
Kernel Korner - 在 Linux 2.5 内核中使用 RCU
Linux 黑客的工具箱中已经包含了许多对称多处理器 (SMP) 工具,那么为什么还要费心使用读-复制更新 (RCU) 呢?图 1 回答了这个问题,展示了在一个四 CPU、700MHz Pentium III 系统上使用每桶锁的哈希查找性能。您的结果会因不同的工作负载和不同的硬件而有所不同。有关其他 SMP 技术使用的出色撰写,请参阅 Robert Love 在 2002 年 8 月刊的 Linux Journal 上的文章 [可在 /article/5833 中找到]。

图 1. 哈希查找性能随着 CPU 数量的增加而扩展性差。
所有访问都是只读的,因此人们可能会期望 rwlock 与此系统的工作效果一样好。然而,人们可能会误判;rwlock 实际上从一个 CPU 到两个 CPU 的扩展性是负面的,部分原因是这种 rwlock 变体避免了饥饿,因此产生了更大的开销。rwlock 需要更大的临界区才能有所帮助。虽然对于少量 CPU 来说,rwlock 优于 refcnt(自旋锁和引用计数器),但即使在四个 CPU 的情况下,refcnt 也优于 rwlock。在这两种情况下,扩展性都非常糟糕;refcnt 在四个 CPU 上仅达到理想四 CPU 性能的 54%,而 rwlock 仅达到 39%。
简单的自旋锁比 rwlock 或 refcnt 产生的开销更少,并且在 57% 时扩展性也稍好一些。但这种扩展性仍然很差。虽然由于 CPU 尝试访问相同的哈希链而发生了一些自旋,但这种自旋仅占四个 CPU 上 43% 性能下降的不到四分之一。
只有 brlock 线性扩展。然而,brlock 的单 CPU 性能低于标准,使用简单的整数比较搜索单元素哈希链需要超过 300 纳秒。这个过程不应该花费超过 100 纳秒的时间才能完成。
图 2 说明了过去四分之一个世纪硬件性能的进步。然而,使新一代(小屁孩)如此自豪的功能在 SMP 系统中是双刃剑。

图 2. 新的、快速的“小屁孩”处理器改变了操作系统设计规则。
不幸的是,许多算法未能利用小屁孩的优势,因为它们是在老家伙正值壮年时开发的。除非你喜欢缓慢而庄严的计算,否则你需要与小屁孩合作。
CPU 时钟频率的增加令人震惊——老家伙可能能够干扰 AM 无线电信号,而年轻的小屁孩可能能够以数字方式合成它们。但是内存速度的增长速度远不及 CPU 时钟频率,因此一次 DRAM 访问可能会花费小屁孩多达一千条指令。虽然小屁孩使用大型缓存来补偿 DRAM 延迟,但这些缓存无法帮助在 CPU 之间弹跳的数据。例如,当给定的 CPU 获取锁时,该锁有 75% 的几率位于另一个 CPU 的缓存中。获取锁的 CPU 会停顿,直到锁到达其缓存。
缓存行弹跳解释了图 1 中大部分的扩展性不足,但它并不能解释单 CPU 性能差的原因。当只有一个 CPU 时,不存在其他缓存可以隐藏锁。这就是小屁孩的 20 级流水线显示其阴暗面的地方。SMP 代码必须确保没有临界区的指令或内存操作泄漏到周围的代码中。毕竟,锁的全部意义在于防止多个 CPU 并发执行任何临界区的操作。
内存屏障防止这种泄漏。这些内存屏障隐式地包含在 x86 CPU 上的原子指令中,但在大多数其他 CPU 上,它们是单独的指令。在任何一种情况下,锁定原语都必须包含内存屏障。但是这些屏障会导致流水线刷新和停顿,其开销随着流水线长度的增加而增加。这种开销是造成图 1 所示单 CPU 速度慢的原因。
表 1 概述了 700MHz Intel Pentium III 机器上基本操作的成本,该机器每个时钟周期可以完成两条整数指令。原子操作时序假设数据已经驻留在 CPU 的缓存中。所有这些时序都可能因缓存状态、总线负载和确切的操作顺序而异。
表 1. 700MHz Pentium III 上常用操作所需的时间
| 操作 | 成本 (纳秒) |
|---|---|
| 指令 | 0.7 |
| 时钟周期 | 1.4 |
| L2 缓存命中 | 12.9 |
| 原子递增 | 58.2 |
| cmpxchg 原子递增 | 107.3 |
| 主内存 | 162.4 |
| CPU 本地锁 | 163.7 |
| 缓存传输 | 170.4–360.9 |
开销相对于指令执行开销增加。例如,在 1.8GHz Pentium 4 上,原子递增的成本约为 75 纳秒——比 700MHz Pentium III 慢,尽管它的时钟速度快两倍以上。
这些开销也解释了 rwlock 性能差的原因。读端临界区必须包含数百条指令才能继续执行,一旦其他 CPU 读取获取锁,如图 3 所示。在此图中,垂直箭头表示两对 CPU 上时间流逝,一对使用 rwlock,另一对使用自旋锁。对角箭头表示 CPU 缓存之间的数据移动。rwlock 临界区根本不重叠;将锁从一个 CPU 移动到另一个 CPU 的开销与临界区的开销相当。
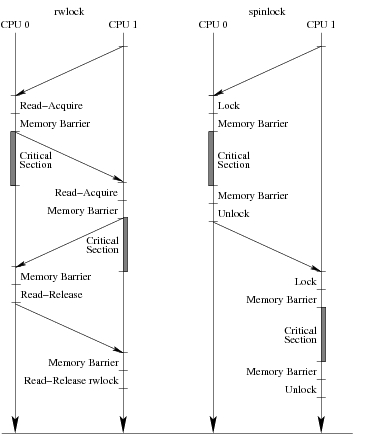
图 3. 双 CPU 系统上 rwlock 和自旋锁的时间线
如果您关心性能,您需要避免这些昂贵的操作。避免这些操作正是 RCU 所做的,至少对于对读取为主的数据结构的只读访问是这样,尽管 DEC Alpha 仍然需要一些读端内存屏障。如图 4 所示,对于哈希表搜索基准测试程序,RCU 扩展性良好且具有良好的单 CPU 性能。

图 4. RCU 读取性能(按处理器数量)
当然,更新会减慢 RCU 的速度,如图 5 所示。此图说明了当工作负载从只读(左侧)变为只写(右侧)时,这些同步原语的相对性能。RCU 在各个方面都优于 brlock。事实上,由于 OSDL 的 Steve Hemminger 和许多 Linux 网络杰出人物的努力,RCU 已经取代了 2.5 内核中的 brlock。只要更新访问少于约三分之一,RCU 总体而言是最佳选择。同样,您的结果会因您的工作负载和硬件而异。特别是,每个元素本地处理量更大的工作负载(例如,更复杂的比较)将具有更好的扩展性。一如既往,为工作选择合适的工具。

图 5. RCU 性能(按更新访问的比例)
如果读取 CPU 从不表明它们的存在,那么更新 CPU 如何避免弄乱读取器?使用锁,更新 CPU 检查锁状态以确定何时执行更新是安全的。使用 RCU,更新 CPU 必须间接地进行此确定。
诀窍是 RCU 读取 CPU 在遍历数据结构时不允许阻塞,这与持有自旋锁或 rwlock 的 CPU 不允许阻塞相同。这意味着一旦元素从列表中取消链接,任何随后执行上下文切换的 CPU 都不可能获得对该元素的引用。上下文切换是静止状态:正在进行上下文切换的 CPU 不能持有对 RCU 保护的数据结构的引用。所有 CPU 通过静止状态的任何时间段都是宽限期。因此,CPU 可以在从列表中取消链接元素的时间起经过宽限期后释放元素。
因此,一个简单但效率低下的基于 RCU 的删除算法可以在非抢占式 Linux 内核中执行以下步骤
从列表中取消链接元素 B,但不释放它——列表的状态如图 6 的步骤 2 所示。
依次在每个 CPU 上运行。此时,每个 CPU 在元素 B 取消链接后都执行了一次上下文切换。因此,不可能再有对元素 B 的引用,如图 3 所示(图 6)。
释放元素 B,如图 4 所示(图 6)。

图 6. 基于 RCU 的简单删除算法的步骤
Andrea Arcangeli 创建了一种更高效的算法,该算法拥有极短的宽限期,这是第一个发布的 Linux RCU 实现。Dipankar Sarma 编写了一个效率更高的 RCU 实现,该实现保持回调缓存局部性,并允许宽限期为任意数量的并发更新提供服务。Dipankar 的算法包含在 2.5 内核中,并在 2002 年的渥太华 Linux 研讨会上进行了详细描述。
清单 1 显示了 RCU 的外部 API。synchronize_kernel() 函数会阻塞一个完整的宽限期。这是一个易于使用的函数,但它会产生昂贵的上下文切换开销。它也不能在持有锁或从中断上下文中调用。但是,它确实允许并发调用者共享一个宽限期。
清单 1. RCU API
void synchronize_kernel(void);
void call_rcu(struct rcu_head *head,
void (*func)(void *arg),
void *arg);
struct rcu_head {
struct list_head list;
void (*func)(void *obj);
void *arg;
};
void rcu_read_lock(void);
void rcu_read_unlock(void);
相比之下,call_rcu() 在一个完整的宽限期后调度回调函数 func(arg)。由于 call_rcu() 永远不会休眠,因此可以在持有锁和从中断上下文中调用它。call_rcu() 函数使用其 struct rcu_head 参数来记住其回调函数和宽限期期间的参数。rcu_head 通常放置在受 RCU 保护的结构中,从而消除了单独分配它的需要。
原语 rcu_read_lock() 和 rcu_read_unlock() 标记了读端 RCU 临界区,但在非抢占式内核中不生成任何代码。在抢占式内核中,它们禁用抢占,从而防止抢占过早结束宽限期。类似于 RCU 的机制也可以在不抑制抢占的抢占式内核中使用,正如 K42 研究操作系统所证明的那样。
大多数现代微处理器都具有弱内存一致性模型,这需要特殊的内存屏障指令。然而,这些指令难以理解,甚至更难测试,因此 Linux 列表操作 API 进行了扩展以包含内存屏障,正如 Manfred Spraul 所建议并在清单 2 中所示。hlist 原语最近由 Andi Kleen 添加,以便减少大型哈希表的内存需求。
清单 2. Linux 列表操作 API 的 RCU 扩展
list_add_rcu(struct list_head *new,
struct list_head *head);
list_add_rcu_tail(struct list_head *new,
struct list_head *head);
list_del_rcu(struct list_head *entry);
list_for_each_rcu(struct list_head *pos,
struct list_head *head);
list_for_each_safe_rcu(struct list_head *pos,
struct list_head *n,
struct list_head *head);
list_for_each_entry_rcu(struct list_head *pos,
struct list_head *n,
struct list_head *head);
list_for_each_continue_rcu(struct list_head *pos,
struct list_head *head);
hlist_del_rcu(struct hlist_node *n);
void hlist_del_init(struct hlist_node *n);
hlist_add_head_rcu(struct hlist_node *n,
struct hlist_head *h);
当 RCU 应用于列表以外的数据结构时,必须显式指定内存屏障指令。有关示例,请参阅 Mingming Cao 对 System V IPC 的基于 RCU 的修改。
虽然 RCU 已在许多有趣和令人惊讶的方式中使用,但最直接的用途之一是替代读者-写者锁定。事实上,RCU 可以被认为是进程中的下一步。rwlock 原语允许读取器彼此并行运行,但不允许与更新器并行运行。另一方面,RCU 允许读取器彼此并行运行,也允许与更新器并行运行。
本节介绍了 rwlock 和 RCU 之间的类比,使用读者-写者锁然后使用 RCU 保护清单 3 中所示的简单双向链表数据结构。此结构具有 struct list_head、搜索键、单个整数用于数据和 struct rcu_head。
清单 3. 受 RCU 保护的数据结构
struct el {
struct list_head list;
long key;
long data;
struct rcu_head my_rcu_head;
};
读者-写者锁/RCU 类比替换了表 2 中所示的原语。带星号的原语在非抢占式内核中是空操作;在抢占式内核中,它们抑制抢占,这在本地任务结构上是一个非常廉价的操作。由于 rcu_read_lock() 不会阻塞中断上下文,因此有必要在需要的地方为此目的添加原语。例如,read_lock_irqsave 必须变为 rcu_read_lock(),后跟 local_irq_save()。
表 2. 读者-写者锁和 RCU 原语
| 读者-写者锁 | 读-复制更新 |
|---|---|
| rwlock_t | spinlock_t |
| read_lock() | rcu_read_lock() * |
| read_unlock() | rcu_read_unlock() * |
| write_lock() | spin_lock() |
| write_unlock() | spin_unlock() |
| list_add() | list_add_rcu() |
| list_add_tail() | list_add_tail_rcu() |
| list_del() | list_del_rcu() |
| list_for_each() | list_for_each_rcu() |
表 3 说明了某些简单链表操作的这种转换。请注意,rwlock delete() 函数的第 10 行被 call_rcu() 替换,该 call_rcu() 将 my_free() 的调用延迟到宽限期结束。其余函数以直接的方式进行转换,如表 2 所示。
虽然这种类比可能非常引人注目和有用——例如,在 Dipankar Sarma 和 Maneesh Soni 在 dcache 中使用 RCU 的情况下——但有一些注意事项
读端临界区可能会看到已从列表中删除但尚未释放的陈旧数据。在某些情况下,这不是问题,例如尽力而为协议的路由表。在其他情况下,可以检测并忽略此类陈旧数据,就像 2.5 内核的 System V IPC 实现中发生的情况一样。
读端临界区可以与写端临界区并发运行。
宽限期会延迟内存的释放,这意味着与使用读者-写者锁相比,使用 RCU 时内存占用量会稍微大一些。
当更改为 RCU 时,就地修改列表元素的写端读者-写者锁定代码通常必须进行重组,以防止读端 RCU 代码看到数据处于不一致的状态。在许多情况下,这种重组非常简单;例如,您可以创建一个具有所需状态的新列表元素,然后用新元素替换旧元素。
在适用的情况下,这种类比可以提供完全的并行性,而几乎不会增加复杂性。
如上所示,使用 RCU 对现有代码进行改造可以产生显着的性能提升。当然,最好的结果是通过从一开始就将 RCU 设计到算法和代码中来获得的。
i386 oprofile 代码包含了一个设计的 RCU 的优秀示例。此代码可以使用 NMI(不可屏蔽中断)来处理独立于正常时钟中断的分析,这允许分析时钟中断处理程序。传统上,与 NMI 同步一直很困难;根据定义,不存在阻止 NMI 的方法。因此,直接的锁定设计容易出现死锁,其中持有锁的 CPU 接收到 NMI,并且 NMI 处理程序永远在此同一锁上自旋。另一种方法是使用 spin_trylock() 之类的东西在软件中屏蔽 NMI。然而,此方法会产生缓存弹跳和内存屏障开销,并且屏蔽的 NMI 会丢失。nmi_timer_int.c 中的解决方案如清单 4 所示。
清单 4. 在 nmi_timer_int.c 中使用 RCU
static void timer_stop(void)
{
enable_timer_nmi_watchdog();
unset_nmi_callback();
synchronize_kernel();
}
static struct oprofile_operations nmi_timer_ops = {
.start = timer_start,
.stop = timer_stop,
.cpu_type = "timer"
};
synchronize_kernel() 确保在 timer_stop() 返回之前,任何在进入 timer_stop() 时执行旧 NMI 回调的 NMI 处理程序都已完成。清单 5 中显示的 oprofile_stop() 和 oprofile_shutdown() 的代码说明了为什么这很重要。请注意,oprofile_ops->stop() 调用 timer_stop()。因此,如果在快速连续地调用 oprofile_stop() 和 oprofile_shutdown(),则正在进行的 NMI 可能会访问新释放的 CPU 缓冲区。此操作可能会使快速重新分配此内存的任何代码感到意外。
清单 5. 来自 nmi_timer_int.c 的更多代码
void oprofile_stop(void)
{
down(&start_sem);
if (!oprofile_started)
goto out;
oprofile_ops->stop();
oprofile_started = 0;
/* wake up the daemon to read remainder */
wake_up_buffer_waiter();
out:
up(&start_sem);
}
void oprofile_shutdown(void)
{
down(&start_sem);
sync_stop();
if (oprofile_ops->shutdown)
oprofile_ops->shutdown();
is_setup = 0;
free_event_buffer();
free_cpu_buffers();
up(&start_sem);
}
RCU 的使用自然地消除了这种竞争,而不会产生任何锁定或内存屏障开销。
使用 RCU 不是一件要么全有要么全无的事情。它可以根据需要增量地应用于特定的代码路径。Dipankar Sarma 编写的一个补丁就是一个很好的例子,该补丁阻止 ls /proc 阻塞 fork()。更改如下:
get_pid_list() 中 tasklist_lock 的 read_lock() 和 read_unlock() 分别被 rcu_read_lock() 和 rcu_read_unlock() 替换。
struct rcu_head 被添加到 task_struct 中,以便跟踪等待宽限期到期的任务结构。
put_task_struct() 宏通过 call_rcu() 而不是直接调用 __put_task_struct()。这确保了所有并发执行的 get_pid_list() 调用在它们可能引用的任何任务结构被释放之前完成。
SET_LINKS() 和 REMOVE_LINKS() 宏使用列表操作原语的 _rcu 形式。
for_each_process() 宏获得了一个 read_barrier_depends(),以使此代码对于 DEC Alpha 安全。
问题是 get_pid_list() 遍历整个任务列表,以便构建 ls /proc 所需的 PID 列表。它在此遍历期间读取持有 tasklist_lock,并阻止对任务列表的更新,例如 fork() 执行的更新。在具有大量任务的机器上,这可能会导致严重的困难,特别是考虑到某些性能监视工具的多个实例。
表 4 显示了 Dipankar 的修改,仅更改了两个文件,添加了 13 行,删除了 7 行,内核净增加了 6 行。此补丁确实删除了 tasklist_lock 的一对用途,但 tasklist_lock 的其他 249 个用途均未修改。此示例演示了 RCU 用于周期后期的优化。
Paul E. McKenney 从事 SMP 和 NUMA 算法的工作时间比他愿意承认的还要长。在此之前,他从事分组无线电和互联网协议的工作(但在互联网普及之前很久)。他的爱好包括跑步和通常的家庭主妇和孩子的生活习惯。这项工作代表作者的观点,不一定代表 IBM 的观点。
