
ps(1) 的 GUI,使用 Mozilla 构建
Linux 的更强大功能之一是可以使用别名、shell 脚本和其他文本技巧来构建新命令的简单方式。这些技术依赖于命令行界面,但是如果您需要一个带有 GUI 界面的工具呢?既易于使用又外观专业的技术很少。本文讨论了一种很有前途的技术,该技术使用 Mozilla 平台。它着重于一个相当困难但标准的问题:如何有效地显示 ps(1) 命令传递的分层信息。需要最近版本的 Mozilla(至少 1.4)。
Linux 提供了许多 GUI 工具包,从 Xt 到 Tcl/Tk。这些工具包的教程通常从按钮示例开始。这非常例行公事,所以让我们看一下并继续前进。在 Mozilla 中,GUI 使用 XML 语法描述。一个名为 button.xul 的文档,指定一个按钮,看起来像这样
<?xml version="1.0"?> <window xmlns="http://www.mozilla.org/keymaster/ ↪gatekeeper/there.is.only.xul"> <button label="Press Me"/> </window>
不可管理的长字符串 http://www.mozilla.org/keymaster/gatekeeper/etc... 告诉 Mozilla 这个文件不是 HTML。相反,它是 XUL,一种特定于 Mozilla 的 GUI 描述语言,也是 XML 的一种方言。使用以下命令使按钮窗口出现
mozilla -chrome button.xul
这个例子很简单,不值得赘述,尽管即使对于一个简单的按钮,也有很多事情在发生。ps(1) 显示是一个更雄心勃勃的目标,所以让我们向前迈进。
不是简单的 <button> 小部件,而是需要 Mozilla 和 XUL 更强大的工具之一,<tree> 小部件。还需要一些编码和更多的 XML。这里,重点是快速开发,而不是无缝的完美。编码部分首先到来。
首先,ps(1) 执行初始数据收集。清单 1 显示了文件 psdata.ksh,模式为 777。
清单 1. ps(1) 的命令行包装器
#!/bin/ksh export COLUMNS=300 ps h -ew -o '%p,%P,%C,%x,%z,%G,%n,%U,%a' \ > /tmp/psdata
输出包含所有有趣的字段,逗号分隔,没有标题行。强制组件是 PID 和 PPID;其余的是可选但信息丰富的字段,例如 COMMAND。这就是传统 Linux 所要求的全部。
其余编码取决于 Mozilla 技术。标准编译发行版至少提供两个可执行文件,mozilla 和 regxpcom。在这里,也使用了名为 xpcshell 的二进制文件。这个二进制文件是 Mozilla 的 JavaScript 等效于 Perl 解释器;它没有 GUI 支持。xpcshell 有时是开发的良好起点,但它绝不是必需的。要获取此二进制文件,需要完整编译 Mozilla。首先,对照 www.mozilla.org/build 检查工具链要求。接下来,通过 FTP 或远程 CVS 获取源代码。建议使用主要版本而不是每夜构建版本。解包后,按照标准编译步骤
cd mozilla ./configure --disable-debug make make install
调试版本速度慢且诊断混乱;虽然无害,但这里避免使用它们。构建需要一个多小时才能完成,并且需要高达 1GB 的空间。生成的二进制文件位于 mozilla/dist/bin 中。如果 MOZILLA_FIVE_HOME 和 LD_LIBRARY_PATH 环境变量已设置并导出到该目录的绝对路径,则可以从该目录或任何位置运行它们。现在,所有必需的二进制文件和 shell 脚本都可用了。
使用 Perl,ps(1) 的输出需要被吸收到编码环境中。在这种情况下,这是一个 JavaScript 解释器。为此,您需要的不仅仅是语言语法,还需要 I/O 支持。在 Perl 中,支持内置于核心语言函数中。相比之下,JavaScript 没有 I/O 函数。在 Mozilla 中,I/O 支持是使用对象添加的。这样的对象不能来自脚本库,因为核心语言没有 I/O。因此,Perluse或require不起作用。也没有反引号操作,例如echo `pwd`。相反,Mozilla 有 XPCOM。
XPCOM 是 Microsoft COM 的实现,它可以在 Linux/UNIX、Windows 和 Macintosh 上移植运行。目前它仅限于单个进程;没有 DCOM。XPCOM/COM 是向脚本环境添加新功能的最快方法。它将编译后的(例如 C 或 C++)对象连接到脚本语言中的对象引用。最接近的 Perl 等效项是 XM,但 XPCOM 不需要 XM 所需的重新链接。Mozilla 默认包含数千个 XPCOM 对象。然而,XPCOM 不是某种 Java 虚拟机在工作。XPCOM 对象通常是编译后的代码,可以在裸机上高效运行。
在 Linux 上使用 Microsoft 的想法可能看起来很奇怪,但 XPCOM 完全是开源的,并且占据了 UNIX 中长期以来未解决的利基市场:Linux/UNIX 缺乏有用的中等规模组件模型。过去曾有 CORBA 和动态链接库,但这些东西分别是重量级的和轻量级的。XPCOM 非常适合中等规模的工作、大型二进制文件的应用程序开发以及对性能至关重要的工作。在这里,它只是非常方便。
XPCOM 或 COM 的使用通常包括多次调用 Windows QueryInterface() 方法。为了 Linux 程序员的敏感性,本文使用 createInstance() 和 getService() 代替。QueryInterface() 也可用。
回到代码。让我们吸收 ps(1) 包装器的输出。清单 2 显示了如何操作。
清单 2. 将外部数据批量加载到 xpcshell 中
const Cc = Components.classes;
const Ci = Components.interfaces;
var klass = {};
var psdata = null; // last results from ps(1).
klass.file = Cc["@mozilla.org/file/local;1"];
klass.process = Cc["@mozilla.org/process/util;1"];
klass.stream
= Cc["@mozilla.org/network/file-input-stream;1"];
klass.jsstream
= Cc["@mozilla.org/scriptableinputstream;1"];
function execute_ps() {
// freeze until ps(1) is finished.
var blocking = true, argv = [], result = {};
var path = "/home/nrm/writing/psviewer/psdata.ksh"
var file
= klass.file.createInstance(Ci.nsILocalFile);
var process
= klass.process.createInstance(Ci.nsIProcess);
file.initWithPath(path);
process.init(file);
process.run(blocking, argv,argv.length, result);
}
function read_raw_data() {
const path = "/tmp/psdata";
var mode_mask = 0x01, perm_mask = 0; // open(2)
var file
= klass.file.createInstance(Ci.nsILocalFile);
file.initWithPath(path);
var stream = klass.stream.createInstance(
Ci.nsIFileInputStream);
stream.init(file, mode_mask, perm_mask, 0);
var jsstream = klass.jsstream.createInstance(
Ci.nsIScriptableInputStream);
jsstream.init(stream);
var data = jsstream.read(file.fileSize);
// got the file content. break it down.
data = data.split("\012");
for (var i = 0; i < data.length; i++)
{
data[i] = data[i].replace(/\s*,\s*/,",");
data[i] = data[i].replace(/^\s*/,"");
psdata.push(data[i].split(","));
}
}
execute_ps();
read_raw_data();
此清单的第一部分设置了一些全局变量。Components 对象是一个预先存在的对象,它充当所有现有 XPCOM 对象(称为组件)及其支持的接口(在 Java 或 COM 意义上)的目录。要获取 XPCOM 对象,请找到正确的组件(用称为 Contract ID 的字符串命名)并为其构造一个接口对象(也用字符串或属性名称命名;此处使用后者)。重用组件很常见,因此一旦找到,它们就会作为 klass 对象上的方便属性值保存——class 是 JavaScript 中的保留字。
在此清单的末尾运行两个定义的函数。execute_ps() 只是执行另一个进程:ps(1) 包装器脚本。为此,它需要一个文件对象 (nsILocalFile) 和一个进程对象 (nsIProcess)。run() 使用 fork() 调用进程。Mozilla 被设计为可移植地完成所有这些工作,但这里仅支持 Linux,因为可执行文件的路径被硬编码为常量。另一个函数 read_raw_data() 吸收数据。Mozilla 使用与 Java 的一些高级功能相同的流、传输和通道概念,但无需编写任何类的复杂性。数据文件需要一个文件对象,该数据文件由 ps(1) 转储。流对象打开到该文件的内容路径。还需要一个小技巧:一个特殊的脚本流对象必须包装基本流。通过一次 read() 调用,整个文件被吸收到一个字符串中。接下来,一些类似 Perl 的正则表达式魔法将内容分解为行数组,然后进一步分解为数组的数组。所有数据都被视为字符串数据。要查看数据是否已正确处理,请尝试使用 xpcshell 提供的诊断和基本的 print() 方法。唉,Mozilla 目前不支持检索 PID,因此名为 /tmp/psdata.$$ 的文件尚无法工作。但是,该支持即将到来。
此脚本中有很多 XPCOM 对象,那么您如何找到正确的对象呢?与任何编程库一样,都有参考资料。在 Mozilla 源代码(或 mozilla/dist/idl 下)、Web 上查找 .IDL 文件,或阅读书籍。
脚本编写到此为止就足够了;脚本编写和表格数据在 Linux 中得到了很好的理解。要构建 GUI,Mozilla 需要 XML,特别是 XUL。这与命令行是不同的世界,您必须熟悉 XUL 才能成功。在这里,该过程被分解为简单的阶段。首先,清单 3 和图 1 显示了一个 XUL <tree> 小部件。

图 1. 带有静态 XUL 内容的简单 <tree> 小部件
清单 3. 带有静态内容的 <tree> 小部件的纯 XUL 代码
<?xml version="1.0"?>
<?xml-stylesheet
href="chrome://global/skin/global.css"
type="text/css"?>
<!DOCTYPE window>
<window xmlns="http://www.mozilla.org/keymaster/
↪gatekeeper/there.is.only.xul"
title="Process Tree">
<tree id="t1" flex="1">
<treecols>
<treecol flex="1" id="A"
label="primary column" primary="true"/>
<treecol flex="1" id="B" label="column 2"/>
<treecol flex="1" id="B" label="column 3"/>
</treecols>
<treechildren id="titems" flex="1">
<treeitem id="row1" container="true"
open="true">
<treerow>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
</treerow>
<treechildren>
<treeitem>
<treerow>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
</treerow>
</treeitem>
</treechildren>
</treeitem>
<treeitem>
<treerow>
<treecell label="Cell"/>
<treecell label="Cell"/>
<treecell label="Cell"/>
</treerow>
</treeitem>
</treechildren>
</tree>
</window>
树看起来不错,因为 <?xml-stylesheet?> 处理指令免费拖入了当前的 Mozilla 主题。使用普通的 Mozilla 可执行文件显示此树,使用 -chrome 选项移除正常的导航按钮和其他装饰
mozilla -chrome static_tree.xul
XML 内容(以下称为代码)有点像 HTML <table> 标签:同时指定列标题和数据行。<treeitem> 标签是棘手的部分;它可以包含一个 <treechildren> 标签,这允许树具有子树,而不仅仅是深度为 1 的叶节点。如图 1 所示,树小部件具有许多交互功能;子树可以像任何文件资源管理器应用程序(包括 Nautilus 或 Windows 资源管理器)一样打开和关闭。可以使用列选择器(树标题最右侧的小图标,其中包含列名称)添加或删除列。
如果我们愿意,可以使用 JavaScript 脚本将 ps(1) 数据动态插入到此 XUL 文档中。这并不难,并且所有 W3C 的 DOM 接口都可用于完成这项工作。首先添加 Element 对象,甚至使用 .innerHTML 属性。这是一篇雄心勃勃的文章,因此您将看到一种完全数据驱动的方法,该方法避免手动构建任何树。
清单 4 和图 2 显示了一个没有树的 XUL GUI。这个 GUI 有一个 <template> 标签代替

图 2. 基于静态 RDF 内容的简单模板化 GUI
清单 4. 基于简单 <template> 内容的 XUL 代码
<?xml version="1.0"?>
<?xml-stylesheet
href="chrome://global/skin/"
type="text/css"?>
<!DOCTYPE window>
<window xmlns="http://www.mozilla.org/keymaster/
↪gatekeeper/there.is.only.xul">
<description value="Before Template"/>
<vbox
datasources="trivial.rdf"
ref="urn:example:items"
containment="http://www.example.org/TestData#items"
>
<template>
<rule>
<conditions>
<content uri="?uri"/>
<member container="?uri" child="?note"/>
</conditions>
<action>
<hbox uri="?note">
<description value="Repeated content"/>
<description value="?note"/>
</hbox>
</action>
</rule>
</template>
</vbox>
<description value="After Template"/>
</window>
XUL 模板就像报表模板,而不是 C++ 模板。它是重复数据集的基础。模板以具有 datasources= 属性的 <vbox> 标签开头。<template> 的 <action> 部分是要为 <conditions> 部分在 trivial.rdf 文件中标识的每个记录重复的内容。如果您是 make(1) 或 SQL 的中级用户,或者接触过 Lisp、Scheme 或 Prolog,您应该能够掌握模板系统的工作原理。清单 5 显示了驱动图 2 显示的 trivial.rdf 文件。
清单 5. 与清单 4 模板匹配的简单 RDF 文件
<?xml version="1.0"?>
<RDF
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
>
<Description about="urn:example:root">
<T:items>
<Seq about="urn:example:items">
<li resource="urn:example:item:A"/>
<li resource="urn:example:item:B"/>
</Seq>
</T:items>
</Description>
</RDF>
如果修改此文件,图 2 可以更改,即使清单 4 没有被更改。这是一个数据驱动的安排。此文件是 RDF,是更难的 W3C 标准之一。基本上,它是一个节点图,每个节点包含三个数据项。这些项称为主体、谓词(或属性)和对象。简单的图是树,因此清单 5 是一棵树。将清单 4 中的 <hbox> 与清单 5 中的 <li> 标签组合起来,结果如图 2 所示。这有点像 SQL 连接或 join(1)。现在,请注意清单 4 中的 ref= 属性与清单 5 中的 <Seq> 标签匹配。这就是两者在 Mozilla 的模板处理逻辑中匹配的方式。Mozilla 对 RDF 的支持是基本的而不是严格的,因此几乎所有 URI 和 URL 都可以当场生成,就像它们是变量或常量一样。本文通篇都是这样做的。尝试向清单 5 添加另一个 <li> 标签;重新启动 Mozilla 并再次显示该页面。
树是显示进程分层列表的好方法,而 <template> 是直接从数据驱动树外观的好方法。但是,没有可用的 RDF 文档;相反,我们有一个 JavaScript 记录数组。解决方案是将 <tree> 和 <template> 标签放在一起,并将 RDF 文件设置为rdf:null =无文件。脚本用于直接从 JavaScript 数据创建 RDF 内容。由于 RDF 的特殊设计,内容可以随意转储到模板中,并且一切正常工作。这比从 JavaScript 手动构建 XUL 树更简洁,但无可否认也更微妙的解决方案。RDF 和模板的另一个简洁方面是树可以随时以简单的方式更新。这意味着窗口可以动态显示 ps(1) 数据,就像 GUI 版本的watch ps H正在运行一样。但是,动态步骤超出了本文的范围。
如果将 <tree> 和 <template> 标签放在一起,则最终的 XUL 文档如图 3 和清单 6 所示。
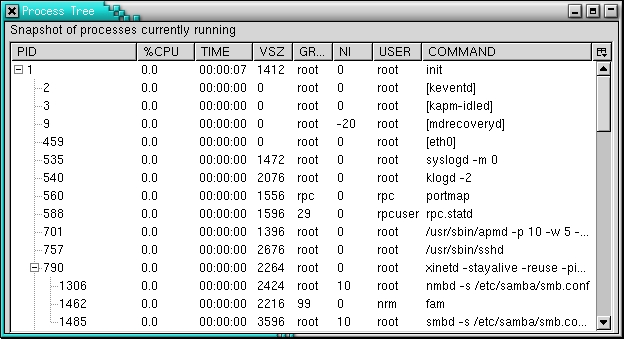
图 3. 最终的 <tree> 小部件,其 RDF 数据由 JavaScript 提供
清单 6. 基于树的 ps 数据视图的最终 XUL
<?xml version="1.0"?>
<?xml-stylesheet
href="chrome://global/skin/global.css"
type="text/css"?>
<!DOCTYPE window>
<window xmlns="http://www.mozilla.org/keymaster/
↪gatekeeper/there.is.only.xul"
title="Process Tree" flex="1">
<script src="tree.js"/>
<vbox flex="1">
<description>
Snapshot of processes currently running
</description>
<tree id="proc-tree"
flex="1"
datasources="rdf:null"
ref="http://www.example.org/ProcData#ProcList"
containment="http://www.example.org/ProcData#child"
>
<treecols>
<treecol id="pid" primary="true" label="PID"
minwidth="75"/>
<splitter class="tree-splitter"/>
<treecol id="pcpu" label="%CPU" minwidth="40"/>
<splitter class="tree-splitter"/>
<treecol id="time" label="TIME" minwidth="40"/>
<splitter class="tree-splitter"/>
<treecol id="vsz" label="VSZ" minwidth="40"/>
<splitter class="tree-splitter"/>
<treecol id="group" label="GROUP" minwidth="40"/>
<splitter class="tree-splitter"/>
<treecol id="nice" label="NI" minwidth="40"/>
<splitter class="tree-splitter"/>
<treecol id="user" label="USER" minwidth="40"/>
<splitter class="tree-splitter"/>
<treecol flex="1" id="args" label="COMMAND"
minwidth="40"/>
</treecols>
<template>
<treechildren>
<treeitem open="true" uri="rdf:*">
<treerow>
<treecell
label="rdf:http://www.example.org/ProcData#pid"/>
<treecell
label="rdf:http://www.example.org/ProcData#pcpu"/>
<treecell
label="rdf:http://www.example.org/ProcData#time"/>
<treecell
label="rdf:http://www.example.org/ProcData#vsz"/>
<treecell
label="rdf:http://www.example.org/ProcData#group"/>
<treecell
label="rdf:http://www.example.org/ProcData#nice"/>
<treecell
label="rdf:http://www.example.org/ProcData#user"/>
<treecell
label="rdf:http://www.example.org/ProcData#args"/>
</treerow>
</treeitem>
</treechildren>
</template>
</tree>
</vbox>
</window>
同样,您可以发现 datasource= 和 ref= 属性以及 <template> 标签。以 rdf: 开头的 URL 指示应将 RDF 数据放入模板的位置。在前面的示例中,变量以问号开头。有两种语法可用于标记此类位置。毫不奇怪,每列和每行都有一段这样的数据。
<splitter> 标签只是友好的装饰;它允许用户调整列的大小。这样做有助于提高可读性,minwidth= 和 flex= 属性也是如此。图 3 显示了显示的进程层次结构如何自然地填充树。
在清单 6 的顶部附近,<script> 标签包含清单 2 中的所有代码,以及更多代码。当包含此类脚本时,会立即出现安全问题。问题是 Mozilla 技术必须确保安全显示远程定位的文件和脚本,例如 HTML 页面。这类似于 Java 的 Server of Origin 规则。xpcshell 完全不安全,但主要的 Mozilla 二进制文件具有正常的安全性。通过密集的配置工作,可以克服安全限制,但将脚本注册为包更简单。为此,所有文件都必须移动到 chrome,这是 Mozilla 安装区域内的目录,其中所有安全限制都被取消。如何做到这一点将在稍后解释,但首先我们使用一个脚本完成应用程序,该脚本将 ps(1) 数据从纯 JavaScript 数据结构移动到 RDF 数据源。此脚本替换了之前使用的静态 RDF 文件(清单 7)。
清单 7. 从脚本将事实插入 RDF 数据源
// --- globals ---
klass.datasource
= Cc["@mozilla.org/rdf/datasource;1" +
"?name=in-memory-datasource"];
klass.rdf
= Cc["@mozilla.org/rdf/rdf-service;1"];
var schema = "http://www.example.org/ProcData#";
var props =
[ "pid", "ppid", "pcpu", "time", "vsz",
"group", "nice", "user", "args" ];
var rdf = klass.rdf.getService(Ci.nsIRDFService);
var root = rdf.GetResource(schema + "ProcList");
var child = rdf.GetResource(schema + "child");
var preds = [];
for (var p in props)
preds[p] = rdf.GetResource(schema + props[p]);
// --- mainline ---
window.addEventListener("load",load_handler,true);
// --- functions ---
function update_tree() {
var tree = document.getElementById("proc-tree");
// get the in-memory ds, not the rdf:localstore
var ds = tree.database.GetDataSources();
ds = ( ds.getNext(), ds.getNext() );
ds = ds.QueryInterface(Ci.nsIRDFDataSource);
var sub, pred, obj;
for (var i=0; i < psdata.length; i++)
{
if ( psdata[i][1] == "0" ) // a root node
sub = root;
else // a child node
sub = rdf.GetResource(
schema + "process-" + psdata[i][1]);
pred = child;
obj = rdf.GetResource(
schema + "process-" + psdata[i][0]);
ds.Assert(sub, pred, obj, true);
// add all properties for this process
sub = obj;
for (var j=0; j < psdata[i].length; j++)
{
pred = preds[j];
obj = rdf.GetLiteral(psdata[i][j]);
ds.Assert(sub, pred, obj, true);
}
}
}
function load_handler() {
var tree = document.getElementById("proc-tree");
var ds = klass.datasource.createInstance(
Ci.nsIRDFInMemoryDataSource);
tree.database.AddDataSource(ds);
update_tree();
}
清单 7 显示了额外的脚本逻辑,该逻辑取代了静态 RDF 文件。将 JavaScript 数据添加到树模板使用的 RDF 需要一个步骤过程。Mozilla 将 RDF 数据吸收到称为数据源的对象中。由于已指定 rdf:null,因此不存在数据源对象,因此必须创建一个并将其附加到模板。load_handler() 在文档安全加载后执行此操作。使用 onload 处理程序是标准的 HTML 技巧,此类技巧同样适用于 XUL。然后,update_tree() 函数使用模板的 RDF 内容填充该数据源。它的完成非常简单。双循环遍历 JavaScript 数组中的每个数据项。对于每个 ps(1) 进程,调用 Assert() 以创建一个 RDF 数据节点(三个项的三元组),该节点声明 PPID X 具有子 PID Y,以及另一组 RDF 节点,声明 PID X 具有 USER A 或 PID X 具有 GROUP B。<template> 和 <tree> 标签协同工作,将这些 RDF 节点自动排序为树形排列;这就像 make(1) 计算给定 Makefile 中声明的所有目标的依赖关系树一样。有了这个脚本代替静态 RDF 文件,简单的进程查看器就完成了。最后,通过将代码注册为包来解除安全限制所需的步骤是
M5H = $MOZILLA_FIVE_HOME mkdir -p $M5H/chrome/psviewer/content cp * $M5H/chrome/psviewer/content vi $M5H/chrome/psviewer/content/contents.rdf vi $M5H/chrome/installed-chrome.txt
清单 8. psviewer 包的 Chrome 注册信息
<?xml version="1.0"?> <RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#" > <Seq about="urn:mozilla:package:root"> <li resource="urn:mozilla:package:psviewer"/> </Seq> <Description about="urn:mozilla:package:psviewer" chrome:displayName="PSViewer" chrome:author="Nigel McFarlane" chrome:name="psviewer"> </Description> </RDF>
第一个 vi 编辑会话创建文件 contents.rdf。它必须看起来与清单 8 完全相同。第二个 vi 编辑会话添加到文件 installed-chrome.txt。添加一行
content,install,url,resource:/chrome/psviewer/content/
当 Mozilla 启动时,它会检查最后一个文件。如果已修改,则检查列出的目录中是否存在 contents.rdf 文件。然后读取这些文件,并且像 make(1) 一样,Mozilla 在其头部构建已知存在的所有包的图片。所有已知包都具有完全的安全访问权限,清单 8 添加了包 psviewer。现在可以使用 URL(例如
mozilla -chrome chrome://psviewer/content/tree.xul
而不是
mozilla -chrome file:///home/nrm/psviewer/tree.xul
来显示和运行安全文件。psviewer 工具在 Mozilla 安装中具有一流的状态。如有必要,它可以与其他应用程序集成,例如 Firefox/Firebird 浏览器或 Thunderbird 电子邮件客户端。它也可以添加到“工具”菜单中,例如作为菜单选项。
本文涉及很多技术。您可能犯的最大错误是尝试在您的第一个 Mozilla 实验中使用此处描述的所有功能。由于 Mozilla 中 XML 的验证不太详细,您很容易陷入困境。最好从一个简单的项目开始,逐步完成此处使用的具有挑战性的组合。虽然 ps(1) 的输出也可以制成动态 HTML 页面,但最终 XUL 是一个更强大和专业的 GUI,与桌面完全集成。
Mozilla 是一个强大的 GUI 环境,等待被探索。它很可能在 Linux 下占据与 Visual Basic 在 Windows 下相同的利基市场。更棒的是,Mozilla 是一种可移植的跨平台技术。您的项目可以设计为在 BSD、HP-UX、SunOS、AIX 和 Mac OS X 以及 Linux 上运行。
Nigel McFarlane 是一位自由科学和技术作家,具有丰富的编程背景。他的最新著作是 Rapid Application Development with Mozilla,ISBN 0131423436。通过 nrm@kingtide.com.au 联系他。
