
使用 RCU 扩展 dcache
RCU(读取-复制更新)是一种针对多读取数据结构优化的同步技术,最近已添加到 Linux 2.6 内核中。本文介绍了 RCU 如何提高 Linux 目录项缓存 (dcache) 的可扩展性。有关更多背景信息,请参阅 Linux Journal 2003 年 10 月刊中的“在 Linux 2.5 内核中使用 RCU”。
Linux 的 dcache 维护文件系统层次结构的内存部分映像。此映像无需昂贵的磁盘传输即可进行路径名查找,从而大大提高了文件系统操作的性能。为了简化挂载和卸载操作的处理,Linux 内核还在 struct vfsmount 结构中维护挂载树的映像。
如果 Linux 2.4 dcache 如此出色,为什么要更改它? 2.4 dcache 的难点在于它使用了全局 dcache_lock。如图 1 所示,此锁是小型系统上缓存行弹跳的来源,也是大型系统上的可扩展性瓶颈。

图 1. Tux 尽职尽责
本节为与 RCU 相关的 dcache 更改提供背景信息,这些更改将在本文后面部分介绍。希望了解更多细节的读者应深入研究源代码。
本节使用图 2 所示的示例文件系统树,该树具有两个已挂载的文件系统,根目录分别为 r1 和 r2。第二个文件系统挂载在目录 b 上,如虚线箭头所示。文件 g 最近未被引用,因此未出现在 dcache 中,如其虚线蓝色框所示。

图 2. 示例文件系统树
dcache 子系统维护文件系统树的多个视图。图 3 显示了目录结构表示。每个表示目录的 dentry 维护一个双向链表循环列表,该列表以 d_subdirs 字段为头,贯穿子 dentry 的 d_child 字段。每个子 dentry 的 d_parent 指针引用其父 dentry。挂载点(dentry b)不直接引用已挂载的文件系统。相反,挂载点的 d_mounted 标志已设置,并且 dcache 在 mount_hashtable 中查找已挂载的文件系统,此过程将在稍后介绍。
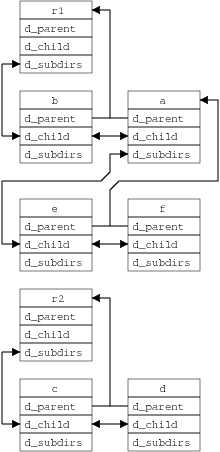
图 3. 示例文件系统树的 dcache 表示
尽管可以直接搜索 d_subdirs 列表,但对于大型目录来说,这将是一个缓慢的过程。相反,__d_lookup() 哈希父目录的 dentry 指针和子目录的名称,在全局 dentry_hashtable 中搜索相应的 dentry。此哈希表如图 4 所示,以及以 dentry_unused 为头的 LRU 列表。LRU 列表中的任何 dentry 通常也在哈希表中。例外情况包括父目录超时的案例,例如在 NFS 等分布式文件系统中。

图 4. dentry 哈希表
每个 dentry 都使用 d_inode 指针引用其 inode。对于负 dentry,此 d_inode 指针可以为 NULL,负 dentry 缺少 inode。当文件系统删除 dentry 的文件或有人尝试锁定不存在的文件时,可能会生成负 dentry。负 dentry 可以通过避免重复访问给定的不存在的文件而无需调用底层文件系统来提高系统性能。类似地,硬链接会导致多个 dentry 共享一个 inode,如图 5 所示。

图 5. 硬链接别名链
图 6 显示了高级 dentry 状态图。正常 dentry 的生命周期如下
d_alloc() 为新引用的文件分配新的 dentry,从而导致状态为“新建”。
d_add() 将新的 dentry 与其名称和 inode 关联,从而导致状态为“已哈希”。
完成文件操作后,d_put() 将 dentry 添加到 LRU 列表,并在其 d_vfs_flags 字段中设置 DCACHE_REFERENCED 位,从而导致状态为“LRU 引用(已哈希)”。
如果在“LRU 引用(已哈希)”状态下再次引用该文件,则 dget_locked()(通常从 d_lookup() 调用)会将其标记为正在使用。如果在下一次 prune_dcache() 调用时它仍在使用,则会从 LRU 列表中删除,再次导致状态为“已哈希”。
否则,prune_dcache() 最终会从 d_vfs_flags 字段中删除 DCACHE_REFERENCED 位,从而导致状态为“LRU(已哈希)”。
与之前一样,如果再次引用该文件,dget_locked() 会将其标记为正在使用,以便 prune_dcache() 可以将其从 LRU 列表中删除,再次导致状态为“已哈希”。
否则,对 prune_dcache() 的第二次连续调用会通过 prune_one_dentry() 调用 d_free(),从而导致状态为“死亡”。
图 6 中可能存在其他路径。例如,如果分布式文件系统将缓存的文件句柄转换为新的 dentry,则当相应对象的父对象不再在 dentry 缓存中表示时,它会调用 d_alloc_anon() 来分配 dentry。类似地,使用 d_delete() 删除给定 dentry 下的文件或目录会将该 dentry 移动到“负”状态。在最后一次关闭时,它将前进到“死亡”。
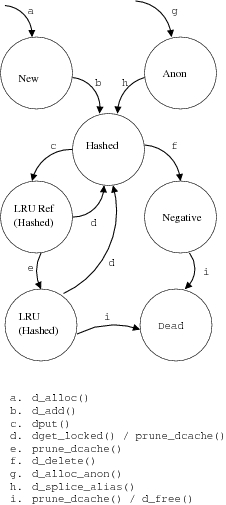
图 6. dentry 状态图
图 7 显示了 mount_hashtable 数据结构,该结构用于将挂载点 dentry 映射到已挂载文件系统的 struct vfsmount。此映射哈希挂载点 dentry 的指针和包含挂载点的文件系统的 struct vfsmount 的指针。dentry 指针和 struct vfsmount 的这种组合允许更优雅地处理同一挂载点上的多个挂载。

图 7. 遍历挂载点
图 2 中显示的示例文件系统布局将导致如图 8 所示的 struct vfsmount 结构。vfs1 结构将根 dentry r1 同时引用为 mnt_mountpoint 和 mnt_root,因为此文件系统是文件系统树的最终根目录。vfs2 结构将 dentry b 引用为 mnt_mountpoint,将 r2 引用为 mnt_root。因此,当 mount_hashtable 查找返回指向 vfs2 的指针时,mnt_root 字段会快速定位已挂载文件系统的根目录。

图 8. VFS 挂载树
已挂载文件系统的整体形状反映在 mnt_mount/mnt_child 列表中。这些列表被 copy_tree() 等函数使用,在执行环回挂载时,需要遍历整个路径名空间特定子树中挂载的所有文件系统。
dcache 的完全并行化将非常复杂,并且被认为对于 2.5 后期的工作来说风险太大。2.6 dcache 只是 RCU 道路上的一步;2.7 的目标是在不获取任何锁的情况下走完整个路径。
清单 1. 无锁路径名段查找
1 struct dentry *
2 __d_lookup(struct dentry * parent,
3 struct qstr * name)
4 {
5 unsigned int len = name->len;
6 unsigned int hash = name->hash;
7 const unsigned char *str = name->name;
8 struct hlist_head *head = d_hash(parent,hash);
9 struct dentry *found = NULL;
10 struct hlist_node *node;
11
12 rcu_read_lock();
13 hlist_for_each (node, head) {
14 struct dentry *dentry;
15 unsigned long move_count;
16 struct qstr * qstr;
17
18 smp_read_barrier_depends();
19 dentry = hlist_entry(node, struct dentry,
20 d_hash);
21 if (unlikely(dentry->d_bucket != head))
22 break;
23 move_count = dentry->d_move_count;
24 smp_rmb();
25 if (dentry->d_name.hash != hash)
26 continue;
27 if (dentry->d_parent != parent)
28 continue;
29 qstr = dentry->d_qstr;
30 smp_read_barrier_depends();
31 if (parent->d_op &&
32 parent->d_op->d_compare) {
33 if (parent->d_op->d_compare(parent, qstr,
34 name))
35 continue;
36 } else {
37 if (qstr->len != len)
38 continue;
39 if (memcmp(qstr->name, str, len))
40 continue;
41 }
42 spin_lock(&dentry->d_lock);
43 /*
44 * If dentry is moved, fail the lookup
45 */
46 if (likely(move_count ==
47 dentry->d_move_count)) {
48 if (!d_unhashed(dentry)) {
49 atomic_inc(&dentry->d_count);
50 found = dentry;
51 }
52 }
53 spin_unlock(&dentry->d_lock);
54 break;
55 }
56 rcu_read_unlock();
57 return found;
58 }
路径名段查找由清单 1 中所示的 __d_lookup() 函数执行。__d_lookup() 函数使用指向父目录 dentry 的指针和要查找的名称调用。名称在 struct qstr 中传递,其中包含指向字符串的指针、其长度、dcache 哈希表的预计算哈希值以及名称本身(如果需要)。
第 5-7 行解组 struct qstr。第 8 行将名称和父 dentry 指针的组合哈希到全局 dcache 哈希表中,从而生成指向相应哈希链的指针。
第 12 行和第 56 行标出代码的 RCU 保护段,在 CONFIG_PREEMPT 内核中禁用抢占,如 Linux Journal 2003 年 10 月刊中题为“在 Linux 2.5 内核中使用 RCU”的文章中描述的 Reader-Writer-Lock/RCU 类比所指定的那样。第 13-55 行循环遍历所选哈希链中的元素,查找匹配的 dentry。第 18 行发出内存屏障,但仅在 DEC Alpha 上。在其他 CPU 上,指针解引用隐含的数据依赖性就足够了,因此在这些 CPU 上,第 18 行不生成任何代码。
由于此查找未获取任何锁,因此它可能与重命名系统调用竞争。这样的系统调用可能会将 dentry 移动到另一个哈希链,从而将此查找也带走。第 21 行和第 22 行检查此竞争,但它们本身并不足够。因此,第 23 行获取当前 dentry 已遭受重命名的次数的快照,即 dcache d_move() 函数,该函数稍后用于确定是否有任何重命名与路径遍历竞争。第 24 行是一个内存屏障,以确保快照不会被编译器或 CPU 重新排序。
第 25-28 行检查名称哈希和父 dentry。如果任何一个不匹配,则此 dentry 不可能是我们查找的目标。第 29-41 行执行完整的名称比较,第 30 行在 DEC Alpha 上使用内存屏障。可以提供特定于文件系统的名称比较函数,例如,用于不区分大小写的文件系统,如第 33 行所示。
如果执行到达第 42 行,我们找到了一个具有匹配名称的子 dentry。然后,我们在第 42 行获取子 dentry 的锁。由于我们拥有每个 dentry 的锁,因此这些单个锁上的争用级别远低于原始 dcache_lock 上的争用级别。尽管如此,生活并不完美。例如,根 dentry 上的锁仍然容易受到争用,稍后将讨论此主题。
子 dentry 可能在第 23 行获取 d_move_count 快照后被重命名。因此,第 46-47 行将 d_move_count 的当前值与快照进行比较。如果检查通过,则子 dentry 未被重命名到查找之外,并且第 48-51 行递增引用计数 - 但前提是该条目仍然已哈希。
第 53 行释放子 dentry 的锁,第 54 行跳出哈希链搜索循环。如果查找成功,第 57 行返回指向子 dentry 的指针,否则返回 NULL。
__d_lookup() 的失败并不意味着失败会返回给用户进程。该文件实际上可能存在,但尚未加载到 dcache 中。
但是,此函数不能防止所有重命名竞争风险。一个额外的竞争是由 dcache 使用 hlist 而不是 list 作为 dcache 哈希链的事实引起的。它使用 hlist 来节省内存,因为 hlist 在列表标头中需要一个而不是两个指针。但这确实意味着 hlist 与 list 不同,它不是循环的。因此,可能会发生特定的 dentry 被重命名,使其落在先前为空的 dcache 哈希链中。如果这在正确的时间发生,则 __d_lookup() 函数可能会错误地返回搜索失败。
不正确返回的搜索失败由上层 d_lookup() 函数处理,如清单 2 所示。任何竞争重命名都由第 13 行的 read_seqretry() 函数检测到。由于有问题的案例仅导致虚假失败,因此仅在从 __d_lookup() 返回 NULL 时才进行检查。
清单 2. 路径名段查找重命名竞争解决
1 struct dentry *
2 d_lookup(struct dentry * parent,
3 struct qstr * name)
4 {
5 struct dentry * dentry = NULL;
6 unsigned long seq;
7
8 do {
9 seq = read_seqbegin(&rename_lock);
10 dentry = __d_lookup(parent, name);
11 if (dentry)
12 break;
13 } while (read_seqretry(&rename_lock, seq));
14 return dentry;
15 }
d_free() 函数必须延迟释放给定的 dentry,直到宽限期过后,因为任意数量的正在进行的路径遍历可能持有对该 dentry 的引用。延迟在清单 3 所示的 d_free() 函数中完成,其中第 5 行使用 call_rcu() 原语来延迟 d_callback() 函数中的破坏性操作,直到宽限期过后。d_callback() 函数如清单 4 所示;它只是在第 5-7 行中释放单独存储的大名称(如果适用),然后在第 8 行中释放 dentry 本身。
清单 3. dentry 结构的延迟释放
1 static void d_free(struct dentry *dentry)
2 {
3 if (dentry->d_op && dentry->d_op->d_release)
4 dentry->d_op->d_release(dentry);
5 call_rcu(&dentry->d_rcu, d_callback, dentry);
6 }
清单 4. dentry 的 RCU 回调函数
1 static void d_callback(void *arg)
2 {
3 struct dentry * dentry = (struct dentry *)arg;
4
5 if (dname_external(dentry)) {
6 kfree(dentry->d_qstr);
7 }
8 kmem_cache_free(dentry_cache, dentry);
9 }
d_move() 函数实现重命名系统调用的 dentry 特定部分,如清单 5 所示。第 5 行排除任何其他尝试更新 dcache 的任务,第 6 行允许 d_lookup() 确定它已与重命名竞争。第 7-13 行获取正在重命名的文件及其目标的每个 dentry 锁,按地址排序以避免死锁。第 14-17 行从其在 dcache 哈希表中的旧位置删除条目(如果尚未删除)。
第 19 行更新 dentry 以指向其新的哈希桶,第 20-21 行将 dentry 添加到其目标哈希桶,第 22 行更新标志以指示 dentry 存在于 dcache 哈希表中。第 24 行从 dcache 哈希表中删除目标 dentry(正在使用 rename() 重命名的 dentry),第 25-26 行将移动和目标 dentry 与其旧父级分离。
第 27 行更改 dentry 的名称,第 28 行强制执行写入顺序。名称更改并非易事,因为短名称存储在 dentry 本身中,而较长的名称存储在单独分配的内存中。第 29-32 行更新名称长度和哈希值。第 33-44 行将 dentry 连接到其新父级。最后,第 45 行更新 d_move_count,以便 __d_lookup() 可以检测到竞争,第 46-49 行释放锁。
从理论上讲,精心设计的持续重命名操作序列,旨在将 dentry 保留在同一目录和同一哈希链中,可能会无限期地阻止非常不幸的查找。发生这种阻塞的一种方式是,如果查找正在搜索哈希链中的最后一个元素,并且当查找到达第二个到最后一个元素时,第二个到最后一个元素被一致地重命名(因此移动到列表的头部)。在实践中,dcache 哈希链很短,重命名速度很慢。但是,如果这些阻塞成为问题,则可能需要添加代码以在路径遍历失败时阻止重命名。正在考虑的另一种方法是完全消除全局哈希表,转而修改 d_subdirs 列表,以便优雅地处理大型目录。
清单 5. 重命名 dentry
1 void
2 d_move(struct dentry *dentry,
3 struct dentry *target)
4 {
5 spin_lock(&dcache_lock);
6 write_seqlock(&rename_lock);
7 if (target < dentry) {
8 spin_lock(&target->d_lock);
9 spin_lock(&dentry->d_lock);
10 } else {
11 spin_lock(&dentry->d_lock);
12 spin_lock(&target->d_lock);
13 }
14 if (dentry->d_vfs_flags & DCACHE_UNHASHED)
15 goto already_unhashed;
16 if (dentry->d_bucket != target->d_bucket) {
17 hlist_del_rcu(&dentry->d_hash);
18 already_unhashed:
19 dentry->d_bucket = target->d_bucket;
20 hlist_add_head_rcu(&dentry->d_hash,
21 target->d_bucket);
22 dentry->d_vfs_flags &= ~DCACHE_UNHASHED;
23 }
24 __d_drop(target);
25 list_del(&dentry->d_child);
26 list_del(&target->d_child);
27 switch_names(dentry, target);
28 smp_wmb();
29 do_switch(dentry->d_name.len,
30 target->d_name.len);
31 do_switch(dentry->d_name.hash,
32 target->d_name.hash);
33 if (IS_ROOT(dentry)) {
34 dentry->d_parent = target->d_parent;
35 target->d_parent = target;
36 INIT_LIST_HEAD(&target->d_child);
37 } else {
38 do_switch(dentry->d_parent,
39 target->d_parent);
40 list_add(&target->d_child,
41 &target->d_parent->d_subdirs);
42 }
43 list_add(&dentry->d_child,
44 &dentry->d_parent->d_subdirs);
45 dentry->d_move_count++;
46 spin_unlock(&target->d_lock);
47 spin_unlock(&dentry->d_lock);
48 write_sequnlock(&rename_lock);
49 spin_unlock(&dcache_lock);
50 }
尽管 dcache 的这种更改相对较小,但它对内核产生了深远的影响,因为文件系统与 dcache 交互的明确定义的 API 尚未到位。由于文件系统黑客尝试以传统方式直接操作 dcache,这导致 Linux 2.5 内核中出现大量错误。鉴于现在已经存在某种程度上更正式的 API,我们希望未来的更改不会那么痛苦。
图 9 显示了在 Linux 2.5.59 内核上运行的多用户基准测试的性能,该内核已修补为在目录项缓存中使用 RCU,与未修补内核的性能进行比较。这些基准测试在 16 CPU NUMA-Q 系统上运行,使用 700MHz PIII Intel Xeon,具有 1MB L2 缓存和 16GB 内存。

图 9. 多用户基准测试性能
将 dcache_rcu 补丁应用于 Linux 2.4.17 内核,在 8 CPU PIII Xeon 服务器上,SPECweb99(不含 SSL)吞吐量从 2,258 提高到 2,530,提高了 12%。将相同的补丁应用于 Linux 2.5.40-mm2 内核,Linux 内核构建消耗的系统时间从 47.548 CPU 秒减少到 42.498 CPU 秒,减少了 10% 以上。在运行 Linux 2.5.42 内核的单处理器 700MHz PIII Xeon 系统上运行的类似测试显示没有变化。总而言之,dcache RCU 不仅提高了高端机器的扩展性,而且还在低端机器上保持了良好的性能。
尽管 2.6 dcache 系统比 2.4 版本更具可扩展性,但仍有许多问题需要研究
更新仍然由 dcache_lock 门控,这意味着更新密集型工作负载无法很好地扩展。
全局哈希表破坏了缓存局部性,并使更新代码比必要的更复杂。当然,任何替代方案都必须保留其优势,包括高性能处理大型目录。
2.6 dcache 代码获取每个 dentry 的 d_lock 自旋锁,从而导致缓存行弹跳和原子操作,尤其是在根目录和工作目录上。需要进行大量思考才能找到简单的解决方案,因为将权限移动到 dentry 中被证明非常复杂。
解决 __d_lookup() 和 d_move() 之间竞争的代码过于复杂。
我们热切期待参与 2.7 的工作以解决这些问题,希望最终得到如图 10 所示的情况。

图 10. Tux 在 2.7 中的职责
这项工作代表了作者的观点,并不一定代表 IBM 的观点。
SPEC 和基准测试名称 SPECweb 是标准性能评估公司的注册商标。基准测试仅用于研究目的,由于以下与规则的偏差,可能无法与 SPECWeb 网站上发布的 results 进行比较
它在不符合 SPEC 公开发布标准的硬件上运行。该机器是工程样品。
access_log 未保留用于完整核算。它正在写入,但每 200 秒删除一次。
有关最新的 SPECweb99 基准测试结果,请访问 www.spec.org。
Paul E. McKenney 是 IBM 的杰出工程师,并且从事 SMP 和 NUMA 算法的工作时间比他愿意承认的要长。在此之前,他从事分组无线电和互联网协议的工作(但在互联网流行之前很久)。他的爱好包括跑步和通常的家庭主妇和孩子们的习惯。
Dipankar Sarma 目前正在从事许多 Linux 内核项目,包括 CPU 热插拔、RCU 和 VFS 增强功能。在他的 Linux 时代之前,他曾在 ABI、OS 启动、I/O 驱动程序和多路径 I/O 等多个领域工作过。
Maneesh Soni 一直在 IBM 的 Linux 技术中心担任 Linux 可扩展性项目组的成员。他在系统软件领域,特别是操作系统内核和文件系统方面拥有经验。
