
内核角落 - HTB 队列规则分析
分层令牌桶 (HTB) 队列规则是 Linux 流量控制功能集的一部分,它提供 QoS 功能,可用于微调 TCP 流量。本文简要概述了队列规则组件,并描述了几个初步性能测试的结果。在 Linux 环境中设置了几个配置场景,并使用 Ixia 设备生成流量。该测试表明,吞吐量精度可以被控制,并且带宽范围在 2Mbit/s 范围内是准确的。测试结果证明了 HTB 队列算法的性能和准确性,并揭示了改进流量管理的方法。
流量控制机制在 IP 数据包被排队等待在输出接口上传输之后,但在数据包实际被驱动程序传输之前发挥作用。图 1 显示了流量控制决策相对于物理以太网和传输层协议(如 UDP 和 TCP)上的数据包传输的制定位置。
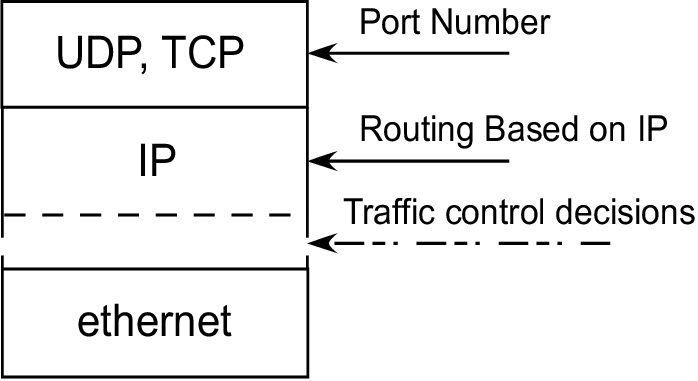
图 1. 内核在数据包排队等待传输后做出流量控制决策。
流量控制内核功能,如 Alexey Kuznetsov 在 Linux 中实现的,包括四个主要组件:队列规则、服务类别、过滤器和策略。
队列规则是定义用于处理排队 IP 数据包的算法的软件机制。每个网络设备都与一个队列规则相关联,典型的队列规则使用 FIFO 算法来控制排队的数据包。数据包按照接收顺序存储,并以与队列关联的设备可以发送的速度排队。Linux 目前支持各种队列规则,并提供了添加新规则的方法。
有关队列算法的详细描述,请访问互联网上的“Iproute2+tc Notes”(请参阅在线资源)。HTB 规则使用 TBF 算法来控制为与其关联的每个定义的服务类别排队的数据包。TBF 算法提供流量策略和流量整形功能。有关 TBF 算法的详细描述,请参阅 Cisco IOS Quality of Service Solutions Configuration Guide(请参阅“Policing and Shaping Overview”)。
服务类别定义策略规则,例如最大带宽或最大突发,并使用队列规则来强制执行这些规则。队列规则和服务类别是紧密相关的。服务类别定义的规则必须与预定义的队列相关联。在大多数情况下,每个服务类别都拥有一个队列规则,但也可能多个服务类别共享同一个队列。在大多数数据包排队的情况下,特定服务类别的策略组件会丢弃超过一定速率的数据包(请参阅“Policing and Shaping Overview”)。
过滤器定义了队列规则使用的规则。队列规则反过来使用这些规则来决定需要将传入的数据包分配到哪个服务类别。每个过滤器都有一个分配的优先级。过滤器根据其优先级按升序排序。当队列规则有数据包需要排队时,它会尝试将数据包与定义的过滤器之一匹配。搜索匹配项时,将使用列表中的每个过滤器,从分配优先级最高的过滤器开始。每个服务类别或队列规则可以有一个或多个与之关联的过滤器。
策略组件确保流量不超过定义的带宽。策略决策是基于过滤器和服务类别定义的规则做出的。图 2 显示了 Linux 流量控制机制中所有组件之间的关系。
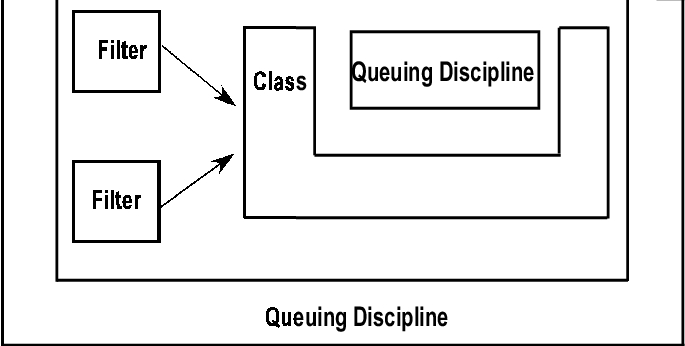
图 2. Linux 流量控制机制包括队列规则、服务类别、过滤器和策略。
TC 是一个用户级程序,用于创建队列、服务类别和过滤器,并将它们与输出接口关联(请参阅资源中的“tc—Linux QoS 控制工具”)。过滤器可以基于路由表、u32 分类器和 TOS 分类器进行设置。该程序使用 netlink 套接字与内核的网络系统功能进行通信。表 1 列出了三个主要功能及其对应的 TC 命令。有关 TC 命令选项的详细信息,请参阅 HTB Linux Queuing Discipline User Guide。
HTB 机制提供了一种控制给定链路上出站带宽使用的方法。要使用 HTB 功能,应将其定义为服务类别和队列规则类型。HTB 基于 TBF 算法对流量进行整形,该算法不依赖于底层带宽。只有根队列规则应定义为 HTB 类型;所有其他服务类别实例都使用 FIFO 队列(默认)。排队过程始终从根级别开始,然后根据规则决定哪个服务类别应接收数据。遍历服务类别树,直到找到匹配的叶子服务类别(请参阅“Hierarchical Token Bucket Theory”)。
为了测试 HTB 的准确性和性能,我们使用了以下网络设备:一台 Ixia 400 流量生成器,带有一个 10/100 Mbps 以太网负载模块 (LM100TX3) 和一台运行 2.6.5 Linux 内核的 Pentium 4 PC(1GB RAM,70GB 硬盘)。设计了两个测试模型,一个用于测试策略准确性,另一个用于测试带宽共享。
第一个模型(图 3)用于测试特定定义服务类别的策略准确性。Ixia 机器中的端口 1 生成从一个或多个流发送到 IP 192.168.10.200 的流量。Linux 机器将数据包路由到接口 eth0(静态路由),然后将它们发送回 Ixia 机器上的端口 2。所有流量控制属性都在 eth0 接口上定义。所有分析均基于端口 2(Ixia 机器)上捕获的流量结果完成。
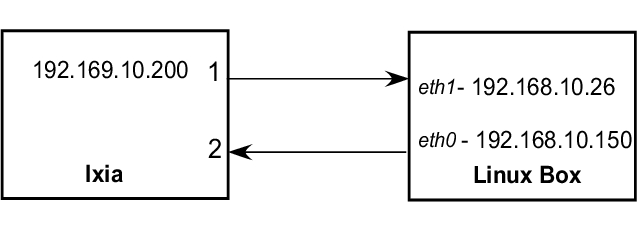
图 3. 测试模型 #1 配置
第二个模型(图 4)用于测试来自同一服务类别的两个流的带宽共享方式。在这种情况下,使用了另外两个 Ixia 端口来传输数据。
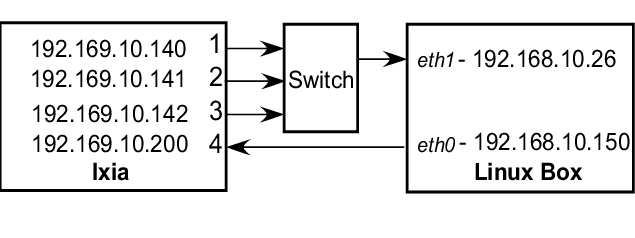
图 4. 测试模型 #2 配置
Ixia 机器中的端口 1、端口 2 和端口 3 生成发送到 IP 192.168.10.200 的流量,每个端口使用一个流。Linux 机器基于静态路由将这些数据包路由到接口 eth0,然后将它们发送回 Ixia 机器上的端口 2。流量控制属性在 eth0 接口上定义。所有分析均基于端口 2(Ixia 机器)上的流量结果捕获完成。
在所有测试中,发送端口都在指定的带宽上发送连续的数据包突发。Ixia 10/100 Mbps 以太网负载模块(型号 LM100TX3)有四个独立的端口,每个端口最多可以发送 100Mbit/s。Ixia 负载模块支持在一个端口中生成多个流,但有一个限制:它无法将流混合在一起,并且一次只能服务一个流。存在此限制的原因是调度器以轮询方式工作。它从流 X 发送一个字节突发,移动到下一个流,然后从流 Y 发送一个字节突发。
为了从一个流生成特定的带宽,该流是一个端口中定义的一组流的一部分,必须对 Ixia 机器的配置的特定属性进行微调。需要微调的属性及其定义如下
突发:每个流发送的数据包数量,然后移动到服务下一个流。
数据包大小:流发送的数据包的大小。
总带宽:所有流使用的总带宽。
有关 Ixia 配置详细信息,请参阅表 2。
目标是确定适当的突发大小,以实现每个流所需的生成带宽。由于所有三个流都使用同一物理线路,因此在线路上发送的数据方式类似于图 5 中的图示。
图 5. 从 Ixia 机器发送到正在测试的 Linux 系统的数据。
以下等式定义了属性之间的关系

表 3 解释了等式中使用的变量。
表 3. 属性关系等式中使用的变量
| 属性 | 定义 |
|---|---|
| Tc | 发送突发 1-i 所需时间的总和(秒)(Tc1 + Tc2 + Tc3+...)。 |
| Bs-i | 流 i 的突发中的数据包数量。 |
| Ps-i | 流 i 发送的数据包的大小。 |
| Tb | 所有流发送的总带宽(比特/秒)。 |
| Nc | 一秒钟内 Tc 突发的数量。 |
| Bn-i | 流 i 的请求带宽(比特/秒)。 |
假设所有流的数据包大小都相同,如示例中所示,则剩余的计算是突发大小的计算。
由于所有流共享相同的带宽,因此可以通过检查请求带宽之间的比率来找到请求的突发值,使用等式 Bs-i = Bn-i。但是,此数字可能异常大,因此可以将其除以直到获得合理的值。为了为每个流定义不同的数据包大小,可以更改突发大小值,直到为每个流获得所需的带宽。电子表格程序简化了多个带宽的计算。
在定义 HTB 配置时,使用了 tc class 命令的以下选项以实现所需的结果
rate = 服务类别可以在不从其他服务类别借用带宽的情况下使用的最大带宽。
ceiling = 服务类别可以使用的最大带宽,它限制了服务类别可以借用的带宽量。
burst = 在移动到服务下一个服务类别之前,可以以 ceiling 速度发送的数据量。
cburst = 在移动到服务下一个服务类别之前,可以以线路速度发送的数据量。
互联网世界中的大多数流量都是由 TCP 生成的,因此包括代表数据报大小的数据包大小,例如 64 (TCP Ack)、512 (FTP) 和 1,500,用于所有测试用例。

图 6. 测试 1:一个流输入,一个流输出
表 4. 测试模型 1 的结果
| 突发(字节) | Cburst(字节) | 数据包大小(字节) | 输入带宽(Mbit/s) | 输出带宽(Mbit/s) |
|---|---|---|---|---|
| 默认 | 默认 | 128 | 40 | 33.5 |
| 默认 | 默认 | 64 | 40 | 22(Linux 停止) |
| 默认 | 默认 | 64 | 32(最大) | 29.2 |
| 15k | 15k | 64 | 32(最大) | 30 |
| 15k | 15k | 512 | 32 & 50 & 70 | 25.3 |
| 15k | 15k | 1,500 | 32 & 50 & 70 | 25.2 |
| 18k | 18k | 64 | 32(最大) | 29.2 |
| 18k | 18k | 512 | 32 & 50 & 70 | 30.26 |
| 18k | 18k | 1,500 | 32 & 50 & 70 | 29.29 |
从表 4 中的结果可以得出以下结论
Linux 机器可以转发(在一个接口上接收并在另一个接口上传输)连续的 64 字节数据包的最大带宽约为 34Mbit/s。
给出最平均准确度结果的 burst/cburst 值是 18k/18k。
在突发值和请求速率值之间存在线性关系。这种关系在整个测试中变得明显。
输出接口上推送的带宽量不影响结果的准确性。
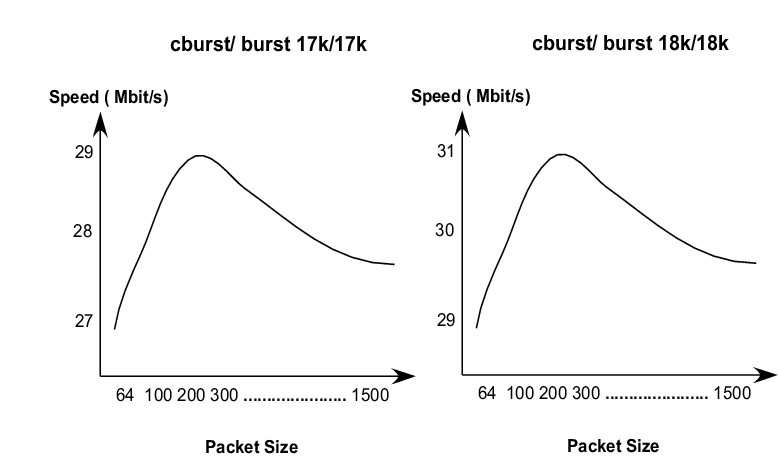
图 7. 数据包大小与输出带宽的图形分析
图 7 说明了在测试各种数据包大小后数据包大小与输出带宽之间的关系。从表 4 和图 7 中的结果,我们可以得出两个结论:吞吐量精度可以通过更改 cburst/burst 值来控制,并且当使用 64 到 1,500 字节之间的数据包大小时,精度带宽范围大小为 2Mbit/s。为了验证 burst/cburst 值和速率带宽之间是否存在线性关系,测试了多个突发和 cburst 值。表 5 显示了测试用例中抽样数据的很大一部分。
表 5. Burst/Cburst 和速率值之间的关系
| 突发(字节) | Cburst(字节) | 数据包大小(字节) | 输入带宽(Mbit/s) | 输出带宽(Mbit/s) | 分配速率(Mbit/s) |
|---|---|---|---|---|---|
| 9k | 9k | 64 | 32 | 17.5 | 15 |
| 9k | 9k | 512 | 32 | 15.12 | 15 |
| 9k | 9k | 1,500 | 32 | 15.28 | 15 |
| 4.8k | 4.8k | 64 | 32 | 8.96 | 8 |
| 4.8k | 4.8k | 512 | 32 | 8.176 | 8 |
| 4.8k | 4.8k | 1,500 | 32 | 8 | 8 |
| 3k | 3k | 64 | 32 | 17.5 | 15 |
| 3k | 3k | 512 | 32 | 15.12 | 15 |
| 3k | 3k | 1,500 | 32 | 15.28 | 15 |
18k/18k 值用作起点。burst/cburst 值是通过使用公式 cburst/burst (Kbytes) = 18/(30M/分配速率) 获得的。从表 5 中的结果来看,可以为速率值动态定义 cburst/burst 值,例如在假设线性关系时。

图 8. 测试 2:三个流输入,一个流输出
表 6. 测试 2 结果
| 流 | 突发(字节) | Cburst(字节) | 数据包大小(字节) | 输入带宽(Mbit/s) | 输出带宽(Mbit/s) | 服务类别 |
|---|---|---|---|---|---|---|
| 1 | 17k | 17k | 64 | 15 | 12.7 | 3 |
| 2 | 17k | 17k | 512 | 20 | 17.1 | 3 |
| 3 | 1k | 1k | 512 | 4 | 2.01 | 2 |
| 总计 | 18k | 18k | – | 39 | 31.8 | – |
表 6 显示了一个继承级别的示例。服务类别 2 和服务类别 3 从服务类别 1(30Mbit/sec)继承速率限制规范。在此测试中,子服务类别的速率上限等于父服务类别的速率限制,因此服务类别 2 和服务类别 3 最多可以借用 30Mbit/sec。线性关系假设用于计算所有服务类别的 cburst/burst 值,基于其期望带宽。
表 6 描述了线性关系在一个继承级别的情况下是如何工作的。在此测试中,输入流传输 39Mbit/s 的连续流量,累积输出带宽为 31.8Mbit/s。
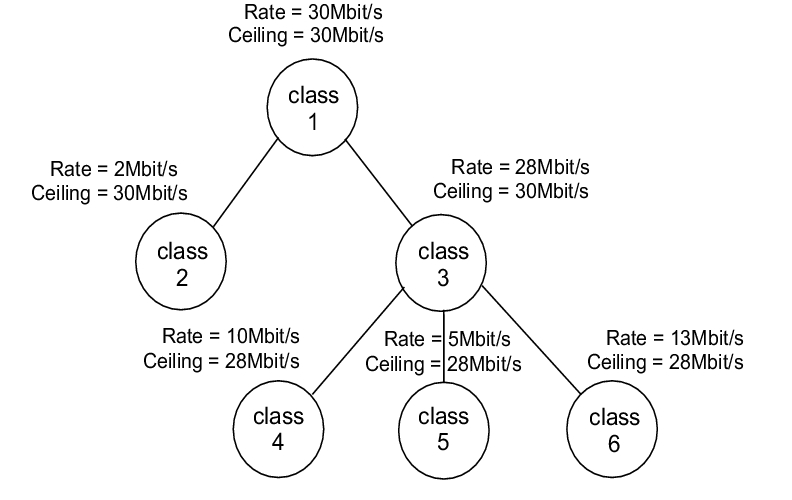
图 9. 测试 3:四个流输入,一个流输出
表 7. 测试 3 结果
| 流 | 突发(字节) | Cburst(字节) | 数据包大小(字节) | 输入带宽(Mbit/s) | 输出带宽(Mbit/s) | 服务类别 |
|---|---|---|---|---|---|---|
| 1 | 1k | 1k | 512 | 5 | 2.04 | 2 |
| 2 | 6k | 6k | 6 | 15 | 11.326 | 4 |
| 3 | 3k | 3k | 64 | 10 | 5.67 | 5 |
| 4 | 7.8k | 7.8k | 512 | 20 | 13.02 | 6 |
| 总计 | 18k | 18k | – | 50 | 32.05 | – |
表 7 显示了两个继承级别的情况。服务类别 2 和服务类别 3 从服务类别 1(30Mbit/s)继承速率限制规范。服务类别 4、5 和 6 从服务类别 3(28Mbit/s)继承速率限制,并基于其自身的速率限制规范共享该速率限制。在此测试中,子服务类别的速率上限等于父服务类别的速率限制,因此服务类别 4、5 和 6 最多可以借用 28Mbit/s。线性关系假设用于计算所有服务类别的 cburst/burst 值,基于其期望带宽。
从表 7 的结果可以看出,线性关系在两个继承级别的情况下是有效的。在此测试中,输入端口传输 50Mbit/s 的连续流量,累积输出带宽为 32.05Mbit/s。

图 10. 测试 1:三个流输入,一个流输出
表 8. 测试 1 结果
| 流 | 突发(字节) | Cburst(字节) | 数据包大小(字节) | 输入带宽(Mbit/s) | 输出带宽(Mbit/s) | 服务类别 |
|---|---|---|---|---|---|---|
| 1 | 1k | 1k | 512 | 5 | 0.650 | 2 |
| 2 | 1k | 1k | 512 | 5 | 0.600 | 2 |
| 3 | 1k | 1k | 512 | 5 | 0.568 | 2 |
| 总计 | 18k | 18k | – | 15 | 1.818 | – |
如表 8 所示,当多个流传输相同数量的字节并属于同一服务类别时,带宽会均匀分配。另一个测试,其中流 1 中的输入带宽高于流 2 和流 3 的输入带宽,结果表明流 1 的输出带宽也高于流 2 和流 3。从这些结果可以得出结论,如果在特定流上发送更多数据,则该流能够比同一服务类别内的其他流转发更多数据包。
此处介绍的测试用例演示了一种评估 HTB 准确性和性能的方法。虽然特定速率下的连续数据包突发不一定模拟真实世界的流量,但它确实为定义 HTB 服务类别及其关联属性提供了基本指南。
以下陈述总结了测试用例结果
Linux 机器可以转发(在一个接口上接收并在另一个接口上传输)连续的 64 字节数据包的最大带宽约为 34Mbit/s。此上限出现的原因是 Ethernet 驱动程序接收或传输的每个数据包都会生成中断。中断处理占用 CPU 时间,因此会阻止系统中其他进程正常运行。
当将流量速率设置为 30Mbit/s 时,给出最平均准确度结果的 cburst/burst 值是 18k/18k。
突发值和请求速率之间存在线性关系。30Mbit/s 速率的 cburst/burst 值可以用作计算其他速率的突发值的起点。
可以通过更改 cburst/burst 值来控制吞吐量精度。对于 64–1,500 字节数据包大小,精度带宽范围大小约为 2Mbit/s。
当多个流传输相同数量的字节并属于同一服务类别时,带宽会均匀分配。
Yaron Benita 来自以色列耶路撒冷,目前居住在加利福尼亚州旧金山。他是 Prediwave 的 CMTS 软件经理。他主要在网络和嵌入式领域工作。他已婚,并有一个可爱的六个月大的女儿。可以通过 yaronb@prediwave.com 或 ybenita@yahoo.com 与他联系。
