
通过进程同步提高 HPC 系统上的应用程序性能
人们会期望将应用程序可用的处理能力翻倍会使应用程序性能翻倍,或者将运行时间缩短一半。不幸的是,HPC 用户知道这远非事实,实际性能效率降至仅为系统理论峰值性能的 5%。HPC 研究人员和应用程序开发人员已经花费并将继续花费大量精力来寻找这些性能损失的根源并提高持续的应用程序性能。当我们着手开发 Cray XD1 系统时,我们加入了研究人员的行列,共同解决这个问题。本文介绍了我们如何向前辈学习,以及如何在此知识的基础上开发一种新的基于 Linux 调度的解决方案,该解决方案有望显着提高 Linux HPC 系统上的实际应用程序性能。
大多数研究都集中在 HPC 应用程序本身的结构上。各个研究团队试图提高缓存的效率,寻找方法来最大限度地减少处理器间通信,并探索各种类似的措施,但每种策略仅提供百分之几的性能提升。然而,另一个研究领域显示出特别的希望。通过了解 HPC 应用程序和系统后台进程之间的交互,可以找到修改这种交互以提高性能的方法。
在一篇开创性的论文中,洛斯阿拉莫斯国家实验室的研究人员 Petrini、Kerbyson 和 Paking 记录了他们对这种交互的研究(请参阅在线资源),量化了由他们认为的“噪声”(大型多进程 MPI 作业和后台进程之间的交互)导致的应用程序性能损失。他们观察到,内务处理任务或噪声延迟了单个处理器到达 MPI 屏障(应用程序中的同步点),并导致所有其他处理器等待,直到一个处理器完成其内务处理。这导致所有其他处理器上的周期浪费。
图 1 的上半部分说明了这种交互以及它如何导致性能损失。图中所示的进程是并行作业的一部分,每个进程在单独的处理器上运行,并定期通过使用 MPI 屏障进行同步。在计算的第一部分中,进程 1 被延迟,因为节点的调度程序暂停进程执行以运行后台进程,例如在每个 Linux 或 UNIX 节点上找到的那些进程。进程 2 和 3 也被延迟。这种模式的重复导致持续的应用程序性能显着降低。影响的大小是遇到屏障的频率和处理器数量的函数。
Petrini 及其同事在他们的 HPC 系统 ASCI Q 上运行可压缩欧拉流体动力学代码 SAGE 时,量化了这种性能损失。ASCI Q 是一个由 2,048 个 HP ES45 节点组成的集群,其中每个节点都是一个四路 SMP。Petrini 等人观察到,当他们将 SAGE 限制为仅在 SMP 中的四个处理器中的三个上运行时,当使用超过 256 个节点时,获得了更好的性能。他们推测,此结果是由后台噪声引起的,并且通过消除许多噪声源并观察性能的提高,验证了该理论。
这项研究表明,进程同步的缺乏和等待时间是罪魁祸首,它剥夺了细粒度和高度并行的 HPC 应用程序高达 50%(甚至更多)的潜在性能。不幸的是,阻止这种盗窃的方法仍然没有出现。Petrini 等人用来识别罪魁祸首的方法(限制系统运行内务处理任务的自由)对于大多数 HPC 应用程序来说并不是一个实用的解决方案。将 HPC 系统上四分之一的处理器降级为运行内务处理任务的前景对于许多 HPC 站点来说是不可接受的。此外,许多后台进程无法删除,从而限制了使用此方法可实现的性能提升。
当我们开始构建新的高性能计算机时,我们也开始寻找一种方法来防止这种性能盗窃。我们考虑了一种新方法,即使用 Linux 调度程序来同步 MPI 作业和内务处理任务的调度。之前的工作和我们的研究表明,这种新的同步调度方法可以为在 32 个或更多处理器上运行的许多细粒度并行应用程序带来 50% 或更高的性能提升。
我们的方法是创建一个新的 Linux 调度策略。为了实现预期的收益,此策略必须同步 Linux HPC 系统中所有节点上的调度程序,以确保 MPI 进程在所有进程上同时运行,并且 Linux 内务处理进程同时执行。因此,调度程序必须有一种实现全局同步的方法,如图 1 所示。为了实现全局同步,我们在通信处理器中设计了一个功能,以同步每个处理节点中的时钟。
新的 Linux 调度程序策略定义了一个 128 个时隙的调度帧,其中 120 个时隙保留用于应用程序执行,8 个时隙保留用于内务处理进程。不同处理器上的调度程序能够通过利用全局同步时钟来对齐其调度帧,这保证了系统中节点之间的时间变化小于亚微秒。在任何时刻,所有处理器要么正在执行 HPC 应用程序,要么正在运行内务处理进程(图 1 的下半部分)。
这种进程同步方法可扩展到高处理器计数,因为调度决策是在每个节点本地做出的。这通过消除在屏障处等待造成的 CPU 周期浪费,显着提高了持续的应用程序性能。
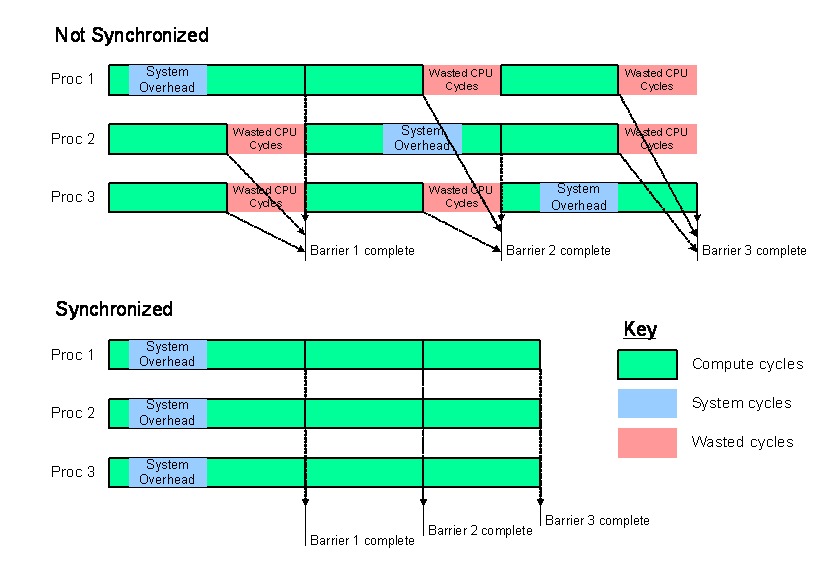
图 1. 进程异步和同步执行的示例
同步调度程序作为一种新的策略实现,增强了与 Linux 内核关联的调度程序中的三个现有策略。当正在执行的进程被阻塞或自愿放弃 CPU 时、当处理器接收到中断时或在 10 毫秒时间片结束时,将调用 Linux 调度程序。调度程序根据适用于该进程的调度策略及其优先级选择要运行的下一个进程。在新的同步策略到位后,Linux 然后从以下调度策略中选择一个,两个用于实时处理,两个用于传统的时分共享进程,按优先级降序排列
FIFO(先进先出):标记为 FIFO 的进程一直运行,直到它放弃对 CPU 的控制。此优先级用于短时间、实时系统进程。FIFO 进程先于其他进程运行。
轮询:使用此策略的进程依次接收 10 毫秒的时间片。它可用于实时处理。
同步:我们添加了同步策略,以实现多处理器批处理作业中进程的同步调度。工作负载管理系统在启动每个进程时将其标记为使用此策略。这些进程及其后代获得了同步调度的好处。
优先级:优先级调度是 Linux 用户熟悉的时分共享机制。使用此调度策略的进程具有与其关联的优先级,并接收与其优先级成比例的时间。所有用户进程和几乎所有系统进程都在此策略下运行。调度程序从具有最高优先级的策略类中选择要运行的下一个进程。FIFO 和轮询系统进程首先运行。标记为同步调度的进程在使用正常优先级调度程序的进程之前运行。
新的同步调度策略创建了一个调度帧,该帧指示何时执行批处理作业以及其他用户和系统进程。该帧包括预定义数量的时隙,这些时隙按顺序循环。一个时隙代表 10 毫秒(Linux 中的一个系统定时器滴答),在此期间执行分配给该时隙的进程。当前的实现有 128 个时隙,120 个用于执行批处理作业,8 个用于其他进程。在后者的时隙期间,同步调度策略指示没有可运行的批处理进程,并且传统的优先级调度策略接管所有其他内务处理进程。当不存在批处理作业时,Cray 调度程序的行为与传统的 Linux 调度程序没有区别。
调度帧中的时隙数是可配置的,但它必须是 2 的幂。为批处理与其他进程保留的时隙的比例也可以调整。图 2 说明了一个典型的调度帧,其中批处理时隙的位置以红色显示,内务处理时隙以灰色显示。
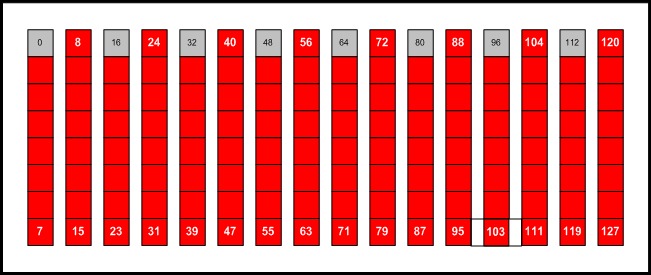
图 2. 具有八个保留时隙的时隙(128 个)
当节点上启动第一个批处理进程时,将创建调度帧。所有批处理时隙都分配给该进程。创建其他批处理进程会导致时隙在进程之间均匀分布。如果创建了 n 个批处理进程,则第一个批处理进程接收前 120/n 个时隙,第二个接收接下来的 120/n 个时隙,依此类推。因此,同步调度程序能够支持每个 CPU 上需要多个进程的批处理作业。
批处理进程执行到其分配的时间结束,只要它不进行任何阻塞或 CPU 屈服的系统调用即可。如果批处理进程屈服于 CPU,可能是由于进行阻塞系统调用而导致的,则会调度另一个批处理进程运行。如果没有可运行的批处理进程,则控制权传递给传统的优先级调度程序以运行内务处理进程。当然,如果批处理进程因中断处理而被解除阻塞,则它们将重新获得 CPU。
到目前为止,我们只讨论了单个节点内批处理作业和系统进程的调度。但是,为了阻止性能盗窃,这种同步调度程序必须跨所有处理器工作。在这里,我们遇到了一个关键的系统设计标准,它使这种同步调度程序方法成为可能——全局时间同步的可用性。在我们的设计中,全局时间同步由 HPC 系统内设计的通信处理器执行。这些处理器从应用程序处理器卸载通信处理。通信处理器还运行时间同步协议以实现全局时钟同步。可以实现严格的时间同步,因为通信处理器可以控制数据包调度和抖动——任何一对处理器之间的时间差小于 1 微秒。将时间同步委托给通信处理器的另一个优点是,此负载从执行应用程序工作负载的处理器中移除,从而为应用程序处理留出更多时间,并进一步减少对应用程序处理器的中断。
时间同步协议包括用于时隙对齐的附加字段。该协议使用主从范例,其中一个节点充当时间和时隙信息的源,系统中的所有其他节点都将其自身同步到主节点的时钟。从主节点接收的时间同步数据包标识正在执行的时隙以及自时隙开始以来经过的时间,从而可以在整个 HPC 系统中精确对齐调度帧。
这种同步调度程序提供并行应用程序中进程的同步执行。可以避免多少性能下降或可以获得多少潜在性能取决于应用程序使用屏障和/或集体操作的频率、系统内务处理进程花费的时间以及应用程序使用的处理器数量。
我们的研究表明可以实现显着的加速。图 3 和图 4 显示了通过使用同步调度程序相对于传统优先级调度程序可以实现的理论加速。图 3 假设后台处理需要 1.5% 的 CPU,图 4 假设后台处理消耗了 6.25% 的 CPU——这是大多数集群上的实际指标。曲线显示了应用程序平均每秒遇到 100、200 和 300 个屏障的情况。
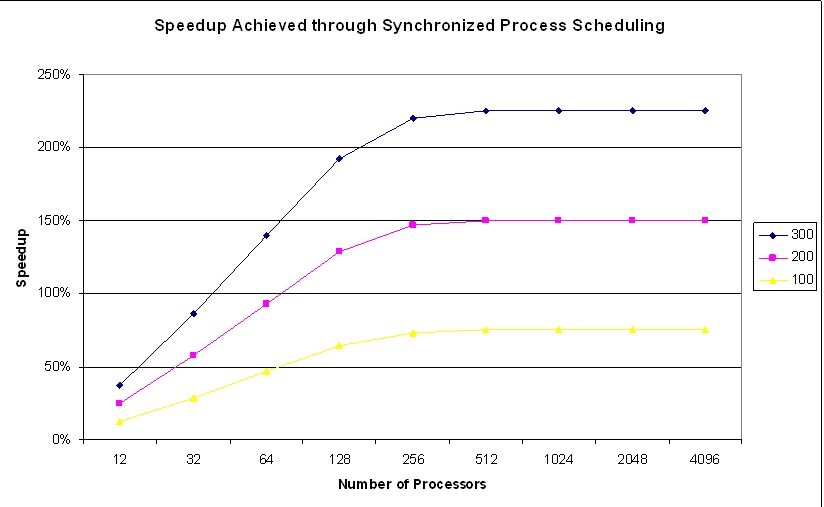
图 3. 进程同步在守护进程 CPU 利用率为 1.5% 时的理论加速
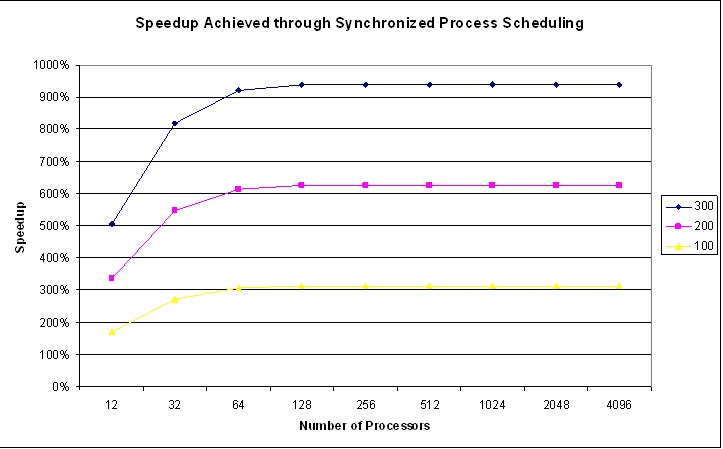
图 4. 进程同步在守护进程 CPU 利用率为 6.25% 时的理论加速
随着处理器数量的增加,来自同步调度程序的性能增益会增加,并渐近线地接近最大值。这反映了性能不会继续随着传统调度程序而下降的事实。在达到一定的处理器数量后,至少一个处理器被内务处理延迟的可能性增加到 100%。添加更多处理器不会显着增加在屏障处遇到的应用程序延迟。
通过关注 HPC 应用程序和系统后台进程之间的交互,HPC 研究人员发现了并行应用程序性能损失的主要罪魁祸首。其他研究确定了防止这种盗窃的方法,但迄今为止还没有一种方法提供成功的实际应用。使用 Linux 调度程序的全局进程同步消除了由于噪声引起的等待时间,并有望显着提高性能。通过超越应用程序并深入了解 HPC 系统其余部分的作用,我们相信我们已经找到了可扩展的实际应用。借助使用全局时钟同步的 Linux 进程同步和在每个处理节点上运行的 Linux,Cray 实现确保应用程序进程在所有处理器上同时运行,并且内务处理在所有处理器上同时执行并在时间上受到限制。我们的进程同步解决方案可以防止性能盗窃,并将运行在 32 个或更多处理器上的细粒度高度并行应用程序的应用程序性能提高高达 50%。
本文资源: /article/7756。
Paul Terry 博士是 Cray Canada, Inc. 的首席技术官,该公司前身为 OctigaBay Systems,于 2004 年 4 月被 Cray 收购。他是创新计算架构的技术战略家,负责确立公司的技术愿景和领导地位。
Amar Shan,Cray, Inc. 产品管理总监,负责将 Cray 的前沿技术创新和创造性业务解决方案推向市场。他在计算和电信行业的产品管理、开发和架构角色方面拥有 20 多年的经验。
Pentti Huttunen,Cray, Inc. 的基准测试专家,负责研究并行计算技术并优化应用程序,以确保它们在 Cray, Inc. 的各种平台上高效运行。




