制作一个有用且强大的 man pages 索引,以及如何使用 SWISH::API Perl 模块为该索引编写搜索客户端。同样,首先编写配置文件
# sman-index.conf IndexFile ./sman.index # Index to create. IndexDir ./sman-index-prog.pl IndexComments no # don't index text in comments UseStemming yes MetaNames swishtitle desc sec PropertyNames desc sec
我们已经描述了这些指令中的大多数,但我们正在定义一些新的 MetaNames 并引入一些称为 PropertyNames 的东西。
简而言之,MetaNames 是 SWISH-E 实际搜索的内容。默认的 MetaName 是 swishdefault,当查询中未指定 MetaName 时,将搜索该 MetaName。PropertyNames 是可以返回的描述命中的字段。
SWISH-E 结果通常会返回几个自动属性,包括 swishtitle、swishdesc、swishrank 和 swishdocpath。我们配置文件中的 MetaNames 指令指定我们希望能够不仅独立搜索每个完整文档,而且还仅搜索标题、描述或节。PropertyNames 行指定我们希望 sec 和 desc 属性(man page 的节和小描述)与每个命中分开返回。
将 man pages 转换为 XML 并将其包装在 SWISH-E 标头中的工作在清单 1 (sman-index-prog.pl) 中执行。
清单 1. sman-index-prog.pl 将 man pages 转换为 XML 以进行索引。
#!/usr/bin/perl -w
use strict;
use File::Find;
my ($cnt, @files) = (0, get_man_files());
warn scalar @files, " man pages to index...\n";
for my $f (@files) {
warn "processing $cnt\n" unless ++$cnt % 20;
my ($hashref) = parse_man($f);
my $xml = make_xml($hashref);
my $size = length $xml; # NOTE: Fails if UTF
print "Path-Name: $f\n",
"Document-Type: XML*\n",
"Content-Length: $size\n\n", $xml;
}
sub get_man_files { # get english manfiles
my @files;
chomp(my $man_path = $ENV{MANPATH} ||
`manpath` || '/usr/share/man');
find( sub {
my $n = $File::Find::name;
push @files, $n
if -f $n && $n =~ m!man/man.*\.!
}, split /:/, $man_path );
return @files;
}
sub make_xml { # output xml version of hash
my ($metas) = @_; # escapes vals as side-effect
my $xml = join ("\n",
map { "<$_>" . escape($metas->{$_}) .
"</$_>" }
keys %$metas);
my $pre = qq{<?xml version="1.0"?>\n};
return qq{$pre<all>$xml</all>\n};
}
sub escape { # modifies scalar you pass!
return "" unless defined($_[0]);
s/&/&/g, s/</</g, s/>/>/g for $_[0];
return $_[0];
}
sub parse_man { # this is the bulk
my ($file) = @_;
my ($manpage, $cur_content) = ('', '');
my ($cur_section,%h) = qw(NOSECTION);
open FH, "man $file | col -b |"
or die "Failed to run man: $!";
my ($line1, $lineM) = (scalar(<FH>) || "", "");
while ( <FH> ) { # parse manpage into sections
$line1 = $_ if $line1 =~ /^\s*$/;
$manpage .= $lineM = $_ unless /^\s*$/;
if (s/^(\w(\s|\w)+)// || s/^\s*(NAME)/$1/i){
chomp( my $sec = $1 ); # section title
$h{$cur_section} .= $cur_content;
$cur_content = "";
$cur_section = $sec; # new section name
}
$cur_content .= $_ unless /^\s*$/;
}
$h{$cur_section} .= $cur_content;
# examine NAME, HEADer, FOOTer, (and
# maybe the filename too).
close(FH) or die "Failed close on pipe to man";
@h{qw(A_AHEAD A_BFOOT)} = ($line1, $lineM);
my ($mn, $ms, $md) =
("","","","");
# NAME mn, DESCRIPTION md, & SECTION ms
for(sort keys(%h)) { # A_AHEAD & A_BFOOT first
my ($k, $v) = ($_, $h{$_}); # copy key&val
if (/^A_(AHEAD|BFOOT)$/) { #get sec or cmd
# look for the 'section' in ()'s
if ($v =~ /\(([^)]+)\)\s*$/) {$ms||= $1;}
} elsif($k =~ s/^\s*(NOSECTION|NAME)\s*//) {
my $namestr = $v || $k; # 'cmd - a desc'
if ($namestr =~ /(\S.*)\s+--?\s*(.*)/) {
$mn ||= $1 || "";
$md ||= $2 || "";
} else { # that regex could fail.
$md ||= $namestr || $v;
}
}
}
if (!$ms && $file =~ m!/man/man([^/]*)/!) {
$ms = $1; # get sec from path if not found
}
($mn = $file) =~ s!(^.*/)|(\.gz$)!! unless $mn;
my %metas;
@metas{qw(swishtitle sec desc page)} =
($mn, $ms, $md, $manpage);
return ( \%metas ); # return ref to 5-key hash.
}清单 1 中的第一个 for 循环是程序的主循环。它查看每个 man page,根据需要解析它,将其转换为 XML,并将其包装在 SWISH-E 的适当标头中
get_man_file() 使用 File::Find 遍历 man 目录以查找 man page 源文件。
make_xml() 和 escape() 一起从 parse_man() 返回的 hashref 创建 XML。
parse_man() 执行从 man page 源获取相关字段的细致工作。
现在我们已经解释了它,让我们使用它
% swish-e -c sman-index.conf -S prog
完成后,您可以像以前一样测试索引,使用 swish-e 的 -w 选项。
在我们的最后一个示例中,我们讨论一个 Perl 脚本,该脚本使用 SWISH::API 来使用我们刚刚构建的索引,以提供 UNIX 备用 apropos 的改进版本。代码包含在清单 2 (sman) 中。这是一个简要概述:第 1-14 行设置并解析命令行选项,第 15-23 行发出查询并进行粗略的错误处理,第 24-39 行使用通过 SWISH::API 返回的属性呈现搜索结果。
清单 2. sman 是一个用于搜索 man pages 的命令行实用程序。
#!/usr/bin/perl -w
use strict;
use Getopt::Long qw(GetOptions);
use SWISH::API;
my ($max,$rankshow,$fileshow,$cnt) = (20,0,0,0);
my $index = "./sman.index";
GetOptions( "max=i" => \$max,
"index=s" => \$index,
"rank" => \$rankshow,
"file" => \$fileshow,
);
my $query = join(" ", @ARGV);
my $handle = SWISH::API->new($index);
my $results = $handle->Query( $query );
if ( $results->Hits() <= 0 ) {
warn "No Results for '$query'.\n";
}
if ( my $error = $handle->Error( ) ) {
warn "Error: ", $handle->ErrorString(), "\n";
}
while ( ($cnt++ < $max) &&
(my $res = $results->NextResult)) {
printf "%4d ", $res->Property( "swishrank" )
if $rankshow;
my $title = $res->Property( "swishtitle" );
if (my $cmd = $res->Property( "cmd" )) {
$title .= " [$cmd]";
}
printf "%-25s (%s) %-30s", $title,
$res->Property( "sec" ),
$res->Property( "desc" );
printf " %s", $res->Property( "swishdocpath"
)
if $fileshow;
print "\n";
}Perl 客户端就是这么简单。让我们使用我们的客户端在我们的 man pages 上发出搜索,例如
% ./sman -m 1 boot disk
我们应该得到返回
bootparam (7) Introduction to boot time para...
但我们现在也可以进行如下搜索
% ./sman sec=3 perl
将搜索限制在第 3 节。sman 程序还接受命令行选项 --max=# 以指定返回的最大命中数,--file 以显示 man page 的源文件,以及 --rank 以显示给定查询的每个命中的排名
% ./sman --max=1 --file --rank boot
这将返回
1000 lilo.conf (5) configuration file for lilo
/usr/man/man5/lilo.conf.5请注意第一列的排名和最后一列的源文件。
sman 软件包的增强版本将在 joshr.com/src/sman/ 上提供。
我们应该提到 SWISH-E 的两个缺点。首先,它不是多字节安全的——它只处理 8 位 ASCII 数据。其次,记录无法从 SWISH-E 索引中删除——要删除记录,必须重新创建索引。从好的方面来说,SWISH-E 具有许多我们甚至没有提到的功能。有关更多详细信息,请访问 SWISH-E 网站 www.swish-e.org。我们希望您会同意 SWISH-E 是一个令人印象深刻的工具包,并且是您编程工具箱的有用补充。

Josh Rabinowitz 是一位在软件行业工作了 13 年的资深人士,他在 NASA Ames 研究中心以及 CNET.com 和其他网络公司磨练了自己的技能。他目前是一位独立顾问,也是 SkateboardDirectory.com 的出版商,该网站旨在成为您在互联网上查找滑板网站的指南。
