
Linus 与疯子们,第一部分
本系列文章包含在去年九月举行的最新 Linux 疯狂极客邮轮上的两次演讲的文字记录。有关背景详情,请查看关于整个邮轮的三部分报告;下一部分的链接位于前两部分的末尾。
第一次演讲是在阿拉斯加海岸锡特卡和基奇坎之间的某处海上进行的,是 Linus 关于内核的第二次年度进展报告。本系列文章的第一部分(如下)是 Linus 演讲的准备部分。它包括他用来阐述观点的幻灯片和屏幕投影。第二部分是随后更长时间的问答环节的文字记录。第三部分是大约 30 位 Linux 疯子和 维多利亚 Linux 用户组 的 50 名成员之间会议的摘录。Linus 在其中发挥了主导作用,内核开发者 Ted Ts'o 也是如此。
这些文字记录已经过轻微编辑,仅为了清晰起见。所以请用耳朵倾听,并保持开放的心态。如果你这样做,我敢打赌你会学到比你已经知道的更多关于为什么 Linux 和越来越依赖它的世界继续如此良好地相互适应的原因。
--Doc Searls

Linus:正如你们大多数人可能已经知道的那样,我讨厌发表演讲...... 我希望这主要是一个问答环节。但通常情况下,冷场开始的问答环节效果不佳。所以我通常为我的问答环节做的是放一些幻灯片。如果幻灯片最终变得有趣,并且我收到了关于幻灯片的问题,幻灯片可以占据整个环节。但这很少发生,因为幻灯片往往很无聊。
但我注意到我过去常常做很多关于 2.6 版本新特性的演讲,对吧?或者关于某些特定功能的一些技术想法。我决定这次完全不这样做。因为我注意到我现在实际上不再做的是编码...... 既然我仍然在谈论技术性的东西,我决定我最好谈谈管理方面的东西...... 关于出现的一些问题的几张幻灯片。
我真的只有几点是真正重要的。显然,人——管理人,以及让人为你管理人——最终成为更重要的部分之一。另一个是,我们已经开始使用很多工具进行管理。其中之一显然是源代码控制。另一个是,我正在编写这个 C 语言解析器,因为我决定我需要它并且想要它。

所以人似乎实际上是 最大 的问题。
[笑声。]
在过去几年里,我收到的最多的负面评论是,例如,Linux 内核邮件列表不是一个非常友好的地方。人们实际上害怕在邮件列表上发帖,因为他们会受到激烈的抨击。
很难找到不抨击、冷静和理性——而且 有良好品味的人。我的意思是,这就像……给我一个诚实的人。这种情况不会经常发生……太多了。但与此同时,当这种情况发生时,它非常重要。仅仅 少数 这样的人就能产生巨大的影响。
Allen Cox 过去在某种程度上是主要的负责人。他要去攻读 MBA,别问我为什么。
[笑声。]
显然他也厌倦了。这是问题之一。那就是这是一个非常引人注目的事情。优秀的人往往会很快崛起。一旦你达到某个程度,你就会受到很多尊重;但很难达到那个程度。这需要惊人的时间。这是一份全职工作,因为如果你经常离开一周,你最终将无法管理很多发生的事情。问题之一往往是,嗯,参与内核开发的公司在安排工程师负责 他们 [工程师] 关心的特定领域方面做得相当好。但似乎很难让公司真正安排管理者——这些技术管理人员进入……
部分原因显然是责任问题。某些公司——例如我知道 IBM——有一条规定,他们的工程师不得提交其他人的代码。提交他们自己的代码是可以的,但如果你接受了别人的代码并提交了——至少在某些部门是这样,我不知道这是否适用于所有部门——这意味着如果你有这项政策,就不可能成为内核的这种技术经理。因为你需要接受其他人的代码并基本上进行发布。
很多人基本上忽略了它。Greg 为 IBM 工作。他似乎不太在意 IBM 的规定,并且他做得非常好。Andrew Morton 现在是我的得力助手。他实际上出现的时间并不长。他在 Linux 领域活跃了大约三年,他也是我选择 2.4 版本维护者的 [听不清],只是那时他对整个事情来说太新了。所以杰出的人很快就会脱颖而出。但另一方面,真正获得许多新面孔存在很多问题。公司决定,“嘿,我们 也想要一位新的经理”。因为他们自己也面临着寻找优秀技术经理的问题。
所以这是我一直以来最大的问题之一。就是找到基本上充当内核管理者的那些人。
这不是 Linux 特有的问题。但我只是想说这可能是最大的问题。

让这件事变得非常重要的是问题的规模。我从 [听不清] 那里取出了一些关于今年发生的事情的统计数据。不是过去十二个月,而是 2003 年的日历年,所以只是过去九个月左右的时间。
我们有超过 500 人进行了 12000 次更改。屏幕上看起来像一个非常精确的数字,但我所做的是获取所有电子邮件地址,完全删除了主机名,然后只对第一部分进行了唯一计数。有很多 David 被算作一个人。但另一方面,这种情况非常罕见,但有些人确实出现过两次,仅仅是因为他们有两到十个电子邮件地址,他们实际上使用了不同的名字,而不仅仅是不同的主机。
虽然二十% 的人做了九十% 的更改是事实,这是一个非常倾斜的数字,但这部分原因是,在前二十% 的人中,有很多管理者实际上最终合并了来自其他人的更改。这方面的典型例子是,第一名不是我…… 我排在第二位,这让我很高兴。但第一名是 Andrew Morton。他自己编写代码,但至少他所做的一半工作是,他也从其他人那里收集东西,这是完成这项工作的唯一明智方法。
所以是的,从某种意义上说,这确实非常倾斜,在 12000 次更改中,我认为有 1500 次是 Andrew 做的,但与此同时,这实际上掩盖了一个事实,即有超过 500 人参与其中。
我喜欢这样。有 500 人参与其中很重要。因为如果你最终有一个核心小组,很多项目都有,只有 30 人参与,而其他人从不做任何事情,那么这个项目就会死亡。我的意思是,这不是是否会死亡的问题;而是何时死亡的问题,对吧?
所以你希望有人真正参与进来,并开始做很多这些更改显然非常小。这就是你如何进入这个领域的方式。
这很好,而且很重要。但这里的副标题 [在标题“更多关于人”] 是“CVS 有什么问题。” 这也是我永远不会碰 CVS 的原因。我工作了六年,这个数字很有趣:在九个月里,我们进行了 2900 次合并。我所说的合并是指实际上在两个树上进行了并行工作,然后将它们连接起来。这不仅仅是复制一棵树并在没有代码更改的情况下进行简单的合并。实际上有 2300 次,不同的人并行进行了更新,并且必须将它们合并。我认为其中大约有 50 次是手动合并的。其他一切都是自动的。
这样做的好处是 [对听众说]——谁实际使用过 CVS?谁使用过带分支的 CVS?谁曾经做过一次合并而没有感到难受?
[笑声。]
想象一下进行 2300 次合并。

这里有这么多合并的部分原因是 [部分原因是] 有很多开发人员并行地做事;但这部分是因为 BK (BitKeeper) 使它变得如此容易。我们一直都在进行合并。这真的很有帮助,因为你不会有这种特殊的日子,当你有一个长期存在的分支,它经历了可能半年的开发,而主线也经历了半年的开发,并且它们的存在有完全不同的原因——当你合并它们时,你会有可能在过去六个月内的任何地方引入的错误。因此,对我来说,让合并变得容易对于许多不同的人来说非常重要。
很多人不喜欢 BitKeeper。我不会 本身 推 BitKeeper。重要的是合并。并且意识到有很多工作完成了,但从未合并回去。我自己也一直这样做。我做了一些事情,我启动了第二个单独的树来测试一些东西,并决定“这太糟糕了”。我永远不会将它合并回去。所以你实际上甚至看不到分支比合并更多的这个事实。如果你有五百多人,你显然不能信任他们……
我坚信,如果你的源代码控制不支持随机的人创建他们自己的分支,然后能够在他们与任何其他人的分支进行开发时进行合并,那么源代码控制就不值得费心。如果 BitKeeper 消失了,我不会转向 Subversion 或类似的东西。我会回到 tarball 和补丁。因为至少它没有大多数其他项目都有的合并问题。这有点奇怪,但是…… 它非常高效。拥有真正分布式的系统非常有帮助。但我确实想提一下。
上次极客邮轮我提到了 BitKeeper。那时它仍然有点争议,因为我只使用了它大约四个月左右。人们还没有那么习惯它。这一次,很明显,即使是那些不喜欢许可证本身的人似乎也意识到,当源代码管理做得正确时,它是多么有用。而 CVS 不是。
所以,我一直在做的另一个工具……基本上源于我个人的信念,即 ANSI C 基本上是为神设计的语言。为想要控制一切的人设计的语言,对吧?你可以保留你的脚本语言,你的玩具——
[笑声。]
——但你无法控制世界。你无法用它创造控制一切的东西。C 可以。

ANSI C 是 好 的。但我 讨厌 K&R I。我 拒绝 接触 K&R 代码。我看着仍然使用 K&R 的项目…… [有些人] 说,“嘿,我们必须支持遗留系统。” 我说“去他妈的遗留系统。” 没有遗留系统值得再去维护了。用一个真正的编译器吧。
ANSI C 和 K&R 之间唯一的真正区别是类型检查。我非常相信静态类型检查,它不会增加任何运行时开销。因此,假设你的编译器是完美的——无论如何——你基本上可以获得完美的性能,并具有相当好的安全性。问题是内核必须做很多破坏类型检查的事情。你在内核中看到的比在许多其他程序中看到的要多。你最终会有很多内联汇编,这显然是完全不透明的。
[来自听众] ...C 类型检查?
是的。没错。这也是 Sparse 的原因。你可以扩展类型检查,以便你可以描述内核想要做的各种事情。这样你实际上可以为你感兴趣的领域获得相同的静态类型检查。
很多这实际上是受到斯坦福检查器的启发。你们有多少人听说过斯坦福检查器?一些人。斯坦福的人基本上使用了 GCC,稍微调整了一下,使其输出依赖链和许多其他信息,编写了许多脚本来遍历内部 GCC 组织的结构。他们实际上在某种程度上从解析流中自行确定了规则,类型检查。
问题是,你无法获得源代码,它非常复杂——这绝对是一个研究项目——部分原因是,因为他们试图使用未修改的内核源代码,并从未修改的内核源代码中找出规则是什么。这真是 男子气概。但这是一种非常愚蠢的男子气概的方式。
[笑声。]
因为你真正可以做的就是直接将注释添加到内核源代码中,这样你就不必弄清楚规则是什么。你使它们显式化,这很好,因为你使它成为程序员自己的专属,这最终 与 你现在可以自动检查它的事实一样有用。所以我决定 [使用] 斯坦福工具,这些工具甚至没有发布——他们每隔几个月才做一次他们的工作——真的不是正确的方法。
所以我写了 Sparse。最好用一个例子来解释。

基本上你可以将属性添加到任何类型的数据类型。在 Sparse 中,数据类型的一个属性是它所属的地址空间。这是一个定义,如果你不使用 Sparse,它就会消失。
因此,GCC 不知道任何关于地址空间的信息,永远不会看到任何其他代码。因此,GCC 对待完全相同的代码就像它一直做的那样;但是当你使用 Sparse 检查器运行时,它会注意到当你调用 copy_to_user 时,第一个参数必须是用户指针。好吧,address_space (1),工具本身并不真正关心用户或内核;你可以将它用于任何东西。如果它得到任何不是用户指针的东西,例如,如果你错误地交换了参数,这种情况发生过,它会发出一个大大的警告,说“嘿,地址空间不匹配。” 这样做的好处是——好吧,在 copy_to_user 中,它不是那么有趣,因为该函数显然复制到用户空间。但我实际上会展示……[在键盘上输入类型]……像这样……

……基本上获取 exec.c 的参数,并计算有多少个参数或有多少个环境变量。所以它获取一个指向用户空间的指针,该指针 指向 用户空间——所以它们两者实际上都是指向,内核上的不同地址空间,所以你确实知道它真正意味着什么。从这个意义上来说。你知道你不能直接通过引用(?)它。所以你实际上同时拥有内核的文档。因为 Sparse 实际上会跟踪你访问的类型。
它注意到,当你对 __user * __user * 上的内容执行 get_user 时,它不会抱怨,因为它得到了一个 __user *,但它会返回一个 __user *。
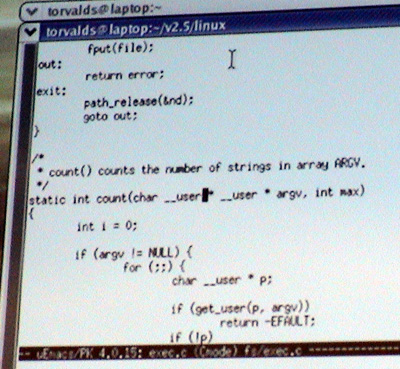
所以现在,如果我在这里为 p 使用了错误的类型,Sparse 也会抱怨并说,“嘿,你实际上没有得到内核指针。你得到了用户指针。所以你最好使用正确的指针。”

[来自听众的问题,听不清。]
Sparse [听不清] 资产编译器。我实际上把它做成了一个完整的前端。一旦你完成了解析和管道检查,你实际上就有了所有这些信息。Jeff Garzik,因为我有点推动他这么做,为 386 写了一个后端。
[来自听众的问题,听不清。]
好吧,代码生成器真的很新。它就像一个星期前才出现的。测试示例往往看起来像,“惊喜,惊喜”。对吧?有趣的部分是,这是一个非常难以解析的程序。有人能猜到为什么吗?

[听众,听不清。]
[听不清] 本身很容易。这只是一个函数调用。这个调用会引入大约三十个不同的头文件,其中包含新的扩展,对吧?所以你必须正确设置所有属性,以免发出关于头文件的警告。事实证明,如果你实际上尝试编译这个——
[听众,听不清。]
相信我,你需要那个头文件。因为 Sparse 会拒绝接触任何没有原型的东西。因为它会说“我不知道类型是什么,我无法检查它们。” 所以你需要头文件。所以这些是警告。

Sparse 不理解 mode 属性。所以,现在,我们将不得不修复它才能编译用户空间。

生成的代码是垃圾。但它实际上碰巧可以工作,所以你可以做的是——
[听众,听不清,笑声。]
但我实际上想要代码生成器是因为它验证了解析器正在做正确的事情。这真的很难做到。输出解析流是一件令人讨厌的事情。对于任何稍微有趣的东西,它们看起来都完全无法阅读,对吧?这意味着真正验证前端是否做对了的唯一方法实际上是编写一个后端。如果后端生成的代码实际上可以运行,你就不必关心它是否高效。你知道前端工作正常,对吧?
这有点离题了。
我还有另一个例子,我们尚未在内核中使用它,但我为内核设计了它,目的是给出

再次强调,任何对象不仅具有地址空间;但你可以做上下文掩码来说,“好吧,你只能在特定上下文中使用此对象。” 我的意思是,这部分你又会隐藏在头文件中。Sparse 不知道 IRQ 之类的东西,它 不应该 知道 IRQ 之类的东西。但它可以说,“好吧,上下文掩码中的这些位意味着我对这个特定上下文感兴趣,并且这些位最好与我关心的其他位匹配。” 对吧?这意味着一旦你有了那个头文件,你就可以弯曲。你可以说,“好吧……” ira_handler?那是一个射杀别人的处理程序吗?
[笑声。]
[我的意思是] irq_handler。重点是,这也是我最终也想添加到内核中的,说“这个函数可以录音”。(?)现在我们实际上动态地检查这一点。现在我们实际上动态地检查这个动态线索。这增加了运行时开销,这意味着你只能找到你实际运行的案例,对吧?但假设你进行静态类型检查,它实际上比你当前进行的动态类型检查 更强。而且没有性能开销。这就是为什么我想做这样的事情。
顺便说一句,这实际上是一个真实的警告。我用 Sparse 输入了这个。这实际上是你将收到的警告。它说“上下文 c,第 13 行,字符 2”——碰巧是 i——“使用符号 irq——在错误上下文中不安全。” 所以它实际上为你做的事情提供了可读的警告消息。

现在它有点太受限制了。[听不清。] 所以我需要进一步改进 Sparse。
这就是我准备的所有幻灯片。
Linus 演讲的问答部分出现在第二部分。
Doc Searls 是 Linux Journal 的资深编辑,负责商业新闻报道。他在该杂志上的月度专栏是 Linux For Suits,他的双周通讯是 SuitWatch。
电子邮件:doc@ssc.com

