
我的另一台电脑是超级计算机
2002 年 11 月,我接到了 Mitch Davis(斯坦福大学 ITSS 学术技术执行总监)和 Carnet Williams(斯坦福大学 ITSS 学术技术总监)的电话,内容是关于一个具有挑战性的、备受瞩目的项目。当时我在斯坦福法学院担任网络运营总监,很高兴在 Mitch 和 Carnet 分别担任斯坦福法学院副院长/CIO 期间与他们共事。他们告诉我,Folding@home 项目的首席研究员 Vijay Pande 博士想要购买一个大型商用集群,他们向 Vijay 推荐了我,认为我可以有效地管理项目直至完成。我本能地同意了。我们讨论了更多项目细节,就在我挂断电话之前,我问:“它会有多大?” 他们回答说:“300 个双处理器节点。” 我心想,“600 个 CPU……这应该能发挥一些作用。”
当 Mitch、Carnet 和 Vijay 与戴尔和英特尔协商集群采购事宜时,我给 Vijay Pande 发送了一封电子邮件,表示我可以协助他处理项目的网络和硬件方面,并希望在此过程中更多地了解软件方面。我在邮件的最后一行写道:“我想参与一些伟大的事情。” Vijay 迅速回复并欢迎我的协助。我们安排了第一次会议,讨论项目的范围。
在最初的会议上,似乎大多数事情都悬而未决。每个人都知道设备即将到来,但没有制定真正的计划。Vijay 说他知道必须做出身份验证和文件系统选择,当然也考虑了使用现有的斯坦福大学服务的机会。
Vijay 还提到了运行 PBS、MPI 和 MOSIX。我对这些几乎一无所知,但我做了笔记,回到我的办公桌后,用 Google 搜索了这些名称以及“beowulf”和“cluster”这两个词。我偶然发现了一个关于使用名为 Rocks 的开源发行版构建集群的演示文稿,该发行版来自一个名为 NPACI 的组织 (www.rocksclusters.org)。演示文稿非常出色。它回答了我的许多问题,例如,我们将如何组装这样一个集群,我们将如何在节点上管理软件,我们将如何配置主节点以及我们将如何监控节点。基本上,演示文稿是我们如何构建集群的框架。我打印了演示文稿的副本,并将它们带到了我们的下一次会议上。使用打包解决方案的想法受到了好评。
在这两次会议召开期间,戴尔正在斯坦福大学的 Forsythe 数据中心对集群进行机架安装和堆叠,这花了七天时间。我下载了 Rocks 2.3 版本的副本,并在 Rocks 命名法中定义为前端节点的设备上运行了安装过程。这项任务很简单,此时我对 Rocks 印象深刻。在我们的第三次会议上,我在项目中的角色已经从仅参与硬件和网络扩展到也处理软件,因为我已经成功地使用 Rocks 启动了前端。我感到有信心也能处理剩下的工作,但此时我还没有意识到项目的真正范围。我正在着手构建已知最大的 Rocks 集群。
我遇到的第一个问题是尝试安装计算节点。Rocks 的一个名为 insert-ethers 的实用程序用于发现计算节点的以太网 MAC 地址,为其分配 IP 地址和主机名,然后在使用 PXE 和 DHCP 的协商过程中将此信息插入数据库。在节点插入之后,节点将按照 Red Hat Kickstart 文件中的定义进行构建和配置,从而完成 PXE 启动过程。不幸的是,我在 Dell PowerEdge 2650 中的网卡遇到了问题,因为 Broadcom 以太网控制器似乎在 Rocks 中不受支持。我将我的问题发送到了 Rocks 讨论列表,并且我还致电戴尔寻求支持,并根据我们的 Gold 支持合同开了一个服务单。Rocks 开发人员迅速提供了一个包含更新驱动程序的集群发行版的实验版本,这解决了问题,很快我就看到我的建议和意见被纳入了 Rocks 2.3.1 版本的维护版本中。

图 1. Forsythe 数据中心的 Iceberg
最终问题是在大规模部署时发现的,即无法拥有超过 511 个活动作业。我的用户对 100 个空闲处理器感到不满,因为 Iceberg 上运行的许多作业都是生命周期短的、一到两个处理器的作业。在与 Rocks 开发团队合作时,我们在 Maui 调度程序代码中查找了一个定义的常量。我最终找到了它,并在 Rocks 团队的指导下,重新编译并重启了 Maui。现在,前端可以调度与处理器数量一样多的活动作业。
到 2002 年 12 月下旬,随着硬件和软件问题的最终解决,我们将目标转向将 Iceberg 列入 TOP500 超级计算机列表 (www.top500.org)。TOP500 是一年两次的竞赛,它根据线性方程求解器 Linpack 的持续性能对 500 个条目进行排名。在 2002 年 11 月的榜单上,有 97 个商用集群,因此我们有信心可以将 Iceberg 列入榜单。
参加 TOP500 榜单的运行证明比我们预期的要付出更多努力。Rocks 附带了一个预构建的 Linpack 可执行文件,可以在 Pentium 4 集群上获得良好的性能,但我想获得更多。我的客户代表让我与戴尔的可扩展系统组取得了联系。我们合作调整了集群上的 Linpack,并完成了一些工作,例如将 Linpack 与 Kazushige Goto (www.cs.utexas.edu/users/flame/goto) 编写的 Goto BLAS(基本线性代数子程序)库链接。此外,戴尔还建议改进互连拓扑。在 TOP500 运行之前,所有 300 个节点都分布在 16 个 100Mbit 以太网交换机(Dell PowerConnect 3024)上。我们发现 Linpack 像许多高度并行应用程序一样,受益于改进的网络互连(换句话说,具有更低的延迟和/或更高的带宽)。戴尔借给我们一个千兆非阻塞交换机来替换我们的一些 100Mbit 交换机。
上述增强功能提高了我们的性能,我们提交了 2003 年 6 月 TOP500 榜单的结果。Iceberg 排名第 319 位,在我看来,如果使用更快的互连,排名可能会更高。

图 2. 运行 Linpack 以获得 TOP500 资格
从一开始,Iceberg 的永久家园就定在 James H. Clark 中心,该中心以 Silicon Graphics 和 Netscape 的创始人命名,他也是 Bio-X 项目的主要资金来源。到 2003 年 8 月,该搬迁了。从 Forsythe 数据中心搬迁带来了许多好处,其中之一是 Rocks 的全新安装。我极力推动这一点,因为拥有坚实而稳定的基础设施是维护如此规模的集群并同时保持较低的总拥有成本的关键。

图 3. 新家中的 Iceberg。从左到右:Vijay Pande,Folding@home 的首席研究员;Steve Jones,Iceberg 架构师;Erik Lindahl,博士后;以及 Young Min Rhee,研究科学家。
在 Iceberg 在 Forsythe 数据中心运行的整个生命周期中,我们发现软件和硬件配置方面的选择都可以改进。搬迁期间造成的停机时间使我们能够对物理设计进行修改。我们决定使用前端节点并将主目录移动到另一个带有附加存储的节点。Rocks 再次发挥了作用。就像使用 insert-ethers 并选择 NAS 设备作为要插入的节点类型一样简单。我们选择使用链路聚合来充分利用 NAS 设备中的双千兆以太网网卡。在前端节点上进行了一些修改以将用户连接到新设备并将备份数据移动到新设备后,我们再次投入运行。
Iceberg 上的 Folding@home
我们将 Iceberg 用作 Folding@home 的调试平台,Folding@home 是一个分布式计算项目,旨在研究蛋白质折叠、错误折叠、聚集和相关疾病。志愿者为该项目贡献空闲处理时间,目前约有 80,000 个 CPU 处于活动状态。
对于 Folding@home 研究,我专门使用 Iceberg 来模拟小型项目,其中一个项目是一组与特定方法耦合的蛋白质模拟。编写一个模仿 Folding@home 与客户端执行操作的脚本是这项工作的关键。对于一次运行,我通常一次使用 10–20 个 CPU。
对于其他大型项目,我仅将 Iceberg 用于启动部分。我们通常以 1ns 为单位计算 10–50ns 的模拟。我可以将 Iceberg 用于前 1ns,然后将其移动到 Folding@home 并继续在那里进行。我们可以在 Iceberg 提供的受控、稳定环境中快速迭代新方法。当我们开发新项目时,我们使用 Iceberg 来验证结果,一旦我们对新方法充满信心,我们就将新项目发布到 80,000 个 CPU 的分布式计算机上。
—Folding@home 项目的 Young Min Rhee,folding.stanford.edu
Iceberg 上的计算生物学
Iceberg 戴尔超级集群彻底革新了我们的研究。我们使用超级计算中心已经几十年了,但我们总是感到受到相对严格的队列、过小的运行时配额以及难以使系统适应我们的需求的限制。在过去的几年里,我们一直在构建自己的 Linux 集群,拥有 50–100 个 CPU,但现成的硬件导致更高的支持和管理成本,更不用说集群有时会空闲的事实,例如当我们忙于撰写论文时。斯坦福大学新的戴尔集群是解决此问题的一种极其经济高效的解决方案;通过拥有共享资源,当我们需要隔夜测试新模型时,可以使用数百个节点,但我们的成本仅是我们使用的节点的平均数量。我们不仅完全负责硬件,而且资源也比我们在安装前后使用的任何资源都强大一个数量级;我们每周只花大约一个小时进行管理。
计算生物学通常涉及对序列或蛋白质结构进行极其繁重的计算。一些最常见的应用包括在序列或结构家族之间找到匹配模式以及模拟生物分子中原子的运动。模式匹配对于少量序列来说没什么大不了的,但我们目前的项目与能源部合作,依赖于大规模预测希瓦氏菌(以其吞噬放射性和有毒废物的能力而闻名)中蛋白质的精确模型。这涉及数十万个序列谱,我们需要对这些序列谱进行全对全比较。过去,这需要在我们的本地集群上进行数周的精心计划的运行,但现在我们实际上能够在一夜之间测试一个想法,并在第二天提交实验的新版本。
原子运动的分子动力学模拟也同样令人印象深刻。简单的想法是计算原子相互施加的力,然后使用牛顿运动方程在很短的时间后确定新的位置(一个步骤通常为 2 飞秒,即 2 × 10-15 秒)。模拟中的单次迭代很快,但研究生物反应需要数十亿步。因此,我们手动优化了我们的代码,以使用 Pentium 4 Xeon CPU 上可用的英特尔流式 SIMD 扩展指令,将我们的程序 Gromacs 和 Encad 的速度提高了 2–4 倍,这使得仅使用 Iceberg 的十个节点上的两周时间,就能够模拟像 Villin 头饰(图 I)这样的蛋白质超过一微秒。实际上,使用优化的代码,即使是单个的戴尔/英特尔 Xeon 处理器也比顶级的 IBM Power4 或 Alpha CPU(在其他超级计算机中发现的芯片)更快,而成本不到十分之一。这是我们有史以来最好的计算机投资,我们将来会毫不犹豫地扩大它。
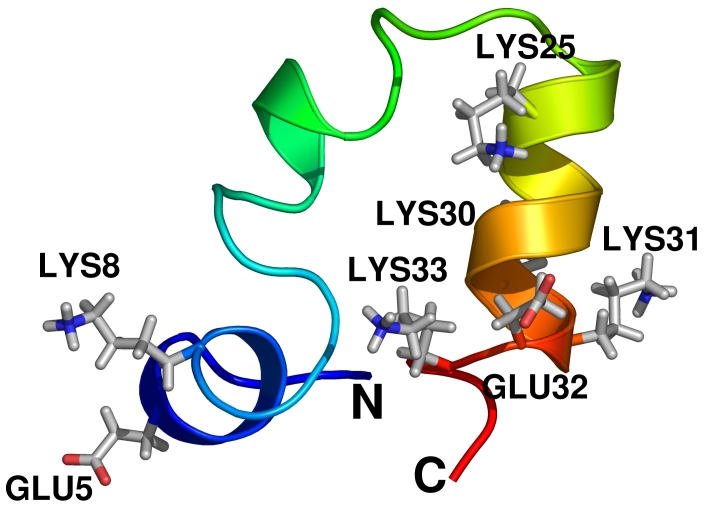
图 I. Villin 头饰
Villin 头饰是一种非常小的蛋白质,由约 600 个原子组成。然而,细胞始终被水(红色/白色棒)包围,这使得原子计数达到约 10,000 个。每个原子都与最近的 100–200 个邻居相互作用;相互作用必须在每一步都计算出来,然后我们重复此过程 5 亿步以生成一微秒的模拟数据。图 I 的数据是从 Iceberg 的十个节点上的两周运行中生成的。
—斯坦福大学医学院结构生物学系的 Michael Levitt 和 Erik Lindahl
任何高性能计算集群的目标都应该是尽快使其进入稳定和工作状态,然后一直运行到硬件报废为止。这使得执行研究的系统用户可以按需使用稳定的系统。为了更改而更改系统不是处理如此规模的计算系统的方式。在我看来,这就是我们选择在其上标准化的集群发行版所提供的。唯一的管理工作应该是监控队列、文件系统大小、查看日志以查找错误和/或活动以及监控硬件以确定是否需要更换。通过 Rocks 和戴尔的支持计划相结合,在计算节点上使用 Silver 支持,在前端使用 Gold 支持,我们将享受三年的无忧性能和部件更换。我们的目标是通过收取计算时间费用来产生资金,以便在三年内更换集群。当新集群到来时,我们将安装 Rocks,我们将开始另一个三年的周期。
目前的计划是对 Iceberg 的使用收费,其想法是产生的收入将足以在三年内购买替换集群。此替换很可能将是 Iceberg-II,具有相同的节点数,但为了最大限度地利用我们的占地面积,采用 1U 外形尺寸而不是 2U。Iceberg 将作为单独的集群保持在线,并随着硬件故障而减小尺寸。
此外,我们正处于计划阶段,将在未来 6-12 个月内购置一个新的 600 节点集群。该集群将安置在异地。我们正在与一家研究机构进行谈判,该机构表示有兴趣免费托管该集群并提供专门的服务(发电、UPS、电源、HVAC 等),以换取集群上的处理时间。也在考虑其他选择。在 Iceberg 范围之外,我正在考虑为商业目的构建另一个集群。我希望认为这将是完成时最大的 Rocks 集群,此外还将在 TOP500 上占据前 20 名。
Steve Jones (stevejones@stanford.edu) 离开了他在斯坦福法学院的职位,以便在一家互联网服务提供商担任安全策略师,同时为一家安全创业公司提供咨询。他正在搬到缅因州,在那里他将担任另一所学校的策略师并创办另一家公司。在他的业余时间,他还将管理一个名为 Iceberg 的 302 节点集群。
