
OSCAR 和生物信息学
OSCAR(开源集群应用程序资源)项目已经存在大约四年了。最初的概念是在 2000 年 1 月提出的,第一次组织会议在同年 4 月举行。该小组认识到集群组装是耗时且重复的。因此,该项目的目标是创建一个工具包来自动化这个过程。通过这样做,该小组希望扩大集群的使用范围,并使其适应学术界和私营部门。
OSCAR 项目由咨询小组 OCG(开放集群组)监督,这是一个开放会员制的非正式小组。OCG 致力于使集群计算对于高性能计算 (HPC) 研究和开发更实用。该小组与 OSCAR 项目一样,由来自研究/学术界以及行业的代表指导。该小组的主要成员包括 Bald Guy Software、BC 基因组科学中心、戴尔、印第安纳大学、英特尔、路易斯安那理工大学、橡树岭国家实验室、Revolution Linux 和舍布鲁克大学。
OSCAR 是 OCG 的工作组之一。其他项目包括 HA-OSCAR(高可用性)、Thin-OSCAR(无盘)和 SSS-OSCAR(可扩展系统软件)。要了解有关 OCG 及其项目的更多信息,请参阅本文的在线资源。
OSCAR 的第一个版本于 2001 年 4 月发布,此后我们发布了两个主要版本。我们的发布周期通常与每年 11 月举行的超级计算大会同期。截至撰写本文时,当前版本为 3.0,我们的目标是在 SuperComputing04 之前发布 4.0 版本。
OSCAR 的目标是为用户提供安装、编程和维护 HPC 集群的最佳实践。许多开源组件在 HPC 环境中单独运行良好,但需要特定的设置程序。OSCAR 充当粘合剂,将所有这些组件集成在一起,以提供一个可用的工具包。该项目的目标是中型集群(50+ 节点集群)。社区反馈表明,这种规模代表了当今组装的大多数集群。
OSCAR 具有以下组件
管理:系统安装套件 (SIS)、集群命令和控制 (C3) 以及 OPIUM(用户管理)。
HPC 工具:并行编程库:MPICH、LAM/MPI 和 PVM;批处理系统:OpenPBS/MAUI、Torque 和 SGE;监控工具:Ganglia 和 Clumon;以及其他第三方 OSCAR 软件包。
核心基础设施/管理:OSCAR 数据库 (ODA) 和 OSCAR 软件包下载器 (OPD)。
OSCAR 开发人员分散在不同的地理位置,每周都会安排电话会议来讨论正在进行的开发问题。该小组还会举行年度大会,集思广益,为未来的版本添加新功能。每年还会举办一次研讨会,通常与 HPCS(高性能计算系统和应用国际研讨会)联合举办,鼓励用户提交关于他们使用 OSCAR 的经验以及与 HPC 相关的其他开发工作的论文。第二届年度 OSCAR 研讨会于 2004 年 5 月在加拿大温尼伯举行,会议记录现已发布。
生物信息学是生物学和计算机科学/IT 的结合,是一个快速发展的领域,在 HPC 世界中具有很高的地位。简单来说,生物信息学关注的是使用计算机算法和系统来分析生物数据,例如 DNA、RNA、蛋白质和调控元件。
生物数据主要是字符串序列。分析通常是字符串操作,这使得 Perl 成为大多数生物信息学家选择的编程语言。许多开源 Perl 程序员为 Bioperl 项目做出了贡献,这是一个专门用于执行生物信息学分析的 Perl 模块库。Java 用于更大的项目,通常用于涉及图形界面的项目。Python 正在该领域获得强大的立足点,因为越来越多的程序员了解到这种相对较新但功能强大的编程语言的易用性和高可读性。
Linux 集群在生物信息学界非常流行,因为很多分析往往是长时间运行且重复的。Linux 集群非常适合运行这种令人尴尬的并行作业,这些作业可以彼此独立执行。这些不被认为是真正的并行程序,因为它们不需要 MPI 等并行编程库。生物信息学通常在集群上执行,包括在不同的输入上运行多个脚本和算法,并且可以在不同的 CPU 上执行,每个 CPU 都有自己的地址空间。
使用 OSCAR 工具包安装集群是一个简单的过程。如果您以前安装过 Linux,您应该不会遇到太多麻烦。
目前,OSCAR 项目支持三个 Linux 发行版:Red Hat 8.0、Red Hat 9.0 和 Mandrake 9.0。主要的 Linux 安装要求是安装了 X 窗口环境,例如 KDE 或 GNOME;否则,典型的带有软件开发工具的工作站安装应该就足够了。
在头节点上安装和配置 Linux 后,您可以从项目页面下载 OSCAR tarball,解压它并执行 configure、make、make install 例程。
默认情况下,OSCAR 安装在 /opt/oscar 中。您可以使用 configure 的 --prefix 标志更改此设置。安装 OSCAR 后,您可以启动 OSCAR 向导,该向导提供逐步安装菜单,用于设置您的集群。
要调用向导,请转到 /opt/oscar 并键入./install_cluster ethX。这里,ethX 指的是集群网络上的接口。
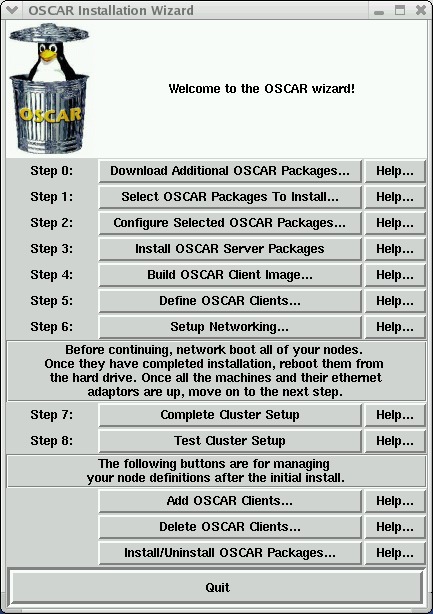
图 1. OSCAR 安装主菜单。在不到十个步骤中,集群就可以进行计算了!
OSCAR 附带了许多预捆绑的软件包。来自各种存储库的其他软件包也可能令人感兴趣。要下载这些软件包,只需单击 OSCAR 向导中的“下载其他 OSCAR 软件包”并选择软件包即可。
接下来,您可以选择要安装的软件包。软件包有三个主要类别:核心、已提供和第三方。核心软件包必须安装,并且无法取消选择。已提供的软件包是 OSCAR 团队建议您安装的软件包,而第三方软件包是存储库中提供的所有剩余软件包。
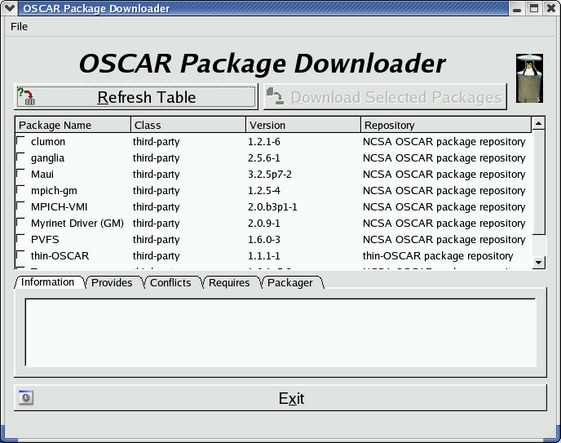
图 2. OSCAR 软件包下载器——可以在此菜单中下载其他软件包。
可以使用“配置选定的 OSCAR 软件包”菜单对软件包进行配置更改。
下一个阶段是安装 OSCAR 服务器软件包。这是非交互式的,基本上设置了服务器上使用的软件包。完成后,弹出窗口会提醒您。
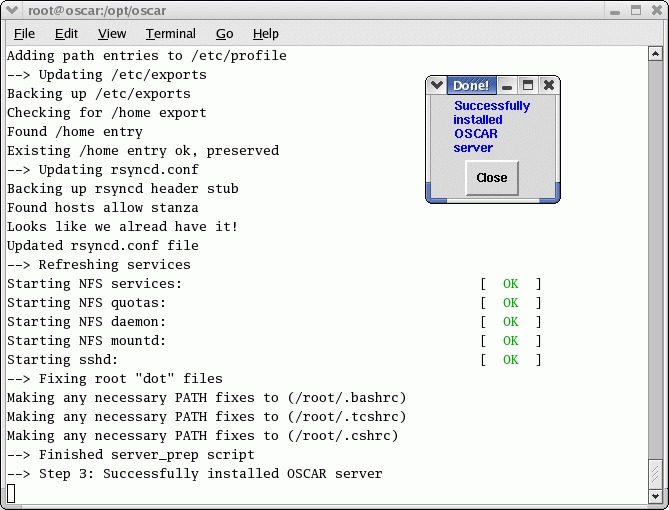
图 3. 非交互式步骤,服务器软件包在此处安装。
现在有趣的部分开始了。您可以使用“构建 OSCAR 客户端镜像”步骤构建客户端镜像。在此步骤中,您可以为要构建的客户端镜像选择一些选项。然后,此镜像将推送到您的客户端节点。您可以提供要在基本镜像上安装的 RPM 软件包列表,还可以决定如何对硬盘进行分区和分配 IP 地址。最后,您可以选择镜像后的操作,例如在镜像完成后重新启动计算机。

图 4. 基于用户提供的软件包列表和分区表创建客户端镜像。
在“定义 OSCAR 客户端”步骤中,您可以指定域名、客户端的基本名称、您希望在此会话中启动的节点数量以及其他网络设置。单击“添加客户端”按钮后,这些定义将被配置,集群几乎可以部署了。

图 5. 集群节点和网络设置在此处定义。
接下来,您将需要为您的集群设置网络。在这里,您可以使用 PXE 或软盘启动客户端节点,然后 OSCAR 头节点收集 MAC 地址,您可以将它们分配给特定的主机。完成此操作后,客户端节点将立即进行镜像。通常,镜像每个节点需要 10-30 分钟,具体取决于您的硬盘速度。部署集群时,可以同时镜像多个节点。我们通常一次启动十个节点进行镜像,这样头节点就不会负载过重。使用这种交错的方法,您应该能够在一个小时内部署一个 64 节点集群。
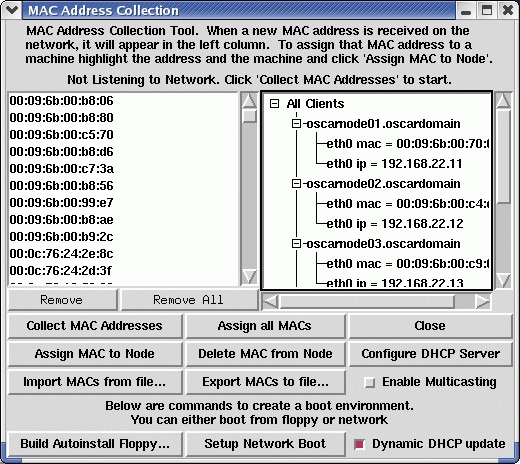
图 6. 集群节点通过网络启动,其 MAC 地址分配给主机条目。
在节点镜像并重新启动后,您可以继续下一步,即完成集群设置。这又是一个非交互式步骤,其中执行最终安装配置和其他清理功能。
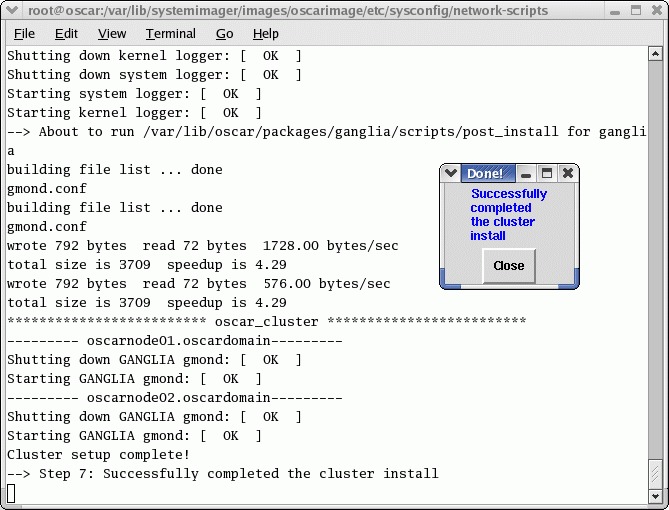
图 7. 非交互式步骤,其中执行最终安装配置和清理功能。
最后,您可能需要测试集群设置。这将运行一系列集群安装以及各个软件包的测试。如果一切顺利,您将通过所有测试,从而确认您的集群设置已完成并准备好运行计算。
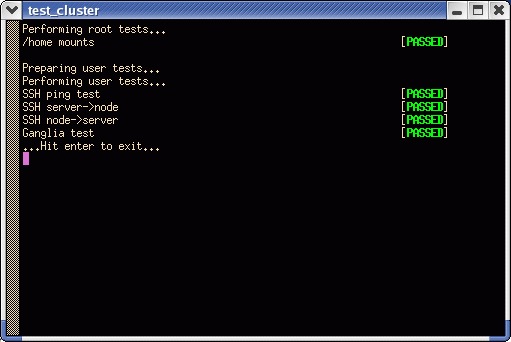
图 8. 一切就绪——集群已准备就绪,可以开始运行了。
OSCAR 工具包易于安装,通常适用于大多数硬件。但是,如果您遇到问题,可以使用两个邮件列表寻求帮助。oscar-users 列表是您应该首先提问的地方。大多数核心团队成员经常阅读该列表,其他用户也会提供帮助。但是,如果您对 OSCAR 的开发有疑问,可以使用 oscar-devel 列表。这两个列表都是封闭列表;您需要先订阅才能向其发布内容。
我们计划在此即将发布的版本中包含各种功能。它们分为四个主要类别:NEST、节点组、Linux 发行版和 SIS。
NEST(节点事件和同步工具)用于确保 OSCAR 软件包与其集中存储的配置在所有集群节点上同步。目前,当您安装新的集群节点时,OSCAR 和所有软件包的 post_install 脚本都必须在所有集群节点上运行,而不管它们是否需要运行。尽管此模型在中等规模上运行良好,但显然它施加了可扩展性限制。NEST 最大的变化是软件包配置将从服务器拉取,而不是推送到客户端。操作只会在必要时执行,这比我们目前采用的暴力执行方案更优雅。
节点组是集群中节点的任意分组。借助此新功能,可以为这些组选择性地安装和管理 OSCAR 软件包。在即将发布的版本中,我们计划仅支持服务器和客户端节点组。但是,将来将允许用户定义自己的组。
定义 OSCAR 的关键功能之一是我们对多个 Linux 发行版的支持。在新版本中,我们希望引入对 Fedora Core 2 和 3、Red Hat Enterprise Server 3.0 和 Mandrake 10 的支持。支持这些发行版还将引入对 IA-64 和 x86-64 架构的支持。
系统安装套件 (SIS)(包括 SystemImager)是执行 OSCAR 系统镜像部署的程序集合。有两个主要的 SIS 相关改进。首先是磁盘类型自动检测。传统上,OSCAR 集群镜像的创建考虑了一种类型的硬盘(IDE 或 SCSI)。使用此 OSCAR 特定的补丁程序,只要基本硬件相似,您就可以使用相同的镜像部署到具有不同类型硬盘的不同机器上。
其次,提供了一个工具,以便用户可以使用特定的内核模块来启动节点进行镜像。有时,较新的硬件很难与 OSCAR 一起使用,因为 SIS 内核启动镜像没有受支持的驱动程序。借助此工具,您可以使用具有已知工作模块的现有内核作为 SIS 启动内核,并使用它来启动您的客户端节点,以便可以对其进行镜像。此功能将包含在下一个 SystemImager 开发版本中,我们希望将其包含在 OSCAR 4.0 中。
OSCAR 为常用的集群感知应用程序提供软件包。它们只是带有相应元文件和安装脚本的 RPM 软件包。这些软件包由 OSCAR 核心团队和软件包作者创建和维护。如果您想在集群上安装某个应用程序,但未在 OPD(OSCAR 软件包下载器)中找到它,请为其创建一个软件包。OSCAR 团队欢迎贡献,甚至可能托管您可能创建的 OSCAR 软件包。该团队也向软件开发人员发出此邀请。
OSCAR 软件包驻留在软件包存储库中,这些存储库是由软件包作者提供的分散式 Web 空间,用于托管软件包文件。这些存储库的 URI 存储在主存储库列表中。
创建 OSCAR 软件包通常是一个简单的过程。如果 RPM 已准备就绪,您已经完成了一半。剩下的就是创建一些文件来存储有关软件包/RPM 的元数据,以及一些脚本来传播整个集群的配置文件。这相对容易做到,因为可以对 OSCAR 集群做出某些假设。
但是,如果当前没有可用的 RPM 软件包,则需要在继续之前以 RPM 格式打包应用程序。创建 RPM 可能容易也可能不容易,具体取决于应用程序的复杂性。您需要创建一个 spec 文件并使用源 tarball 构建 RPM 和相应的 SRPM。
基因组科学中心 (GSC) 推出的第一个 OSCAR 软件包是 Ganglia,一个集群监控系统。我们已经开始开发我们的第二个软件包,它是 Sun Microsystems 赞助的开源批处理调度系统 Sun Grid Engine。这应该在稍后从 GSC OSCAR 存储库的 OPD 获得。
最常用的生物信息学程序是 BLAST,一种序列比对/搜索工具。使用多个基因序列查询基因数据库非常适合并行化;将此问题拆分为多个子作业非常容易,每个子作业使用一组输入查询数据库。存在为您执行此类数据库/查询拆分的解决方案,最值得注意的是开源 mpiBLAST 以及 Paracel 的商业版本。并行化版本的 BLAST 扩展性非常好,但是,当然,当添加更多节点只会因在多个节点上启动单独且较小的作业的开销而不会提高性能时,就会达到一个点。
FPC 是我们大量使用的另一个应用程序,用于组装、编辑和查看基于指纹的物理图谱。此应用程序的原始并行化版本是在 GSC 开发的,但它没有批处理系统感知能力。我们最近已将并行 FPC 与 Sun Grid Engine 集成,以便用户可以轻松请求特定数量的节点来运行此应用程序。
我们还在开发一个名为 Chinook 的对等应用程序,用于共享生物信息学服务。目前,它仍在开发中,我们正在努力将其与我们的集群集成。这将来可能会连接网格,并提供 Globus 工具包的替代方案。
目前,我们的 200 节点集群正被大量用于发现和分类人类基因组中的调控元件。人类基因组由大约 30,000 个基因组成,我们正在使用不同的算法扫描每个基因。基因被分组为 1,500 个批次,在 Opteron 2.0GHz 机器上,典型的运行大约需要四天时间。如果没有集群技术,这种研究是不可能实现的。
自 OSCAR 工具包的第一个版本以来,它已经走过了漫长的道路。越来越多的人发现它易于使用和部署——这是集群技术得到更广泛采用的关键。生物信息学将继续随着高性能计算而发展。很快,面向生物信息学界的集群工具包可能会变得更加普及——一种解决方案,其中包括运行并行生物信息学应用程序的所有工具,并且易于安装和部署。
作者要感谢 Mark Mayo、Asim Siddiqui 和 Steven Jones,感谢他们给予他机会在 GSC 的 Linux 集群上工作,并感谢他们确定 OSCAR 是要使用的工具。作者还要感谢 OSCAR 核心团队、开发人员和用户,感谢他们创建了一个伟大的社区来分享 HPC 知识和信息。最后,但并非最不重要的一点,感谢 NCSA 的人们为 OSCAR 项目贡献了大量的时间和精力。特别感谢 Jeremy Enos、Ren�Warren 和 Martin Krzywinski 为本文提供了宝贵的意见和建议。
本文资源: /article/7760。
Bernard Li 是加拿大 Michael Smith 基因组科学中心的高性能计算专家。他花费时间管理 Linux 集群基础设施并将生物信息学应用程序与集群集成。他是 OSCAR 的核心开发人员,也是 Sun Grid Engine 的粉丝。可以通过 bli@bcgsc.ca 联系他。




