
内核角 - 使用 DMA
DMA 代表直接内存访问,指的是计算系统中设备或其他实体无需通过 CPU 即可修改主内存内容的能力。DMA 的优势在于不打扰 CPU;系统只需请求将数据提取到特定的内存区域,然后继续执行其他任务,直到数据准备就绪。然而,DMA 中的大多数问题都是由于缺乏 CPU 的参与造成的。
DMA 的问题有三个方面。首先,CPU 可能会运行内存管理单元。因此,CPU 用来描述内存区域的地址与主内存的物理地址不同。其次,由于传输是到主内存的,因此该内存和 CPU 之间的缓存可能不一致(请参阅“理解缓存”,LJ,2004 年 1 月)。第三,I/O 总线上也可能存在内存管理单元(称为 IOMMU)。这意味着设备用于传输数据的总线地址可能与物理内存地址或 CPU 的虚拟内存地址不同。这个概念对于大多数 x86 用户来说是陌生的。但即使在这里,AGP 总线使用 GART(图形孔径重映射表)也使得 x86 对 IOMMU 的拒绝不如以前那么强烈。
Linux 内核中管理 DMA 的 API 必须考虑到并解决所有这三个问题。此外,由于大多数 DMA 是从外部总线上的设备完成的,因此可能还会出现三个额外的问题。首先,I/O 设备寻址宽度可能与物理内存的地址宽度不同。例如,ISA 设备被限制为寻址 24 位,而某些 64 位系统中的 PCI 设备被限制为寻址 32 位。其次,I/O 总线控制器电路本身可能会缓存请求。这种情况主要发生在 PCI 总线上,其中写入请求可能被保存在 PCI 控制器中,希望它可以累积这些请求以便快速传输到设备。这种现象称为 PCI 提交。第三,操作系统可能会请求传输到虚拟内存空间中连续但在内存物理空间中碎片化的区域,通常是因为请求的传输跨越多个页面。此类传输必须使用分散/聚集 (SG) 列表来完成。
本文严格讨论用于设备的 DMA API。Linux 2.6 中的新通用设备模型提供了一种描述设备特性并使用分层树查找其总线属性的好方法。所描述的接口在从 2.4 过渡到 2.6 的过程中经历了相当大的修订。尽管本文的一般原则适用于 2.4,但所描述的 API 和内核功能仅适用于 2.6 内核。
对于任何 DMA 传输,首先要考虑的问题是用户可能会请求将大型传输(千字节到兆字节)传输到给定的缓冲区。然而,由于虚拟内存的管理方式,虚拟空间中连续的此区域可能由物理内存中分散的页面序列组成。Linux 期望任何大于页面大小(x86 系统上为 4KB)的传输都需要由 SG 列表描述。通常,这些列表由块 I/O (BIO) 层构建。设备驱动程序的一个关键任务是以某种方式参数化 BIO 层,使其可以将 I/O 分解为 SG 列表元素。
几乎每个传输大量数据的设备都被设计为接受这些传输作为某种形式的 SG 列表。尽管此列表的确切形式可能与内核提供的列表不同,但转换通常很简单。
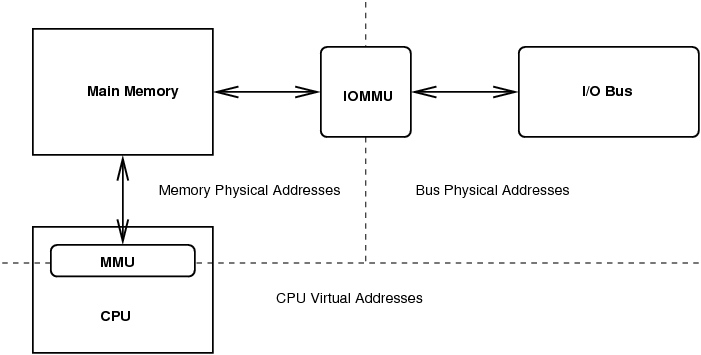
图 1. DMA 中的地址域
IOMMU 是一个内存管理单元,位于 I/O 总线(或总线层次结构)和主内存之间。此 MMU 与内置于 CPU 中的 IOMMU 是分开的。为了实现从设备到主内存的传输,必须对 IOMMU 进行编程,以进行传输的地址转换,这几乎与 CPU 的 MMU 的编程方式相同。这样做的一个优点是,由 BIO 层生成的 SG 列表可以被编程到 IOMMU 中,从而使内存区域对总线上的设备再次显示为连续的。
GART 基本上就像一个简单的 IOMMU。它由物理内存中的一个窗口和一个页面列表组成。它的工作是将窗口中的物理地址重新映射到列表中的物理页面。窗口通常很窄,大约只有 128MB 左右,并且对该窗口之外的物理内存的任何访问都不会被重新映射。这种不足暴露了 Linux 内核当前处理 DMA 的方式中的一个弱点:没有任何 DMA API 具有映射内存失败的失败返回。然而,GART 的重新映射空间有限,一旦耗尽,在某些 I/O 完成并释放映射空间之前,任何内容都可能无法映射。
有时,像 GART 一样,可以对 IOMMU 进行编程,使其在某些窗口中不对 I/O 总线和内存之间的地址进行重新映射。这称为旁路模式,并非所有类型的 IOMMU 都可能实现旁路模式。有时需要旁路模式,因为重新映射行为会给传输增加性能损失,因此将 IOMMU 移开可以提高吞吐量。
然而,BIO 层假设如果存在 IOMMU,则正在使用它,并且它会相应地计算设备 SG 列表所需的空间。目前,没有办法通知 BIO 层设备希望绕过 IOMMU。如果 BIO 层假设存在 IOMMU,则还会假设 SG 条目正在被 IOMMU 合并。因此,如果设备驱动程序决定绕过 IOMMU,则可能会发现其拥有的 SG 条目多于设备允许的条目。
这两个问题都在 2.6 内核中得到解决。IOMMU 旁路的修复程序已经在考虑之中,并且对于驱动程序编写者来说是不可见的,因为平台代码将选择何时进行旁路。映射失败的修复程序可能包括使映射 API 返回失败。由于此修复程序会影响系统中的每个 DMA 驱动程序,因此实施起来将很缓慢。
为了传达最大寻址宽度,每个通用设备都有一个参数,称为 DMA 掩码,其中包含与设备驱动程序必须设置的可访问地址线对应的设置位图。DMA 宽度具有两个不同的含义,具体取决于是否正在使用 IOMMU。如果有 IOMMU,则 DMA 掩码仅表示可能映射的总线地址的限制,但通过 IOMMU,设备能够访问物理内存的每个部分。如果没有 IOMMU,则 DMA 掩码表示设备的根本限制。设备不可能传输到此掩码之外的任何物理内存区域。
块层在构建分散/聚集列表时使用 DMA 掩码来确定页面是否需要反弹。通过反弹,我的意思是块层从 DMA 掩码内的区域获取页面,并将所有数据从超出范围的页面复制到该页面。当 DMA 完成后,块层将其复制回超出范围的页面并释放反弹页面。显然,这种来回复制效率低下,因此大多数制造商都试图确保与其服务器类型机器一起发货的设备没有 DMA 掩码限制。
DMA 的发生不使用 CPU,因此内核必须提供一个 API,使 CPU 缓存与 DMA 更改的内存同步。需要记住的一件事是,DMA API 仅使 CPU 缓存与内核虚拟地址保持同步。您必须使用单独的 API(在我的文章“理解缓存”中描述)来更新与用户空间相关的缓存。
有时,高端总线芯片也带有缓存电路。这背后的想法是,从 CPU 到芯片组的写入速度很快,但跨总线的写入速度很慢,因此,如果总线控制器缓存写入,则 CPU 不需要等待它们完成。总线提交(这种类型的缓存称为总线提交)的问题在于,没有 CPU 指令来刷新总线缓存,因此总线缓存刷新根据严格的规则集工作,以确保正确的排序。首先,规则是只能缓存基于内存的写入。通过 I/O 空间的写入不会被缓存。其次,即使写入被缓存,也必须严格保留基于内存的读取和写入的排序。最后一个属性允许驱动程序编写者刷新缓存。如果您向设备内存区域的任何部分发出基于内存的读取,则保证在读取开始之前发出所有缓存的写入。
没有可用的 API 来帮助提交,因此驱动程序编写者需要记住在读取和写入设备的内存区域时遵守总线提交规则。一个值得记住的好技巧是,如果您真的想不出必要的读取来刷新挂起的写入,只需从设备的总线配置空间读取一条信息即可。
API 在内核文档目录 (Documentation/DMA-API.txt) 中有详细记录。通用 DMA API 还有一个仅适用于 PCI 设备的对应项,在 Documentation/DMA-mapping.txt 中进行了描述。本节的目的是提供正确运行 DMA 所需的所有步骤的高级概述。有关详细说明,您还应该阅读上述文档。
首先,当设备驱动程序初始化时,必须设置 DMA 掩码
int dma_set_mask(struct device *dev, u64 mask);
其中dev是通用设备,并且mask是您尝试设置的掩码。如果掩码已被接受,则该函数返回 true,否则返回 false。如果实际系统宽度较窄,则掩码可能会被拒绝;也就是说,32 位系统可能会拒绝 64 位掩码。因此,如果您的设备能够寻址所有 64 位,您应该首先尝试 64 位掩码,如果设置 64 位掩码失败,则回退到 32 位掩码。
接下来,您需要分配和初始化队列。此过程在某种程度上超出了本文的范围,但在 Documentation/block/ 中有记录。一旦您有一个队列,就需要调整两个重要的参数。首先,允许您的 SG 表的最大大小(或告诉它接受任意大的大小),使用
void
blk_queue_max_hw_segments(request_queue_t *q,
unsigned short max_segments);
其次,(如果您需要),总体最大大小
void
blk_queue_max_sectors(request_queue_t *q,
unsigned short max_sectors);
最后,必须将 DMA 掩码编程到队列中
void
blk_queue_bounce_limit(request_queue_t *q,
u64 max_address);
通常,您将 max_address 设置为 DMA 掩码。但是,如果正在使用 IOMMU,则应将 max_address 设置为 BLK_BOUNCE_ANY,以告知块层不要进行任何反弹。
要操作设备,它必须具有请求函数(请参阅 BIO 文档),其工作是循环并使用命令从设备队列中拉取请求
struct request *elv_next_request(request_queue_t *q);
请求所需的映射条目数位于 req->nr_phys_segments 中。您需要以 sizeof(struct scatterlist) 为单位分配此大小的临时表。接下来,使用以下命令执行临时映射
int
blk_rq_map_sg(request_queue_t *q,
struct request *req,
struct scatterlist *sglist);
这将返回使用的 SG 列表条目的数量。
以下命令提供由块层提供的临时表,该表最终使用以下命令映射
int
dma_map_sg(struct device *dev,
struct scatterlist *sglist, int count,
enum dma_data_direction dir);
其中count是返回的值,并且sglist是传递到函数 blk_rq_map_sg 的同一个列表。返回值是请求所需的实际 SG 列表条目数。SG 列表被重用并填充了需要编程到设备的 SG 条目中的实际条目。dir 提供了关于如何正确处理缓存一致性的提示。它可以有三个值
DMA_TO_DEVICE:数据正在从内存传输到设备。
DMA_FROM_DEVICE:设备仅将数据传输到主内存。
DMA_BIDIRECTIONAL:未给出关于传输方向的提示。
在遍历 SG 列表以编程设备的 SG 表时,应使用两个宏
dma_addr_t sg_dma_address(struct scatterlist *sglist_entry);
它们分别返回每个条目的总线物理地址和段长度。
请求的这种两阶段映射的原因是,BIO 层被设计为通用代码,并且与平台层没有直接交互,平台层知道如何编程 IOMMU。因此,BIO 层唯一可以计算的是 IOMMU 为请求制作的 SG 段的数量。BIO 层不知道 IOMMU 分配给这些段的总线地址,因此它必须传入需要映射的所有页面的物理内存地址列表。正是 dma_map_sg 函数与平台层通信,编程 IOMMU 并检索总线物理地址列表。这也是为什么 BIO 层列表所需的元素数量可能比 DMA API 返回的数量更长的原因。
当 DMA 完成后,必须使用以下命令拆除 DMA 事务
int
dma_unmap_sg(struct device *dev,
struct scatterlist *sglist,
int hwcount,
enum dma_data_direction dir);
通常,设备驱动程序在不接触其传输的任何数据的情况下运行。然而,有时,设备驱动程序可能需要在将其交还给块层之前修改或检查数据。为此,必须使用以下命令使 CPU 缓存与数据保持一致
int
dma_sync_sg(struct device *dev,
struct scatterlist *sglist,
int hwcount,
enum dma_data_direction dir);
其中参数与 dma_unmap_sg 的参数相同。
访问数据最重要的因素是您何时执行此操作。访问规则取决于 dir
DMA_TO_DEVICE:API 必须在修改数据之后但在将其发送到设备之前调用。
DMA_FROM_DEVICE:API 必须在设备返回数据之后但在驱动程序尝试读取数据之前调用。
DMA_BIDIRECTIONAL:API 可能需要调用两次,一次在修改数据之后但在将其发送到设备之前,另一次在设备完成数据处理之后但在驱动程序再次访问数据之前。
大多数设备使用邮箱类型的内存区域在设备和驱动程序之间进行通信。此邮箱区域的通常特征是它永远不会在设备驱动程序之外使用。使用以前的 API 管理邮箱的一致性将是一项相当繁琐的任务,因此内核提供了一种分配内存区域的方法,该内存区域保证在设备和 CPU 之间始终保持一致
void
*dma_alloc_coherent(struct device *dev, size_tsize,
dma_addr_t *physaddr, int flag);
这将返回大小一致区域的虚拟地址,该区域还具有设备的总线物理地址 (physaddr)。flag 用于指定分配类型 GFP_KERNEL 以指示分配可能会休眠以获取内存,GFP_ATOMIC 指示分配可能不会休眠,如果无法获取内存,则可能返回 NULL。由此 API 分配的所有内存也保证在虚拟内存和总线物理内存中都是连续的。绝对要求 size 小于 128KB。
作为驱动程序删除的一部分,必须使用以下命令释放一致性内存区域
void
dma_free_coherent(struct device *dev, size_tsize,
void *virtaddr,
dma_addr_t *physaddr);
James Bottomley 是 SteelEye 的软件架构师。他也是开源社区的积极成员。他维护 SCSI 子系统、Linux Voyager 端口和 53c700 驱动程序,并在 DMA/设备模型抽象领域的 PA-RISC Linux 开发中做出了贡献。

