
集群免费,节点随意
在 Quantum Magnetics 公司,我们从事合同研发。我们经常需要设计硅芯片、模拟电磁系统和分析来自现场测试的大量数据。当一组回归测试开始花费超过一个工作日的时间来执行时,合著者 Alex Perry 发现自己想知道如何短期访问集群。我们在此描述了使我们能够轻松设置 OpenMosix 集群而无需购买任何东西的步骤序列。
每一次生产力的提高都证明了将时间投入到下一步,即建立全公司范围的集群是合理的。我们在此省略了每个项目的说明和常见问题解答中提供的详细信息(请参阅在线资源部分),部分原因是到文章付印时情况将会发生变化,部分原因是为了简洁起见。
在集群上运行的最简单的应用程序是基于命令行并在同一台计算机上作为多个实例运行的应用程序。应用程序不必专门为 Linux 编写,因为它们可以使用 WINE 或其他可移植性层。如果多个实例不可能,则必须投入更多时间来提供虚拟机抽象层。在投入任何精力构建集群之前,值得检查一下您的特定应用程序,看看它是否能够从基于 OpenMosix 的集群中受益。
我们的大部分逻辑代码都是用 Verilog 编写的,部分原因是,正如笑话所说,我们打字不够快,无法使用 VHDL。但主要是因为 Verilog 中有更广泛的工具可用。我们在 Microsoft Windows 下使用多个闭源的布局布线工具,它们的运行时很小,因此将它们放在集群上是不值得的。对于仿真,我们有开源和闭源选项。当试图追踪错误时,使用具有 IDE 源代码级调试器的图形工具(不幸的是,都是闭源的)很方便,但这些工具要么不喜欢集群,要么在集群上运行时有高昂的许可价格标签。我们使用 Icarus Verilog 进行非交互式仿真,因为回归测试占总仿真工作量的 99% 以上。我们喜欢它,因为多个仿真器可以并行运行;每个仿真器都是一个单独的 Linux 进程;该工具拥有自己的公共回归套件;开发人员乐于助人且反应迅速;并且语法解析器非常严谨和准确。
语法解析器的严谨性为我们标记了很多问题。许多解析器只是选择对模糊编写的源代码的一种解释,导致不正确的行为,这实际上是一个错误。相比之下,Icarus 会立即抱怨歧义,在我们进行微小的重写后,合成的芯片突然开始按照预期的那样工作。
Icarus 的开发人员通过快速响应错误报告和补丁,增强了仿真器在我们工作中的价值。我们从 CVS 更新以受益于那些几乎即时的源代码更改。此外,标准化一个虚拟机(集群)比管理单个工作站上的版本容易得多。
我们在从 CVS 检索新版本的 Icarus 之前和之后立即运行我们所有的专有仿真测试。大约每年一次,仿真结果都会有所不同,因此我们提交一份错误报告,将问题定位到我们专有工作之外的测试用例。通过这种方式,我们所有的专有工作都充当了 Icarus 项目的附加回归套件,而无需我们将其提供给我们的竞争对手。它还确保了 Icarus 的任何官方版本对我们都有用。
列表 1. 芯片设计项目 Makefile 的摘录,显示了回归测试是如何发生的。%.txt 参考数据是使用 C 和 AWK 自动生成的。
TESTS = test1 test2 test3 test4
.PHONY:default
default: $(TESTS:%=%.log)
-hostname -f
-cat $(TESTS:%=%.log)
%: %.vl
iverilog -o$* $<
%.vl: %.v
./Makefile.sh $^ > $@
test1.vl: source5.v source7.v
%.log: Makefile %.txt %.out
ls --full-time $*.out > $@
diff -b -C2 $*.txt $*.out >> $@
echo "... PASS ..." >> $@
.PRECIOUS: %.out %.txt
%.out: %
time ./$* > $@
.PHONY: %.batch batch
%.batch: %
echo "make $*.log" | batch -m
batch%: $(TESTS)
echo "make -l $*.5" | batch -m
shell 脚本 Makefile.sh 确保 Icarus 和 Makefile 始终就用于构建仿真的源文件达成一致
#! /bin/bash
echo -n "// "; date
for item in $*; do
echo "\`include \"$item\""; done
在我们的工程设计工作中,我们使用make,如列表 1 所示,以自动化测试执行并管理所有 Verilog 源文件、C 语言的参考实现、验证的测试数据、回归测试池和所有仿真结果。
如果没有集群,完成由对源文件的少量更改引起的所有依赖关系需要 6 到 10 个小时。逻辑仿真通常比现实生活慢一百万倍左右,因此回归测试仅模拟约 20 毫秒的时间。必须仔细选择测试,因为电路板每次使用可以运行长达 30 秒(大约相当于一年的仿真时间)。
工作中最重要的部分是数据和所有正在进行的工作的中间状态,因为即使您有备份和外部版本控制检查点,这里的任何损坏都会使您倒退几天。RAID 1 或 5 阵列是通常的保护措施。一台计算机,而不是最快的计算机之一,应该至少有两个硬盘驱动器在不同的控制器上。值得确保每个驱动器都有一个小交换分区,以便内核可以使用所有交换分区并进行一些负载平衡。
打开内核空间 NFS 服务器,并从保护数据存储免受损坏的角度配置 /etc/exports。当 NFS 处于高负载下时,用户空间程序必须被交换出去,为额外的磁盘缓存腾出空间。考虑使用可以延迟以禁用所有定期唤醒以进行次要目的的服务的运行级别。
我们正在使用一台现有的双 Athlon MP 机器,它具有超过 1TB 的存储空间,并运行 Debian stable 作为我们的 NFS 服务器。该系统对于集群来说是过度的;我们最初构建它是为了存档现场测试数据,然后将数据流式传输到多个客户端进行分析。没有使用 X 服务器,因为散热风扇发出的噪音太大,没有人希望机器放在他或她的办公桌旁边。
使用make batch2在一台双处理器机器上,我们的运行时间减少了约 40%,其中一个处理器在运行结束时接近空闲状态。总运行时间在 4 到 6 个小时的时钟时间内。即使没有集群,也可以通过使用带有公钥身份验证的 OpenSSH 在多台机器上分配工作来改进这一点。《Linux Journal》文章(Daniel R. Allen 的“Eleven SSH Tricks”,2003 年 8 月)解释了如何配置这个强大的软件包,以避免无休止的密码提示流,同时增强网络安全性。
列表 2. 这在多台计算机上并行运行仿真。运行时间是一致的,但可能效率低下。
#! /bin/bash
for pair in host1/test1 host2/test2 \
host2/test3 host5/test4
do test=`basename $pair`
make $test
ssh `dirname $pair` vvpstdin \
< $test > $test.out &
done
wait; make
Icarus 仿真引擎 vvp 无法从标准输入加载,因此我们使用这个 vvpstdin 脚本
#! /bin/bash F=/tmp/`basename $0`.tmp.$$ cat > $F /usr/local/bin/vvp $F exec rm $F
共享工作的机器通常具有不同的性能能力。重要的是将各种测试的相对运行时间与各个处理器的速度相匹配,记住 SMP,以便所有测试在大约相同的时间完成。我们发现最好在像列表 2 中所示的脚本中手动优化映射。
通过使用 SSH 连接到两台双 Athlon MP 机器、一台 Pentium III 笔记本电脑和五台 Pentium II 台式机,我们将运行时间减少到相当一致的两个小时。
如果每个人都运行相同发行版的相同版本,那么安装 OpenMosix 的预打包二进制文件可能就足够了。这样,您就可以在不费吹灰之力的情况下获得工作负载迁移。始终使用自动配置选项,而不是手动指定节点列表,因为集群在后期阶段会增长。
我们在办公室中使用几种不同的发行版,因此我们下载了一个原始的 2.4.20 内核 tarball、匹配的 OpenMosix 补丁和用户空间工具的源代码到 NFS 文件服务器。在仔细记录配置设置以使所有机器保持同步后,我们按照 OpenMosix 网站上的说明进行操作。由于重新编译和重新安装内核需要花费我们的时间和精力,我们只修改了集群七个处理器所需的四台计算机。这比通过 SSH 实现的十个处理器能力稍差。即便如此,最坏情况下的运行时间仍然几乎相同,因为迁移所做的负载平衡比我们手动优化的脚本可以实现的要好一些。因为 Alex 可以使用make -j并让 OpenMosix 分配工作,所有增量工作负载完成得更快,不需要完整的两个小时。
OpenMosix 试图做到公平,并通过在更快的计算机上放置更多工作来使所有程序以相同的速度运行。然而,这对于逻辑仿真工作负载来说不是最佳的,因为我们通常知道相对运行时间。在这种情况下,一个简短的脚本(此处未包含)有助于监视 /proc 的内容。该脚本定期查找预期运行时间比率很大但节点分配未提供相应执行速度比率的进程对。该脚本使用其先前运行的知识来请求迁移,以获得 OpenMosix 隐藏的长期利益。如果对于您的应用程序,所有进程的运行时间相似,则不需要这样的脚本。
通常,可以在角落里找到很多备用的旧计算机。在其中一台计算机上放置一个 X 服务器,该服务器配置为充当快速计算机上 xdm 服务中的终端。使用这台机器,您可以关闭快速计算机上的 X 服务器,并将它们的处理器和内存资源释放回重要的工作负载中。Alex 的台式计算机,一台 400MHz Pentium II,已经通过 xdm 的选择器间接连接了它的 X 服务器。David 的工作使他需要在建筑物内漫游并依赖 VNC,因此他已经在使用 Xvnc。只有 Hoke 需要对配置文件进行少量更改。
接下来,在一台计算机上安装 LTSP,并将所有其他旧计算机设置为使用无盘启动也成为终端。这样做消除了管理所有这些操作系统的麻烦。现在您应该有足够的终端站,以便您的所有团队成员都在使用终端,并且所有快速计算节点都可以保持在精简的运行级别并尽可能高效。让这两个功能工作起来并不需要很长时间,每当您等待正在运行的作业时,都是处理此问题的绝佳时机。
无需使 LTSP 的 DHCP 和 TFTP 组件工作。将内核放在软盘上,以及配置为触发非启动 DHCP 的 SysLinux,并挂载 NFS 根文件系统。然后,使用该软盘对终端进行一次性启动。重新启动并不频繁,因此软盘的缓慢速度是可以接受的。
一旦集群和 LTSP 都正常运行,我们只需将它们组合起来。列表 3 中所示的简短脚本使用 NBI 工具将修补后的内核放入 /ltsp/i386/boot。我们的 DHCP 服务器的文件名参数是一个软链接,因此我们可以在测试升级时快速更改 LTSP 内核。在将用户空间工具复制到客户端文件系统并将 init 脚本重命名为 rc.openmosix 后,我们在 LTSP 启动脚本中添加了列表 4 中的几行。较慢的计算机在 LTSP 配置文件中具有MOSIX=N,因为它们不会为集群贡献太多性能。
/ltsp/i386/etc/inittab 中的一行
ca:12345:ctrlaltdel:/sbin/ctrlaltdel
列表 3. 此 /ltsp/i386/usr/src/netkernels 将内核从构建树复制到 TFTP 目录。
#! /bin/bash
for vsn in 2.4.20 2.4.21
do pushd linux-$vsn; make bzImage; popd
s=linux-$vsn/arch/i386/boot/bzImage
d=../../boot/vmlinuznbi-$vsn
mknbi-linux --ip=dhcp \
--append "root=/dev/nfs" $s >$d
done
列表 4. 这几行附加到 LTSP 启动脚本 /ltsp/i386/etc/rc.local。
MOSIX=`get_cfg MOSIX Y` if [ "$MOSIX" = "Y" ]; then echo 1 > /proc/hpc/admin/lstay AUTODISC=1 /etc/rc.openmosix start fi
列表 5. 新的关机脚本
#! /bin/bash prefix="Control Alt Del detected: " echo "$prefix OpenMosix" /etc/rc.openmosix stop echo "$prefix ShutDown" /sbin/shutdown -r -n now echo "$prefix failed (give up)"
一旦您确信 LTSP-OpenMosix 内核稳定且不会更改,您就可以分发带有新内核的软盘。LTSP 用户不会看到任何差异,但您的计算工作负载会看到差异。
如果您想保留在不必在公司内四处寻找所有旧软盘的情况下更改内核的选项,那么现在是使 DHCP 网络启动工作的好时机。LTSP 文档描述了如何配置 Linux 或 UNIX 服务器,但我们的实现是在 Microsoft Windows 上运行的。David 是我们基于 Windows 的 DNS 和 DHCP 服务器的管理员,他在 DHCP 中设置了 Netboot(图 1)。
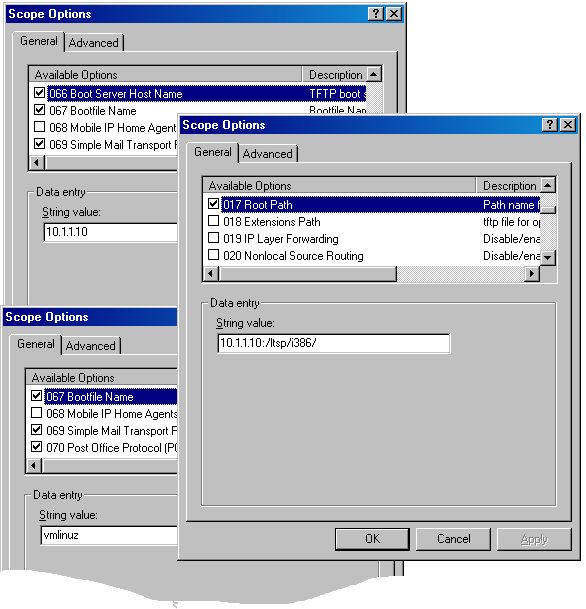
图 1. Windows DHCP 服务器上需要的三个作用域条目。请注意,根路径具有尾部斜杠解决方法。
正如 LTSP 邮件列表所讨论的,Microsoft DHCP 会将空值附加到 NFSROOT,因此您需要一个软链接
ln -s /ltsp/i386 /ltsp/i386/000
列表 6. 此 /ltsp/i386/usr/src/bootfloppy 为多种型号的网卡制作软盘网络启动盘。
#! /bin/bash
if test "$EUID" != "0"; then exec sudo $0; fi
# Configuration options
L="eepro100 rtl8029 rtl8139 tulip 3c905c-tpo"
E=etherboot-5.0.10/src
item=3c905c-t
F=${0}.img
M=$F.mnt
C=$M/syslinux.cfg
CC=$M/toc.txt
# Create the virtual bootable floppy disk
dd if=/dev/zero of=$F bs=1024 count=1440
mkdir -p $M; mkdosfs $F; syslinux $F
mount -t vfat -o loop $F $M
# Populate the floppy with configuration files
cat <<END >$CC
This floppy image is at http://ltsp$F
The bootloaders are built using $E
If you don't have a $item, you need to type
in the card name below. If your network card is
not listed, please notify $USER@qm.com To change the
default permanently, you need to edit the
file `basename $C`
END
cat <<END > $C
display `basename $CC`
prompt 1
timeout 100
default $item
END
# Now add the bootable images
for item in $L
do T=bin32/$item.lzlilo
pushd $E; make $T; popd
item=${item:0:8}
cp $E/$T $M/$item
echo >>$CC " $item"
done
flip -m $C
flip -m $CC
# Release the floppy disk
df $M; umount $M; rmdir $M
多年来,我们的 LTSP 部署一直在为各种工程计算机提供多个 X 工作站,我们从未需要中央应用程序服务器。列表 6 中所示的脚本构建了一个软盘映像,用于所有计算机。用户只需指定网卡型号即可。
借助这种基础设施,任何集群用户都可以带着其中一张软盘在建筑物内漫步,并将空闲机器重新启动到集群中,直到有足够的资源来高效运行工作负载。对于逻辑仿真,Alex 只需添加机器,直到集群中的快速计算机多于套件中的慢速测试,这样回归测试永远不会超过 16 分钟。凭借这种效率提升,他迅速完成了设计。在不运行 mtop 的情况下,您永远不会注意到 OpenMosix 将计算密集型进程迁移到集群中。与此同时,其他人正在将网络用于不同的项目。
Quantum Magnetics 拥有约 100 名员工,因此我们的集群限制在 100 个节点左右,因为有些人拥有不止一台计算机。我们正在进行设置,以便机器晚上在集群中度过,白天作为普通用户工作站。它们每天至少重新启动两次,并检查一个配置目录,以决定是从网络启动还是从硬盘驱动器启动。
BIOS 必须配置为在硬盘驱动器之前尝试 PXE 启动。DHCP 服务器区分 EtherBoot 和 PXE 启动请求,后者接收 PXELINUX 的启动文件名。有两个配置文件目录,一个用于白天,一个用于晚上,还有一个小的 cron 作业在它们之间切换。白天启动链接到硬盘驱动器上的主引导记录,晚上启动链接到 EtherBoot 的 PXE 版本。
LTSP 配置文件指示哪些机器必须在工作日早上重新启动,并导致 ctrlaltdel 脚本运行。如果用户提前上班,只需按下 Ctrl-Alt-Del 即可尽快将机器恢复到白天模式。
远程 Windows 管理用于强制工作站在晚上不活动后注销,然后重新启动一次。如果两个网络启动阶段中的任何一个失败,机器将启动 Windows 并且不加入集群。
一旦您的按需集群平稳运行,请抵制通过购买大量您不需要的台式计算机来增加它的诱惑。使用带有台式计算机的 LTSP 具有成本效益,仅仅是因为您已经为它们付费。当它们的任何组件发生故障时,获取、安装或维护它们都不会产生经济支出。专用的多处理器机架式计算机是向集群添加处理能力的最便宜的方式。通过省略不必要的 периферийные устройства,它们还可以节省金钱、电力、冷却和一些故障。
OpenMosix 或 Mosix 提供了一种快速简便的方法来获得集群优势,但内核正在实时做出迁移决策。它本质上不如使用显式工作负载管理效率高,显式工作负载管理将进程专用于各个节点并使用 MPI 进行通信。由于您可以在同一集群中同时支持 Mosix 和 MPI,因此您可能希望将作业控制和 MPI 库添加到 LTSP 客户端文件系统中。集群感知应用程序利用 MPI 并实现可用的最终性能。其他应用程序始终从 Mosix 获得部分好处。
在双 MPI/Mosix 集群上,用户有动力迁移到 MPI 应用程序。Mosix 的负载平衡算法始终优先考虑本地 MPI 进程而不是迁移的 Mosix 进程,因此集群非感知应用程序运行得更慢。我们尚未开始使用 MPI,因为我们的关键工程应用程序都不足以从中受益,从而证明建立它所需的努力是合理的。
我们支持 QM 逻辑仿真需求的下一步是使用协同仿真,其中回归测试在可编程逻辑芯片上实时运行。测试速度也令人印象深刻,因为它消除了百万分之一的仿真速度比率。考虑到也必须放置在可编程芯片中的协同仿真支持逻辑,大约 10% 的逻辑可以一次性测试。因此,每个芯片都可以像 50,000 节点集群一样快速地执行测试。
无需更改 Linux 和集群配置,但开源工具对于保持过程简单至关重要。每个测试都必须在执行前由布局布线工具处理,测试平台必须以特殊方式编写,并且新的数据组织级别跟踪所有正在进行的工作。
LTSP 在 Windows 网络中运行良好,并且可以轻松地在整个公司临时部署软件,而无需修改硬盘驱动器。在 OpenMosix 集群上部署 Icarus 节省了数月的开发时间,并确保了更可靠的产品。开源组件的灵活性提高了我们的生产力,而我们的集群的可用性增强了我们的公司能力。
本文资源: /article/7553。
Alexander Perry 博士 (alex.perry@qm.com) 是加利福尼亚州圣地亚哥 Quantum Magnetics 公司的首席工程师。
Hoke Trammell (hoke.trammell@qm.com) 是 Quantum Magnetics 电磁传感部门的科研人员。
David Haynes (david.haynes@qm.com) 是 Quantum Magnetics 的公司网络管理员。
