
HA-OSCAR:高可用性 OSCAR 的诞生
开放集群组 (OCG) 和由此产生的开源集群应用程序资源 (OSCAR) 项目的种子,是在 2000 年 2 月 17 日能源部赞助的一次会议上,一些志同道合的人有幸共进晚餐时播下的。晚餐时,这个小组讨论了部署构建 Beowulf 高性能计算集群所需的软件所涉及的工作。尽管该小组一致认为,将商品计算机连接在一起以构建集群很简单,但他们继续一致认为,在 Beowulf 集群上安装和配置必要的软件堆栈所需的工作量异常高。共识的描述是对某些人来说具有挑战性,对所有人来说都很乏味。因此,简化流程的想法应运而生。
这个想法的进一步孕育发生在同年四月在田纳西州橡树岭举行的一次会议上,与会者包括行业、学术界和研究实验室。正是在第一次正式会议上,OCG 成立了,并开始了 OSCAR 的工作,特别是 Beowulf 集群软件堆栈和相关的安装过程。在这次会议上,小组就三项核心原则达成了一致
集群在主流高性能计算中的采用受到缺乏完善且易于普通用户使用的软件堆栈的阻碍。
OCG 拥抱开源模式。因此,OSCAR 发行版必须仅包含可自由再发行的代码,并优先包含在 Berkeley 风格的开源许可证下的源代码。
OCG 可以通过使用当前可用的最佳实践代码来实现其目标。
有关 OCG 和 OSCAR 起始的更多详细信息,请参见 Richard Ferri 在 2002 年 6 月的《Linux Journal》上发表的题为“OSCAR 革命”的文章。
在 OSCAR 短暂的历史中,该小组设法坚持了这三项原则,同时允许 OSCAR 涵盖其他形式的软件。例如,尽管 OSCAR 发行版本身仅包含可自由再发行的代码,但其他人正在部署一个 OSCAR 包,该包虽然不是正式 OSCAR 发行版的一部分,但可以安装或放入现有的 OSCAR 发行版中进行安装。
OSCAR 项目继续包含行业和学术/研究成员。整个项目由每两年从当前核心组织中选出的指导委员会指导。此核心列表由积极为项目开发做出贡献的组织组成。2003 年的核心组织包括:Bald Guy Software (BGS)、戴尔、IBM、英特尔、MSC.Software、印第安纳大学、国家超级计算应用中心 (NCSA)、橡树岭国家实验室 (ORNL) 和舍布鲁克大学 (UdS)。
在过去一年中,创建了额外的 OCG 工作组来解决其他集群环境。这些新小组正在努力在生产集群发行版时利用 OSCAR 提供的技术。今天工作的两个小组是 Thin-OSCAR 和 HA-OSCAR。Thin-OSCAR 由加拿大舍布鲁克大学领导,致力于交付 OSCAR 的无盘变体。HA-OSCAR 小组由本文作者领导,专注于提供高可用性版本的 OSCAR。
在 2001 年 7 月于加拿大爱立信研究中心举行的一次会议上,Ibrahim Haddad 提出了集群计算中高可用性的必要性。最初,讨论的中心是电信行业对高可用性计算的需求。随着讨论的深入,人们清楚地认识到,随着高性能计算 (HPC) 集群中预计将出现数万个节点,高可用性技术可以为 HPC 社区提供一定程度的容错能力。
在路易斯安那理工大学的 Chokchai Leangsuksun 博士及其团队以及 ORNL 的 Stephen Scott 对 HA-OSCAR 的持续关注加入之前,Ibrahim 在爱立信研究中心的小组主要独自致力于高可用性工作。2002 年,HA-OSCAR 工作被 OCG 正式认可为另一个工作组。该小组的主要目标是利用现有的 OSCAR 技术,并在 OSCAR 集群中提供新的高可用性功能。这项技术的预期客户包括电信行业和 HPC 站点。
HA-OSCAR 为 OSCAR 引入了几项增强功能和新特性,主要是在可用性、可扩展性和安全性方面。这些特性中的大多数可以映射到 ITU(国际电信联盟)、TMN(电信管理网络)和 FCAPS(故障管理、配置、计费、性能和安全)。这些概念在电信行业中被广泛采用,用于管理其网络元素。
典型的集群计算架构由多个节点组成,这些节点可以提供一定程度的可用性。但是,它通常有一个单头节点,这是一个单工架构,容易出现单点故障。当前版本的 OSCAR 属于这种架构类别,它不适用于任务关键型系统,因为它包含多个独立的系统元素,这些元素没有备份或故障转移的冗余。为了支持 HA 要求,集群系统必须提供消除单点故障的方法。
硬件复制和网络冗余是用于提高计算机系统可靠性和可用性的常用技术。为了构建 HA-OSCAR 集群系统,我们首先必须提供集群头节点的复制。这种架构可以以不同的方式实现,包括主动-主动、主动-热备用和主动-冷备用。
主动-主动模型既能实现性能又能实现可用性,因为两个头节点都可以同时提供服务。但是,它的实现非常复杂,并且在发生故障时会导致数据不一致。主动-备用选项是主要采用的解决方案。备用服务器监视主服务器的健康状况,并在检测到中断时可以接管控制。目前,主动-热备用配置是最初的选择模型。
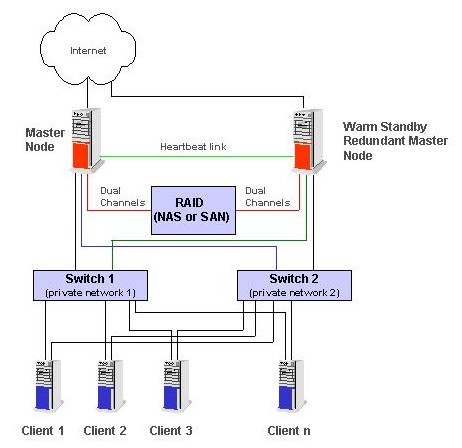
图 1. HA-OSCAR 集群系统架构
图 1 显示了 HA-OSCAR 集群系统架构。我们试验并计划将 Linux Virtual Server 和 Heartbeat 机制整合到我们最初的主动-热备用 HA-OSCAR 发行版中。现在,我们计划在发布热备用发行版后扩展我们最初的架构以支持主动-主动 HA。主动-主动架构可以更好地利用资源,因为两个头节点可以同时处于活动状态以提供服务。然后,双主节点可以运行冗余的 DHCP、NTP、TFTP、NFS 和 SNMP 服务器。在头节点中断的情况下,该节点提供的所有功能都故障转移到第二个冗余头节点,并以降低的性能速率(理论上,在高峰或繁忙时段为 50%)提供服务。
HA-OSCAR 中要支持的另一个 HA 功能是使用每台机器上的冗余以太网端口提供高可用性网络。此外,整个网络配置都使用了重复的交换矩阵(网络交换机、电缆等)。这使得集群中的每个节点都可以在其网络中的两条或更多条数据路径上存在。在以太网冗余的支持下,集群实现了更高的网络可用性。此外,当两个网络都启动时,可以通过使用跨冗余通信路径的消息通道绑定等技术来提高通信性能。
HA-OSCAR 旨在重用其他实现和现有项目的功能,包括 High-Availability Linux、Kimberlite 和 Linux Virtual Server 项目。然后,我们计划将添加的增强功能和功能贡献回社区。
IPv6 是 IETF 设计的下一代协议,用于取代当前版本的 Internet 协议 IPv4。当今的大多数互联网使用 IPv4,尽管 IPv4 已经过时,但它仍然具有出色的弹性,但它开始出现问题。最重要的是,IPv4 地址日益短缺,所有连接到 Internet 的新设备都需要 IPv4 地址。因此,IETF 定义了 IPv6 来解决 IPv4 中的问题,并为未来的 Internet 添加了许多改进。这些改进涉及不同的领域,例如路由、自动配置、安全性、QoS 和移动性。
HA-OSCAR 默认激活了对 IPv6 的支持。大多数 ISP 和电信公司已经在试验 IPv4 和 IPv6 的共存方案。使用 HA-OSCAR 安装的所有集群节点都提供对 IPv6 的支持,并且基本 IPv6 功能直接编译到网络实用程序和二进制文件中。
OSCAR 假设安装它的客户端节点磁盘是完好的。但是,情况并非总是如此;某些节点可能具有损坏的磁盘。HA-OSCAR 考虑了这个问题,并且不假设所有节点上的所有磁盘都是良好的安装基础。为此,我们支持安装中的特殊脚本和内核中的软件 RAID,同时并行开发同步磁盘内容所需的必要脚本集。这样,如果磁盘发生故障,数据也不会丢失。此外,我们的安装向导首先尝试修复损坏的磁盘。HA-OSCAR 还支持同步操作、磁盘移除和磁盘插入。此外,HA-OSCAR 默认支持软件 RAID。通过启用软件 RAID,由 HA-OSCAR 驱动的集群具有更高的数据冗余和更好的性能。
我们已经描述了 HA-OSCAR 硬件架构。一个关键的增强功能是添加了双头节点,它为故障转移提供了一个备份头节点,以防主头节点发生故障。但是,除非结合了检测和恢复机制,否则仅硬件冗余解决方案不足以实现 HA。
很少有现有解决方案提供故障检测和故障转移。我们已经评估并选择了故障转移 LVS。该解决方案包括 LVS、Linux Director Dæmon (ldirectord)、Heartbeat 和 Coda。Linux Virtual Server 是一种软件工具,可将网络连接定向到共享工作负载的多个服务器。ldirectord 是一个独立的守护程序,用于监视服务。Heartbeat 通过串行线路和 UDP 连接提供主节点故障检测和故障转移机制。Coda 是一个容错分布式文件系统。该解决方案不仅提供 HA 功能,还提供负载均衡。但是,必须在 HA-OSCAR 中增强其他 LVS 服务,包括 SIP、PBS 和 Web 服务。还添加了到故障管理系统的外部 Heartbeat (eHB) 机制。eHB 是一种预防措施,以防发生完全中断(例如,双头节点故障),故障管理系统会检测到该中断,发出警报并向系统管理员发送页面。
OSCAR 当前安装在主要部署在专用网络上的集群上,在这些网络上,安全不是主要问题。那是因为这些集群没有连接到实验室边界之外的任何网络。但是,当 HA-OSCAR 部署在连接到 Internet 的集群上时,安全至关重要。安全不仅是 OSCAR 和 HA-OSCAR 的主要关注点,因为黑客可能会访问集群及其上的数据,而且还因为恶意黑客也可能破坏系统的正常运行及其可用性。
存在许多安全解决方案,从外部解决方案(防火墙)到内部解决方案(完整性检查软件)。不幸的是,所有这些解决方案都基于单节点方法,并且缺乏对集群的同构视图。大多数时候,管理员最终会安装、修补、集成和管理多个安全解决方案。随着异构组件的更新,互操作性问题增加,管理难度增加很快导致安全性降低。
因此,启动了分布式安全基础设施 (DSI) 作为一个开源项目,旨在为运营商级集群服务器提供适当的安全解决方案。DSI 是一个安全框架,它为在集群系统上运行的应用程序提供分布式机制,用于访问控制、身份验证、通信的机密性和完整性。它还提供具有进程级粒度的审计服务。
因此,如果 HA-OSCAR 支持高级安全功能,它可以在电信和其他任务关键型领域取得更大的成功。出于这个原因,HA-OSCAR 采用了爱立信的 DSI。
HA-OSCAR 支持一种机制,允许用户以透明的方式动态地从集群中添加和删除节点,而不会影响最终用户体验或正在运行的应用程序。两个开源项目提供了类似的功能:Eddie,一个爱立信开源倡议,以及 LVS。我们目前正在研究最佳机制,并将在 HA-OSCAR 中实现它。我们的目标是确保添加节点以适应更高的流量或删除节点以用于服务目的是无缝操作,并且不会影响服务可用性。
关于采用哪个内核的主题是在决定是否自己修补 HA-OSCAR 内核,还是尝试让我们的补丁被主流内核树接受之外提出的。我们决定使用最新的稳定 2.4 内核,并将我们创建的补丁提交到内核邮件列表。我们正在尝试为这些 HA-OSCAR 用户提供一个简化的内核构建工具。用户可以根据其本地配置重新编译。
网络/分布式文件系统是构建集群的基本组件。许多开源项目旨在为 Linux 集群提供网络文件系统。根据我们之前的研究和实验室测试,我们确定可能需要不同的网络文件系统,具体取决于集群上运行的应用程序类型。例如,对于流视频和音频服务器上的大文件,使用并行虚拟文件系统 (PVFS) 具有高 I/O 性能的优势。另一方面,可以使用 NFS 在集群节点之间共享配置文件,而无需高 I/O。如果希望保持高可用性并支持存储区域网络 (SAN),则具有日志功能的 OpenGFS 可以处理此类任务。因此,HA-OSCAR 正在努力支持所有可能在目标环境中使用的网络文件系统。
需要考虑的一个重要因素是构建、启动和使集群准备好为请求提供服务所需的时间。对于小型集群来说,这不是一个主要问题,但是当我们转向 256 个节点及以上的大型安装时,拥有以自动化和及时的方式安装和启动所有集群节点的能力就成为一种资产。HA-OSCAR 正在考虑通过将集群划分为多个区域来实现分层集群。这种类型的实验也有助于识别系统安装过程中速度较慢的进程,从而使我们能够加快速度。例如,LinuxBIOS 可以包含在代替普通 BIOS 的位置 - 只需进行少量硬件初始化和一个可以从冷启动启动的压缩 Linux 内核 - 即可实现更快的启动时间。即将发布的 OSCAR 版本使用了组播技术,该技术已在约 500 个节点上进行了测试,以加快安装时间并返回令人印象深刻的数字。HA-OSCAR 计划采用这种方法作为基本安装机制并加以改进。
与基本 OSCAR 安装类似,HA-OSCAR 的用户可以自由决定要安装哪些应用程序包。默认情况下,HA-OSCAR 会自动安装构建集群的基本部分,然后提示用户选择他们想要的应用程序。
安装过程会考虑任何现有配置以及节点上已安装的软件包。某些软件包对某些系统库很敏感,例如 glibc。用户应该意识到,安装 HA-OSCAR 可能需要他们根据此类依赖项升级其系统。以同样的方式,提供了卸载程序来清理每个 HA-OSCAR 特定的添加,而不会干扰系统完整性。对于只想测试 HA-OSCAR 的用户来说,此选项非常重要。
还值得一提的是,自 v2.0 以来,基本 OSCAR 版本中提供了软件包安装和卸载选项,并且即将推出新的增强版本。
HA-OSCAR 计划研究在不关闭系统的情况下提供选择性网络软件升级机制的可能性。网络升级是修补操作系统及其应用程序的一种有趣方式。例如,大多数 Linux 发行版现在都带有自动网络升级,这简化了这种繁琐的管理任务。对于管理大型集群的情况,HA-OSCAR 用户可以使用此功能无缝升级其应用程序版本,而不会中断服务。网络升级简化了集群管理,并促进了所有计算节点上的更好软件管理。
此外,HA-OSCAR 提供了一个工具,允许用户通过使用类似于 LinuxConf 的工具在运行时更改集群的配置。这仍然是一个基本的想法,将在不久的将来进一步研究。
通常,如果没有备份或恢复机制,就无法信任计算系统。对于任务关键型应用程序,包括电信应用程序,能够从任何软件或硬件故障中恢复非常重要。因此,提供有效的备份和恢复机制是任何 HA 系统的基本组成部分。
在发生灾难的情况下,恢复能力和速度至关重要。每次 HA-OSCAR 完全重新安装或内核更新时,之前和之后的 Ghost 镜像都会保存在备份服务器和磁带上的指定位置。Ghost for Unix 会拍摄旧内核和新内核的快照,对其进行 gzip 压缩,并将镜像发送到辅助头节点以及预定义的灾难恢复站点。重要数据以及应用程序和配置文件也可以包含在 Ghost 镜像中。通常,磁带备份计划包括用于增量镜像的每晚快照和用于完整镜像的每周快照。为了实现更快的恢复和高度可靠的备份,实施了 Ghost 镜像、文件日志和数据复制。
HA-OSCAR 的一个目标是可选地部署为 Web 服务器集群,为大量客户端提供高可用性的 Web 服务。实现此目标的一个步骤是在每个节点上设置 Web 服务器(例如 Apache);Apache 可以是要复制到节点的软件包之一。然后,为集群提供单个 IP 接口,可能使用 LVS 直接路由,因为它已被证明是可扩展的实现。
电信应用程序的构建必须能够应对极端或计划外的执行条件。即使在典型的现实生活中,由于用户对系统性能和可用性的高期望,用户也给运营商带来了很大的压力。客户不希望这些应用程序出现故障,也不希望他们的电话请求延迟超出典型阈值。随着电信应用程序提供额外的服务,其中一些服务需要实时特性,这种情况越来越真实。
运营商级应用程序的设计必须考虑到这些用户的约束,同时考虑到软件维护和升级的成本、服务可用性和可扩展性。复杂的分布式软件需要特定的编程范例。多年来的事实证明,复杂的系统接口往往会增加调试时间和应用程序故障的可能性。
AEM(异步事件机制)提供了一种事件驱动的开发方法,以便通过允许通过用户空间回调快速响应系统事件的机制来提供强大的应用程序。在 AEM 实现中,内核在处理事件方面起着重要作用,并提高了应用程序的可靠性。因此,AEM 为应用程序设计人员提供了一个灵活的解决方案,提供了一个可扩展的框架,允许在运行时添加新功能,而无需重新启动系统或重新启动应用程序。为了达到运营商级要求,HA-OSCAR 计划为异步事件提供有效的支持。
资源
AEM: www.linux.ericsson.ca/aem
CODA: www.coda.cs.cmu.edu
DSI: www.linux.ericsson.ca/dsi
Eddie: eddie.sourceforge.net
FCAPS: www.iec.org/online/tutorials/ems/topic03.html
g4u: www.feyrer.de/g4u
GPL: www.gnu.org/copyleft/gpl.html
Linux HA: linux-ha.org
LVS: www.linuxvirtualserver.org
Open System Lab: www.linux.ericsson.ca
OSCAR: www.OpenClusterGroup.org/OSCAR
OSCAR 革命: /article/5559
Ibrahim Haddad (Ibrahim.Haddad@Ericsson.com) 是爱立信研究企业部门开放系统实验室的研究员。他是 McGraw-Hill 出版的 Red Hat Linux 袖珍管理员 的合著者,该书将于 2003 年 9 月出版。
Chokchai Leangsuksun (box@latech.edu) 是路易斯安那理工大学创业与信息技术中心 (CEnIT) 的计算机科学副教授。在他的学术生涯之前,他在朗讯科技公司从事系统可靠性和高可用性计算以及电信系统的研发工作七年。
Stephen L. Scott (scottsl@ornl.gov) 是美国橡树岭国家实验室计算机科学与数学部的资深研究科学家。他是 OCG 的创始成员,目前是版本 2 发布经理。此前,他曾担任 OSCAR 项目的工作组主席。
