
加速科学进程
作为加利福尼亚州硅谷中心地带的 NASA Ames 研究中心的 штатный 研究人员,我曾是一个团队的成员,该团队使用 Linux 进行一些有趣和高级的研究。我在 Ames 的神经工程实验室工作,支持脑机接口的构建,这是一种可以通过 EEG(脑电图——脑波)信号来控制电子系统和机器人设备的系统。我的工作是从主要实验室研究人员那里获取想法和原型代码,并开发和评估它们的有效实现,以便在人体受试者的实时数据处理中使用。通常,我只会拿到一个粗略的算法草图或一段代码片段,看看它是否可以用于我们一直在收集的脑波数据。
Matlab 和免费软件 GNU Octave 是完成这项工作的出色工具;它们使我能够开发有效的数据处理和数据可视化方法,而这些方法在 C 或,天哪,Fortran 中构建起来将非常痛苦。当处理大量的实验代码时,实现的简易性是一个重要的考虑因素,因为这些代码可能最终成为也可能不会成为成品。
当一个过程确实符合要求,并且开始考虑在我们的实时数据处理系统中使用它时,Matlab 在编程简易性方面的优势立即显现出来,但并非没有代价。代价是速度。例如,处理代表一秒钟的数据可能需要几分钟甚至几小时。显然,这在实时系统中是不可行的。此外,任何被认为有价值的代码都必须最终以 C 或 C++ 编写,才能融入我们现有的代码库。为了解决这两个问题,我们用 C 重写了大部分 Matlab 代码。
现在,如果您有一些 Matlab 经验,您可能会想,“但是 Matlab 已经可以自己导出到 C” 或者,“新的 Matlab JIT 编译器怎么样?” 虽然新的 JIT 编译器可能会在某些地方加速代码(查看文档,它会尝试优化很多例外情况),但它无法匹敌编写良好的编译 C 代码的效率。至于 Matlab 的 C 导出功能,Matlab 导出的代码与在 Matlab 环境中运行的解释代码一样慢,并且在没有一些接口工作的情况下很难合并到现有项目中。而且,这些都无助于 GNU Octave 的用户或那些无法跟上昂贵的 Matlab 升级的用户。总的来说,似乎将最初在 Matlab 中开发的东西转化为快速、生产级别的代码的最佳方法是手工完成。
本文首先提供了一些关于如何编写更高效的 Matlab 代码的技巧。然后,它说明了使用 MEX 函数将 C 代码集成到 Matlab 程序中的过程,以便在 Matlab 环境中进行调整和评估时,加快程序执行速度。从那里,将整个项目引入 C 或 C++ 是相对较短的一步。这里的大部分信息都可以在网上不同的地方找到;本文以 HOWTO 或个人叙述的形式呈现,讲述了如何将一段 Matlab 实验代码带入现实世界。
在本文中,我使用一段代码作为示例,该代码旨在隔离头部表面测量的电压的快速变化。该代码使用一种名为多成分事件相关电位估计的算法,或简称为 mcERP。当我研究该算法时,我首先考虑将 Matlab 代码移植到 C。当使用不同的配置参数和输入数据集测试该算法时,我通常必须让它运行过夜。Matlab 内部的任何优化都无法大幅缩短其执行时间。
在完全转换为 C 后,使用大型输入数据集执行通常需要几十秒的数量级。我认为这是一个极大的时间节省,这归因于算法的高度嵌套、循环的性质(见清单 1)。我不期望大多数算法会加速这么多。即便如此,这种性能仍然不足以满足实时操作,但它已经足够接近,我们可以开始研究数据缩减技术、代码并行化和其他技巧,以将其缩减到更接近我们所需的速度。
Matlab 性能大幅下降的主要领域是循环。Matlab 厌恶循环;它的编写目的是通过向量化代码,在矩阵中的数据范围内应用函数来更有效地执行许多循环类型的操作,而不是迭代数据。不幸的是,这只适用于某些类型的操作。当处理高维矩阵时,这通常会产生难以阅读和理解的代码。循环恰好是 C 擅长的领域——使用指针算术迭代矩阵是一种非常高效,有时也更容易理解的方式来对大数据块执行操作。Matlab 代码的 C 优化的大部分工作都花在尝试优化嵌套循环结构上。
在 Matlab 中更有效率地编写代码的其他方法包括
确保在使用 zeros() 函数分配所有数组(即使是中等大小的数组)后再为数组赋值,而不是让 Matlab 在赋值时将数据附加到现有数组。
正如 Matlab 文档中提到的,将所有代码存储在函数中而不是脚本中。这可以提供大约两到三倍的速度提升。
组织数据,使矩阵范围内的操作以列优先的方式运行。Matlab 像 Fortran 一样存储数组,即特定矩阵列中的数据在内存中是连续的。这与 C 不同,在 C 中,矩阵行中的数据在内存中是连续的。如果您要在一个数据范围内应用函数,请将该数据存储在矩阵的列中而不是沿着行存储。这完全是传闻,可能是错误的,但似乎有道理。
尽量避免重复发生的内部类型转换。这是另一个我没有确凿证据的例子,但由于 Matlab 通常不会让您显式标记变量的数据类型,因此有时很容易出现重复隐式类型转换的循环。最好先转换为通用数据类型,然后再进行重复操作。这就像在 C 或 C++ 中编程,但更难立即检测到,因为变量在 Matlab 中几乎从不显式键入。
说完这些,让我们看一下 mcERP 算法中的一段代码片段(清单 1)。这代表了代码中许多嵌套循环结构之一。mcERP 算法依赖于复杂的迭代贝叶斯波形估计过程。以下许多循环位都在代码中,所有这些循环位都会重复运行,以磨练数据中存在的波形形状。
可以看出,这种结构在使用不擅长循环的解释器时不会运行得很快。但是,由于内部的 if 语句,代码无法向量化,除非添加一个内部函数调用——这不会更好。因此,这段代码是翻译成 C/C++ 的首选。但是,在开发算法时,最好能脚踏 Matlab,因为它很容易生成漂亮的图片,如图 1 所示。因此,我们编写了一种名为 MEX 函数的东西。这样,我们可以让核心的快速位快速运行,同时在 Matlab 中保留那些调整和检查整个算法的接口点。
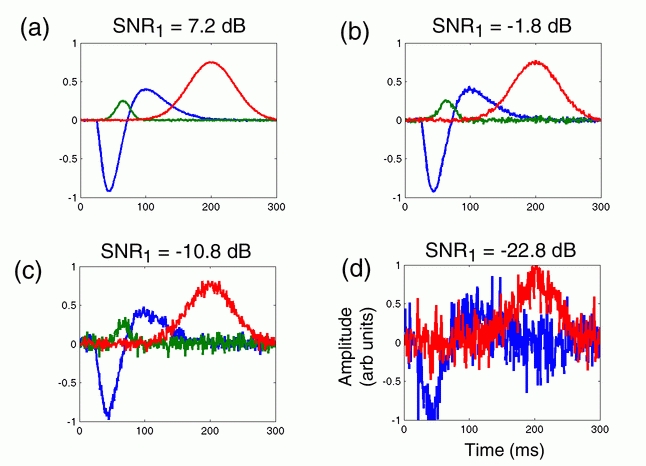
图 1。
图 1 是 mcERP 算法的示例输出,显示了在模拟实验试验期间驱动头皮电极实时电位读数的基波波形的估计值。这些波形形状中的每一个都是经过多次迭代的逐步精确的贝叶斯波形估计的结果,每次迭代都需要多次计算。使用 Matlab 实现这些结果可能需要数小时,但如果算法的某些部分用 C 重写,则只需几秒或几分钟。
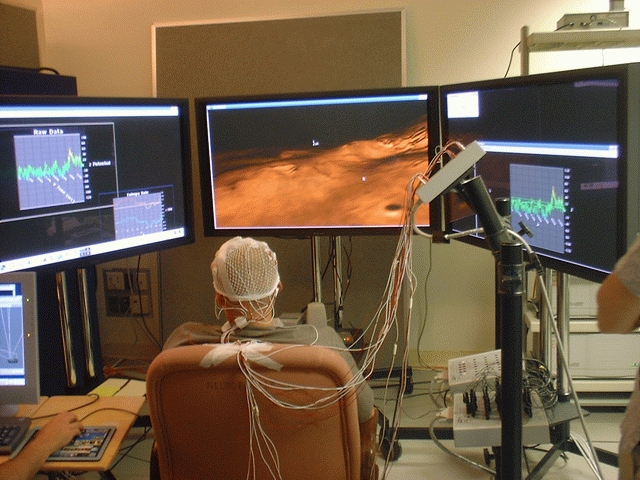
图 2。
图 2 中的照片显示了我们用于进行脑机接口实验的实验设置,具有实时反馈。借助三个大型显示器,我们可以完全控制受试者在其大部分视野范围内看到的内容。所有数字运算和显示软件都是内部开发的,并在 Linux 上运行。
MathWorks 网站上提供了大量文档(请参阅“资源”),如果您认真对待开发 MEX 函数,请在阅读本文后查看它。本文重点介绍优化以及使事情正常运行的一些难点。
要在 Linux 中开发 MEX 函数,请转到所有美好事物的源头,即命令行,并键入 mex -start。当这不起作用时,请在 Matlab 安装目录中搜索 MEX 脚本。您的系统管理员可能只在您的路径中创建了指向 Matlab 二进制文件的链接。运行 MEX 时,您将看到编译器选择。为了利用我稍后将详细介绍的一些编译器优化,最好使用 GCC 而不是 Matlab 内置的 LCC。MEX 将创建文件 ~/.matlab/R12/mexopts.sh,当您使用 MEX 实用程序为 Matlab 编译外部代码时,该文件将被源文件化。查看 mexopts.sh 文件(在适用于您的平台/编译器的部分下)非常有用且具有启发性。在 x86 Linux/GCC 的情况下,请查看主 switch 语句的 glnx86 部分。在此部分之外进行的任何更改在编译代码时都不会产生任何影响。将您希望用来编译 C 函数的任何编译器开关放在那里。为了优化,您可能想要尝试
COPTIMFLAGS='-O3 -funroll-loops -finline-functions'
(这是激进的——请小心) 或您想要的任何标志。要稍后在编译中使用这些标志,您必须使用 -O 选项运行 MEX。与某些 makefile 一样,在此处包含您希望包含的任何头文件目录,方法是附加
-I/path/to/header/directory到 CFLAGS 的末尾。通过添加
-l[libname]和
-L/path/to/library/directory到 LDFLAGS 的末尾,指示您希望链接的库。
完成此操作后,设置一个目录来保存您要使用 MEX 编译的 C 文件。我建议不要在同一目录中处理基于 C 和基于 Matlab 的代码。现在,将该目录或您创建的第三个构建目录添加到 Matlab 环境中的路径中。现在您可以开始考虑编写代码了。
首先也是最重要的是,考虑您的优化目标是什么,以及程序的哪些部分最能从用 C 重写中受益。由于 C 比 Matlab 快得多的主要领域是循环评估,因此在代码中查找对大量数据进行循环的循环是有意义的。为循环三次的东西编写代码是不值得的,但是如果您要迭代 500 × 500 × 500 体积中的每个体素,那么用 C 编写代码可以节省大量时间。尤其要注意嵌套循环中的简单操作,例如清单 1 中的代码片段。任何在嵌套循环中执行复杂操作的操作——任何看起来难以自行实现或找不到第三方库的操作——可能都不是优化的好起点。可以从 C 代码中调用 Matlab 函数,但这无助于您的执行时间,原因显而易见。
现在,创建 C MEX 文件的通用方法是将算法中的代码块函数化,或者选择您已编写要优化的函数。现在,是时候创建函数的 C 版本了。通用过程是创建一个通用的 Matlab 接口函数,然后创建一个表示您正在编写代码的实际过程的 meat 函数。有关 MEX 函数的示例,请参见清单 2。它调用的 meat 函数对应于清单 1 中的 Matlab 文件,并且部分内容可在 Linux Journal FTP 站点上找到 [ftp.linuxjournal.com/pub/lj/listings/issue110/6722.tgz]。
mexFunction() 类似于 MEX 文件编程世界的 main()。它是当您在 Matlab 中调用您的函数时实际调用的函数。函数的实际名称由您编译的 .c 文件的名称定义,通常是您传递给 MEX 进行编译的第一个 .c 文件的名称。在 Linux x86 平台上,MEX 文件的扩展名为 .mexglx。当 Matlab 在 Linux x86 平台上运行时,Matlab 会以与查找普通 .m 文件相同的方式和路径查找 .mexglx 文件,因此 .mexglx 和 .m 文件是可互换的。在 Matlab 和优化代码之间切换的好方法是更改 Matlab 的搜索路径。我将 c_mLAT.c 编译为 c_mLAT.mexglx,然后我可以简单地通过在 Matlab 环境中调用 c_mLAT() 来运行编译后的代码。这是一个非常巧妙的系统。
当尝试在 Matlab 和 C 之间来回传递数据时,事情会变得有点复杂。您会注意到 mexFunction 的参数列表中有两个双指针。*plhs[] 指的是函数的返回值(Matlab 函数可以有多个返回值),*prhs[] 指的是输入参数。输入和返回参数的数量也作为 nlhs 和 nrhs 传递给函数。函数的返回矩阵必须在 mexFuntion() 中使用 mxCreateDoubleMatrix() 等例程分配,以便正确传递回 Matlab 环境。mx 函数在 Matlab 环境中创建内存,并由 Matlab 内存管理器处理,因此无需担心释放 mx 函数创建的内存。
以 mex 开头的函数在 Matlab 环境中调用,并且可以使用 mexCallMATLAB() 从代码中调用任意 Matlab 函数。从 mexFunction(),然后在分配输出、格式化输入并执行参数检查等操作后,调用您的 meat 函数。
然而,Matlab 文档中没有很好地处理 C 程序员相当沮丧的事情,那就是 Matlab 以列优先格式存储其数据。这可能非常烦人,因为您希望能够使用易于理解的指针算术来迭代多维输入矩阵。但是,弄清楚每次迭代要步进多远等等,既令人沮丧又容易出错。在我看来,有三种解决方案。
1) 手动计算出每次迭代需要步进的量,并仔细考虑。这似乎是可行的,并且可能是最佳解决方案,但它会导致维度等于或大于三的数组出现严重的头痛问题。
2) 在进入 MEX 函数之前重新格式化代码,使其以正确的方式组织,以便在 C 中以您想要的方式迭代。这在 Matlab 中可能相当昂贵,而且很多时候您希望有一个原始版本的直接替代品。
3) 像我一样做,创建宏或宏类型项来访问 Matlab 数组中的内存。这比步进遍历数组要慢,并且可能看起来是一个笨拙的解决方案。但在我的经验中,它最终变得易于阅读且速度足够快。例如,我创建了一个名为 pops.h 的文件,其中包含类似
extern inline double num3d(double *start, int rows,
int cols, int x, int y,
int z)
{
return(*(start + rows * cols * z
+ rows * y + x));
}
的函数,该函数返回 3-D Matlab 数组中的值,给定数组、数组的行数和列数以及您要检索的数据的 xyz 位置。它有点笨拙,但还不错。当代码被优化后,它会像预处理器宏一样插入到代码中。也可以同样使用宏,但我发现这种方法更容易创建和调试。最后,在 C 中执行循环的速度提升远远超过了以这种方式进行数组访问造成的相对较小的损失。
除此之外,MEX 文件的创建并不困难。当要编译时,请使用您要编译的 C 文件的名称运行 MEX 程序。MathWorks 网站上也提供了 MEX 选项列表。运行 mex X.c Y.c Z.c 后,您将获得一个名为 X.mexglx 的文件,如果它在您的路径中,您可以在 Matlab 命令行上将其称为 X()。
从这里,您可以重写代码的越来越大的部分,用 C 编写。当要进行完整的 C 实现时,通常最好使用 Matlab 的 C 导出功能导出外部 Matlab 代码,因为重要的部分也已被您优化。如果速度仍然不够快,那么最好重做外部函数以以 C 友好的方式处理内存。然后,您可以加快内部 C 代码中的循环,使用优化的指针迭代来访问数组值。
总的来说,使用 Matlab 进行原型设计和开发代码可以大大加快速度。但是,当您发现自己等待一夜让 Matlab 生成结果,却发现您搞砸了一个小的输入值时,手动优化代码片段的过程对于使您的算法能够实际使用可能非常有益。

Sam Clanton 目前是匹兹堡大学/卡内基梅隆大学的医学博士/博士生,与加利福尼亚州山景城的 NASA 和 QSS 公司 Ames 研究中心保持联系。他将时间花在研究生物信号处理、计算机视觉和医疗机器人方面的问题,并且最感兴趣的是构建像自然界一样的的信息系统。Sam 大部分时间都在查看他的电子邮件(但从不回复)和喝太多咖啡。
