
了解缓存
自从微处理器诞生的早期,系统设计师就一直被一个问题所困扰,即 CPU 的运行速度超过了与其连接的内存子系统的带宽。为了避免在等待内存获取请求的数据时浪费 CPU 周期,普遍采用的解决方案是使用一块更快速(因此也更昂贵)的内存区域来缓存主内存数据。这种解决方案允许 CPU 以其自然速度运行,只要其所需的数据在缓存中可用。
本文的目的是从内核程序员的角度解释缓存。我还解释了一些用于描述缓存的常用术语。本文分为几个部分,这些部分指示了内核编程的相关性;也就是说,某些部分解释说缓存属性与理解内核如何处理缓存的本质无关。如果您来自 Intel IA32 背景,那么缓存对您来说几乎是透明的。然而,为了编写在 Linux 支持的所有架构上都能正确运行的内核代码,您需要了解缓存工作原理的基本知识。
简而言之,缓存是缓冲内存访问的位置,并且可能拥有您请求的数据的副本。通常,人们认为缓存(可能不止一个)是堆叠的;CPU 位于顶部,然后是一层或多层缓存,最后是主内存。在这个层次结构中,缓存按其级别进行量化。最靠近 CPU 的缓存称为一级缓存,简称 L1,缓存级别依次增加,直到到达主内存。
缓存行是可以传输到缓存或从缓存传输的最小内存单元。量化缓存的基本要素称为读写行宽。这些表示缓存必须从其下方的内存或缓存读取或写入的最小数据量。通常,这些量是相同的,因此缓存通常仅通过行宽来量化。即使它们不同,最长的宽度通常也称为行宽。
量化缓存的下一个属性是其大小。此数字指示缓存中可以存储多少数据。通常,性能经验法则是缓存越大,基准测试结果越好。
多级缓存可以是包含性的或排他性的。排他性意味着特定的缓存行可能只存在于缓存级别中的一个级别中,并且不超过一个。包含性意味着该行可能同时存在于多个缓存级别中。没有任何东西阻止不同缓存级别中的行宽不同。
最后,特定的缓存可以是直写式或回写式。直写式意味着缓存可以存储数据的副本,但写入必须在下一级完成,然后才能向上层发出完成信号。回写式意味着只要数据存储在缓存中,写入就可以被认为是完成的。对于回写式缓存,只要写入的数据未传输,缓存行就被认为是脏的,因为它最终必须写出到下一级。
缓存最基本的问题之一是一致性。当缓存行中的数据与被缓存的主内存中存储的数据相同时,该缓存行被称为一致的。如果情况并非如此,则该缓存行被称为不一致的。缺乏一致性可能会导致两个特殊的问题。第一个问题,可能发生在所有缓存中,是陈旧数据。在这种情况下,主内存中的数据已更改,但缓存尚未更新以反映此更改。这通常表现为不正确的读取,如图 1 所示。这是一个瞬时错误,因为正确的数据位于主内存中;缓存只需要被告知将其带入即可。
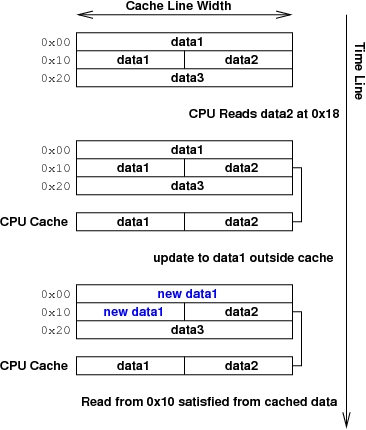
图 1. 陈旧数据问题
第二个问题,仅发生在回写式缓存中,可能导致实际的数据损坏,并且更具隐蔽性。如图 2 所示,数据在内存中已更改,并且也已被 CPU 写入缓存单独更改。由于缓存必须一次写出一行,因此现在无法调和这些更改——要么必须清除缓存行而不写入,从而丢失 CPU 的更改,要么必须写出该行,从而丢失对主内存所做的更改。所有程序员都必须避免达到数据损坏不可避免的地步;他们可以通过明智地使用各种缓存管理 API 来做到这一点。
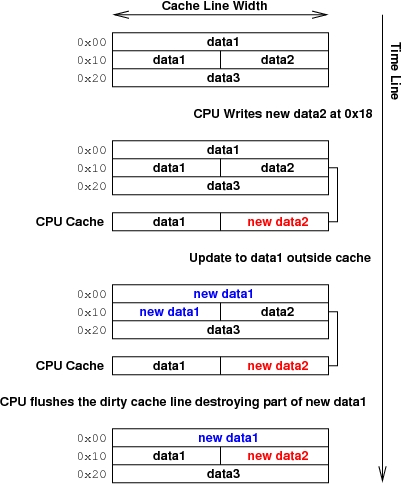
图 2. 脏缓存行导致的数据损坏
两个独立的数据集位于同一缓存行中的情况,可能会导致上面详述的数据损坏,这种情况称为缓存行冲突。如果您要在内存中布置数据结构,则避免这种情况的一般规则是永远不要将可以在缓存外部修改的数据与 CPU 可能通常使用的数据混合在一起。如果您绝对必须违反此规则,请确保结构的所有外部可修改元素都按照 L1_CACHE_BYTES 对齐,该值在编译时设置为代码可能运行的所有处理器可能的最大缓存宽度值。最好的方法是使用 kmalloc 分配两个单独的区域。kmalloc 永远不会分配在缓存行中重叠的两个区域。
最基本的指令称为无效化,它只是从所有缓存中弹出指定的行。对该行中数据的任何引用都会导致它从主内存中重新获取。因此,可以通过在读取数据之前使缓存行无效来解决陈旧数据问题。在 Linux 中,这样的无效化是通过以下方式完成的
void
dma_cache_inv(unsigned long address
unsigned long size);
其中 address 是开始的虚拟地址,size 是要无效化的数据长度。请注意,size 会自动向上舍入为缓存行宽度的倍数。
对于回写式缓存,可以使用以下命令将任何脏缓存行写出或刷新到主内存
void
dma_cache_wback(unsigned long address,
unsigned long size);
在任何事物更改脏缓存行下的主内存之前,必须完成此刷新。因此,您必须在外部实体(例如 PCI 卡)修改主内存之前发出刷新,并在刷新之后但在 CPU 访问任何已更改的数据之前发出无效化。
理论上,对于回写式缓存,无效化会杀死缓存行而实际上不写出数据,从而破坏缓存中的数据。在这种情况下,更安全的做法是发出刷新和无效化指令
void
dma_cache_wback_inv(unsigned long address,
unsigned long size);
本节解释缓存的实际工作原理。您需要从本节获得的唯一重要信息是一个称为别名的属性,这意味着内存中的同一物理地址可以缓存在多个不同的缓存行中。内核实际如何管理别名将在下一节中讨论。
在直接映射缓存中,如图 3 所示,缓存被划分为已知宽度的缓存行(示例中为四个)。缓存中的每一行都以唯一的索引为特征,因此缓存中的每个字节都通过行的索引和行内的偏移量来寻址。缓存的每个索引还拥有一个隐藏数字,称为标签。

图 3. 直接映射缓存
系统中的每个地址都分为三部分——标签、索引和偏移量——沿着二的幂边界(图 4)。当一行被带入缓存时,标签和索引从地址中提取。该行存储在缓存中的所需索引处,隐藏标签与行数据一起存储。当 CPU 引用特定地址时,将在给定索引处查询缓存。如果标签匹配,则提取行内的偏移量以满足地址引用。如果标签不匹配,则当前行可能会被刷新回主内存,并将正确的行带入缓存。
每个可缓存地址都有一个且只有一个对应的索引行,这可能会导致问题。例如,如果处理器读取一系列地址,这些地址意外地恰好对应于相同的缓存索引,则必须在每次读取时逐出并重新获取缓存行。这种情况很容易发生在例如 for 循环中,该循环读取恰好与缓存大小大致相同的结构元素。对于直接映射缓存,索引有时称为缓存颜色,而此问题称为缓存行着色问题。
为了解决直接映射缓存的着色问题,有时会安排缓存电路,以便缓存查找可以同时比较多个缓存行中的标签。在 N 路组相联缓存中,每个索引对应于 N 个缓存行(和标签);因此,我们可以在缓存中同时拥有最多 N 个具有相同索引的地址。增加的并行缓存查找电路往往会增加关联性的成本,因此通常仅在高档 CPU 中才能找到它。
在范围的顶端,您可能会找到一个全相联缓存。这种类型的缓存根本没有索引,在查找特定标签时会同时查询所有行。
所有现代 CPU 都处理地址转换,这意味着内核或应用程序用于引用内存的虚拟地址与数据实际驻留的物理地址不同。缓存可以放置在地址转换之前或之后,有时在分层缓存中,位置是混合的。以下描述了每种放置的不同属性和特征。
在物理索引、物理标签 (PIPT) 缓存中,缓存的标签和索引都在物理内存中,即在虚拟地址转换完成后。此过程非常简洁明了,但 PIPT 缓存的缺点是有效的地址转换必须位于 CPU 的 TLB(转换后备缓冲区)中。如果需要在完成地址转换之前从内存中获取此类 TLB 条目,则缓存数据的优势就会丧失。即使存在 TLB 条目,也必须按顺序完成 TLB 查找和缓存查找,这使得这些缓存速度较慢。
另一方面,在虚拟索引、虚拟标签 (VIVT) 缓存中,索引和标签都位于 CPU 当前正在运行的虚拟地址空间中。尽管这使得缓存查找速度更快(在查找之前或之后如果缓存查找成功,则无需进行地址转换),但它们也存在其他几个问题
虚拟地址转换通常作为正常内核操作的一部分进行更改,因此缓存必须密切关注 TLB 条目的更改(以及地址空间的更改),并刷新其转换已更改的缓存行。
即使在单个地址空间中,同一物理地址也可能存在多个虚拟地址。这些虚拟地址中的每一个都将被单独缓存,即使它们表示相同的数据。这称为缓存行别名问题。
然而,总的来说,VIVT 缓存的额外查找速度超过了其缺点,使其成为非 x86 CPU 的主要缓存类型。
一种旨在克服 VIVT 缓存的一些缺点而又不牺牲太多其速度优势的混合缓存类型是虚拟索引、物理标签 (VIPT) 缓存。索引位于虚拟地址上,但标签位于物理地址上,因此组合(标签、偏移量)必须指定完整的物理地址。此要求导致标签大于其他缓存类型的标签。
VIPT 缓存相对于 PIPT 获得速度优势,是因为地址转换和缓存查找现在可以并行完成。然而,CPU 在地址转换完成之前不知道缓存行是否有效(标签匹配)。
VIVT 的缺点得到了克服,因为标签是物理的,因此当 VIPT 缓存看到缓存中的两个标签相同时,它会自动检测别名。因此,可以构建 VIPT 缓存,使其永不发生缓存行别名。
第四种理论类型的缓存,物理索引、虚拟标签 (PIVT),基本上是无用的,因此不再赘述。
每当内核为同一物理页面设置多个虚拟映射时,都可能发生缓存行别名。内核会小心避免别名,因此别名通常仅在一种特定情况下发生:当用户 mmap 文件时。在这里,内核在页面缓存中具有文件页面的一个虚拟地址,并且用户可能具有一个或多个不同的虚拟地址。这是可能的,因为没有什么可以阻止用户在多个位置 mmap 文件。
当文件被 mmap 时,内核会将映射添加到 inode 的列表之一:i_mmap,用于不能更改底层数据的映射;或者 i_mmap_shared,用于可以更改文件数据的映射。用于使页面缓存别名同步的 API 是
void flush_dcache_page(struct page *page);
每当内核更改页面上的数据时都必须调用此 API,如果 page->mapping->i_mmap_shared 不为空,则应在从页面读取数据之前调用此 API。在特定于架构的代码中,flush_dcache_page 循环遍历 i_mmap_shared 列表并刷新缓存数据。然后,它循环遍历 i_mmap 列表并使其无效,从而使所有别名同步。
为了追求效率,处理器通常具有单独的缓存,分别用于它们执行的指令和它们操作的数据。通常,这些缓存是单独的机制,数据写入可能不会被指令缓存看到。如果您尝试执行刚写入内存的指令,例如在模块加载期间或使用 trampoline 时,这会引起问题。您必须使用以下 API
void
flush_icache_range(unsigned long start,
unsigned long end);
当系统中存在多个 CPU 时,通常存在一个缓存级别,该级别对于每个 CPU 都是唯一的。根据架构,内核可能负责确保一个 CPU 缓存中的更改对其他 CPU 可见。幸运的是,大多数 CPU 在硬件中处理这种类型的一致性问题。即使它们不这样做,只要您遵循本文中列出的 API,您就可以在所有 CPU 上保持一致性。
James Bottomley 是 SteelEye 的软件架构师。他维护 SCSI 子系统、Linux Voyager 端口和 53c700 驱动程序。他还为 PA-RISC Linux 开发在 DMA/设备模型抽象领域做出了贡献。
