
应用定义处理器
应用定义处理器基于可重构计算 (RC) 的概念。RC 是一种计算技术,它模糊了软件和硬件之间的界限,并为在降低功耗和空间需求的同时提供高性能的下一个重大进步奠定了基础。RC 是使用可以重新配置的硬件设备实现的。RC 系统中的处理器被创建为针对在其上执行的应用程序进行优化的硬件。
本文解释了 RC, بررسی实现了 RC 的 SRC 系统,并展示了 RC 相对于传统微处理器提供的性能优势。我们还将探讨 RC 的编程模型,并讨论 RC 为支持开放硬件提供的潜力。
RC 是一种基于硬件的计算形式,可以为将在其上运行的每个应用程序动态创建。RC 硬件由芯片组成,这些芯片的逻辑是动态定义的,而不是在芯片制造时定义的。RC 已经存在多年,并在许多不同的硬件组件中实现,例如现场可编程门阵列 (FPGA)、现场可编程对象阵列 (FPOA) 和复杂可编程逻辑器件 (CPLD)。对于应用程序开发人员而言,重要的是今天的可重构芯片具有时钟频率和容量,这使得使用 RC 硬件进行大规模计算成为可能。
用于实现 RC 的最熟悉的芯片类型是 FPGA。FPGA 是一种由 SRAM 存储单元组成的芯片,用于定义芯片的配置。FPGA 包含逻辑门、触发器、RAM、算术内核、时钟和可配置的导线以提供互连。FPGA 可以配置为实现任何任意逻辑功能,因此,可以用于创建可以针对应用程序优化的自定义处理器。
因此,一组 FPGA 可以配置为 MIPS、SPARC、PowerPC 或 Xeon 处理器,或者您自己设计的处理器。实际上,处理器甚至不必是指令处理器。它可以是直接执行逻辑 (DEL) 处理器,其中仅包含计算逻辑,而无需指令来定义算法。
DEL 处理器在高性能方面具有巨大潜力。DEL 处理器可以使用执行特定算法所需的精确资源来创建。传统的指令处理器具有固定的资源、加法器、乘法器、寄存器和缓存,并且需要大量的芯片面积和处理能力来实现开销操作,例如指令解码和排序以及缓存管理。
DEL 处理器是为每个应用程序创建的可重构计算机,这与固定架构的微处理器(一种尺寸适合所有情况)形成对比。DEL 处理器为任何特定应用程序提供最有效的电路,这体现在功能单元的精度和算法中可以找到的并行性方面。由于是可重构的,因此可以在不到一秒的时间内为每个应用程序创建一个独特的 DEL 处理器。
但是,您为什么要关心可以为应用程序动态创建 DEL 处理器,并且它比微处理器更有效地利用其芯片?答案很简单:性能和功率效率。可以创建一个 DEL RC 处理器,它具有算法中存在的所有并行性,而没有微处理器中存在的开销。对于本文的其余部分,RC 处理器假定使用 FPGA 实现,以便在讨论中更具体。
RC 处理器的性能来自逻辑的并行执行。RC 处理器是完全并行的。实际上,构建给定算法逻辑的任务是协调并行执行,以便在正确的时间瞬间创建、通信和保留中间结果。
DEL 处理器被构建为功能单元的网络,这些功能单元与数据路径和控制信号连接。网络中的每个计算元素在每个时钟脉冲下都变为活动状态。图 1 显示了用于计算表达式的逻辑片段,并对比了芯片的利用率与冯·诺依曼指令处理器(如英特尔奔腾 4 微处理器)的利用率。
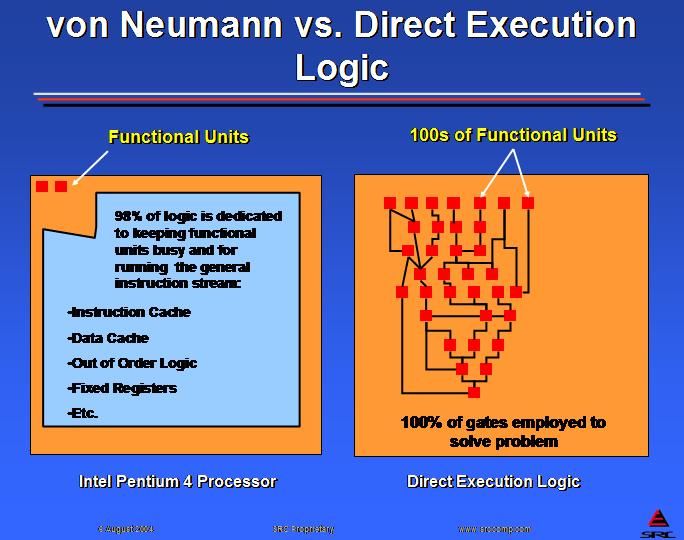
图 1. 直接执行逻辑可以将所有逻辑门用于实际问题。
即使微处理器可以在 3GHz 的时钟频率下运行,而 FPGA 芯片在 100–300MHz 的频率范围内运行,但 DEL 处理器上的并行性和内部带宽可以使交付的性能比微处理器高出几个数量级。图 2 显示了 SRC 的 DEL 处理器 MAP 和典型的冯·诺依曼指令处理器(英特尔 Xeon 2.8GHz 微处理器)之间的一些基准测试比较。精确所需数量的功能单元的并行执行、高内部带宽、消除指令处理开销以及消除加载/存储都有助于克服 MAP 和英特尔微处理器之间 30 倍的时钟频率差异。
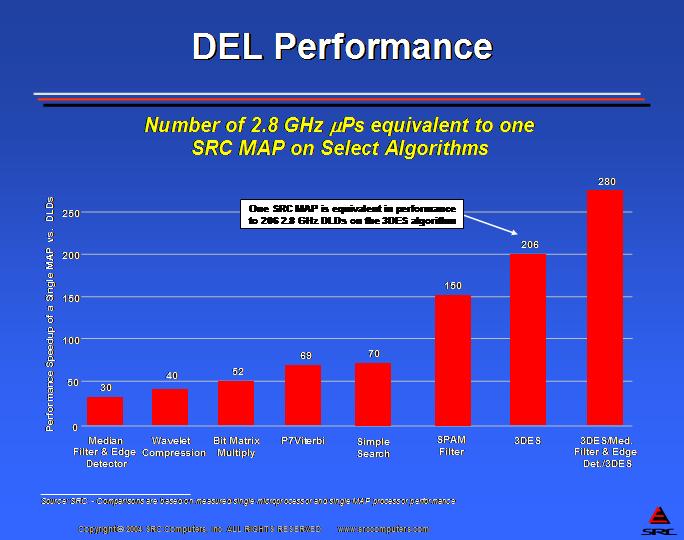
图 2. 达到与 MAP 直接执行逻辑处理器相同性能所需的 2.8GHz 微处理器的数量。
基于 DEL 的处理器可以运行 Linux,但是它们需要运行吗?Linux 内核中的代码段肯定可以从在 DEL 处理器上运行中获益,并且 Linux 发行版中的应用程序也可以获得更高的性能。但是,操作系统的作用,特别是内核的作用,是管理硬件,以便应用程序达到其所需的性能水平。换句话说,OS 应该不妨碍应用程序消耗硬件。
应用程序不仅仅进行密集的计算。它们与用户交互、读取和写入文件、显示结果以及通过互联网连接与世界通信。因此,应用程序既需要计算资源,也需要操作系统的服务。具有高并行性的繁重计算受益于 DEL 处理器。虽然串行代码可以作为 DEL 运行,但最好在传统的微处理器中提供服务。
对于运行大多数应用程序的硬件来说,最佳组合是微处理器和 DEL 处理器的混合。这种组合允许应用程序在标准的 Linux 环境中(具有所有 OS 服务和熟悉的支持工具)运行时,仍能获得几个数量级的性能提升。应用程序中主要是顺序的部分或需要 OS 服务的部分可以在系统的传统微处理器部分中运行,而受益于 DEL 并行性的应用程序甚至 OS 的部分可以在紧密耦合的 DEL 处理器上运行。
SRC 创建了由 DEL 处理器和微处理器组成的系统。SRC 系统运行 Linux 作为 OS,提供了一个名为 Carte 的编程环境,用于创建由微处理器指令和 DEL 组成的应用程序,并在单个系统中支持微处理器和 DEL 处理器硬件。
获得专利的 MAP 处理器是 SRC 的高性能 DEL 处理器。MAP 使用可重构组件来完成控制和用户定义的计算、数据预取和数据访问功能。这种计算能力与非常高的板上和板外互连带宽相结合。MAP 的多个双端口板上内存库提供 11.2GB/秒 的本地内存带宽。MAP 配备了单独的输入和输出端口,每个端口都支持 1.4GB/秒 的数据有效负载带宽。每个 MAP 还具有两个通用 I/O (GPIO) 端口,为直接 MAP 到 MAP 连接或数据源输入提供 4.8GB/秒 的额外数据有效负载。图 3 显示了 MAP 处理器的框图。
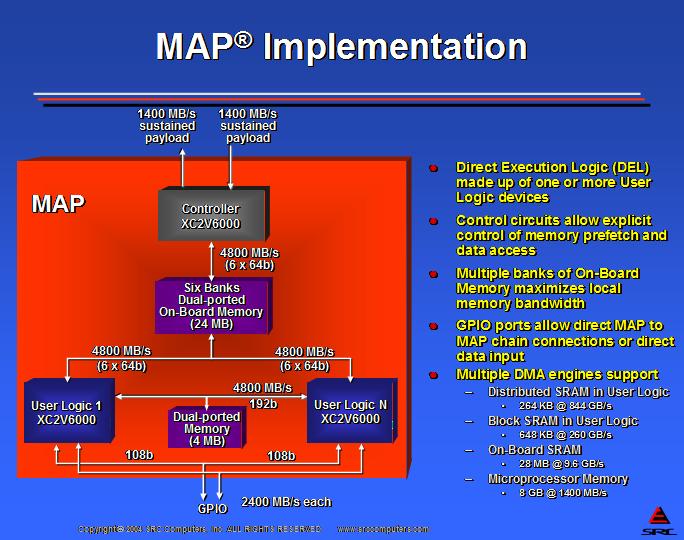
图 3. MAP 框图
这些产品中使用的密集逻辑器件 (DLD) 是双处理器英特尔 IA-32 系列微处理器。这些第三方商品板随后配备了 SRC 开发的 SNAP 接口。SNAP 允许商品微处理器板连接到构成 SRC 系统其余部分的 MAP 和公共内存节点,并与之共享内存。
SNAP 接口旨在直接插入微处理器的内存子系统,而不是其 I/O 子系统,从而使 SRC 系统能够维持显著更高的互连带宽。SNAP 使用单独的输入和输出端口,每个端口当前都支持 1.4GB/秒 的数据有效负载带宽。
SNAP 上的智能 DMA 控制器能够执行复杂的 DMA 预取和数据访问功能,例如数据打包、跨步访问和分散/聚集,以最大程度地提高系统互连带宽的有效利用率。对于这些操作,互连效率通常比使用相同互连的基于缓存的微处理器高十倍以上。
SNAP 可以直接连接到单个 MAP,也可以连接到 SRC 的 Hi-Bar 交换机,以实现对多个 MAP、微处理器或公共内存的系统范围访问。
系统级配置实现 MAPstation 集群或基于交叉开关的拓扑结构。如图 4 所示,基于集群的系统利用先前在直接连接配置中讨论的微处理器和 DEL 处理器。虽然这种拓扑结构确实具有微处理器-DEL 处理器的亲和力,但它也具有使用基于标准的集群技术来创建非常大的系统的优势。
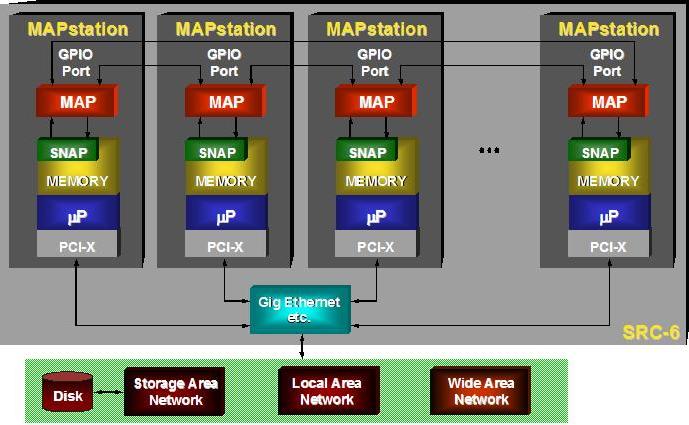
图 4. 集群式 SRC-6 系统框图
当需要更高的灵活性时,可以使用基于 Hi-Bar 交换机的系统。Hi-Bar 是 SRC 专有的可扩展、高带宽、低延迟交换机。每个 Hi-Bar 支持 64 位寻址,并具有 16 个输入和 16 个输出端口以连接到 16 个节点。微处理器、MAP 和公共内存节点都可以以任何配置连接到 Hi-Bar,如图 4 所示。每个输入或输出端口支持 1.4GB/秒 的屈服数据有效负载,每个 16 个端口的聚合屈服二等分数据带宽为 22.4GB/秒。端口到端口的延迟为 180 纳秒,每个端口都实现了单错误纠正和双错误检测 (SECDED)。
Hi-Bar 交换机也可以在多层配置中互连,允许两层支持 256 个节点。每个 Hi-Bar 交换机都安装在 2U 高、19 英寸宽的机架式机箱中,以及其电源和冷却解决方案,以便轻松包含到基于机架的服务器中。
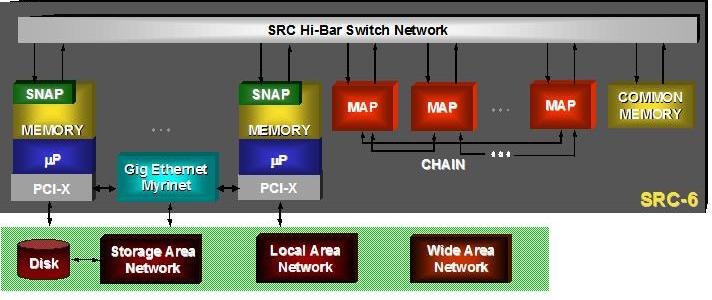
图 5. 带 Hi-Bar 交换机的 SRC-6 框图
使用 Hi-Bar 交叉开关互连的 SRC 服务器除了微处理器和 MAP 之外,还可以包含公共内存节点。这些公共内存节点中的每一个都包含一个智能 DMA 控制器和高达 8GB 的 DDR SDRAM。SRC-6 MAP、SNAP 和公共内存节点 (CM) 支持系统中所有内存的 64 位虚拟寻址,从而允许在应用程序中使用单个平面地址空间。每个节点都以 1.4GB/秒 的屈服数据有效负载带宽支持内存读取和写入。
CM 的智能 DMA 控制器能够执行复杂的 DMA 功能,例如数据打包、跨步访问和分散/聚集,以最大程度地提高系统互连带宽的有效利用率。对于这些操作,互连效率通常比使用相同互连的基于缓存的微处理器高十倍以上。
此外,SRC 公共内存节点还具有专用的信号量电路,所有 MAP 处理器和微处理器也可以访问该电路以进行同步。
传统上,RC 的编程模型一直是硬件设计模型。鉴于 RC 的底层 FPGA 技术所需的工具都是来自电子设计自动化行业的逻辑设计工具,因此实际上并没有软件开发人员可以识别的编程环境。这些工具支持硬件定义语言 (HDL),例如 Verilog、VHDL 和原理图捕获。
随着片上系统 (SOC) 技术的引入以及与如此复杂性的硬件定义相关的复杂性,高级语言已开始可用。Java 和类 C 语言越来越常用于编程 RC 芯片。这是向前迈出的重要一步,但仍然需要应用程序程序员进行相当大的飞跃。
SRC 编程模型是传统的软件开发模型,其中 C 和 Fortran 用于编程 MAP 处理器,并且任何能够与运行时库(用 C 编写)链接的语言都可以编译并在系统的微处理器部分上运行。
SRC Carte 编程环境的创建基于这样的设计假设,即应用程序程序员将编写应用程序并将其移植到 RC 平台。因此,设计、使用高级语言 (HLL) 编写代码、编译、通过标准调试器调试、编辑代码、重新编译等等的标准开发策略,直到正确为止,都用于为 SRC-6 系统开发。仅当应用程序在微处理器环境中正确运行时,才重新编译该应用程序并将其定向到 DEL 处理器 MAP。
在 RC 系统中编译到硬件需要两个编译步骤,这对于指令处理器编程来说非常陌生。HLL 编译器的输出必须是硬件定义语言。在 Carte 中,输出是 Verilog 或电子设计交换格式 (EDIF)。EDIF 文件是硬件定义对象文件,用于定义将在 RC 芯片中实现的电路。如果生成 Verilog,则必须使用 Verilog 编译器(例如 Synplicity 的 Synplify)将该 HDL 合成到 EDIF。
最后一步,布局和布线,采用 EDIF 文件的集合,并在 RC 芯片上创建电路的物理布局。此过程的输出文件是配置位流,可以将其加载到 FPGA 中以创建正在编程到 RC 处理器中的算法的硬件表示。
Carte 编程环境执行从 C 或 Fortran 到 FPGA 位流的编译,而无需程序员参与。它进一步将面向微处理器的代码编译为对象模块。Carte 的最后一步是创建统一的可执行文件,该文件将微处理器对象模块、MAP 位流和所有必需的运行时库合并到单个 Linux 可执行文件中。图 6 和图 7 显示了 Carte 编译过程。
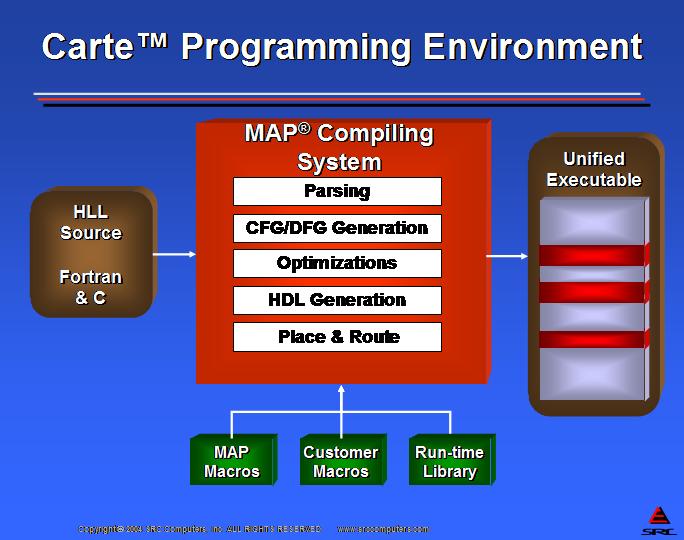
图 6. Carte 编程环境
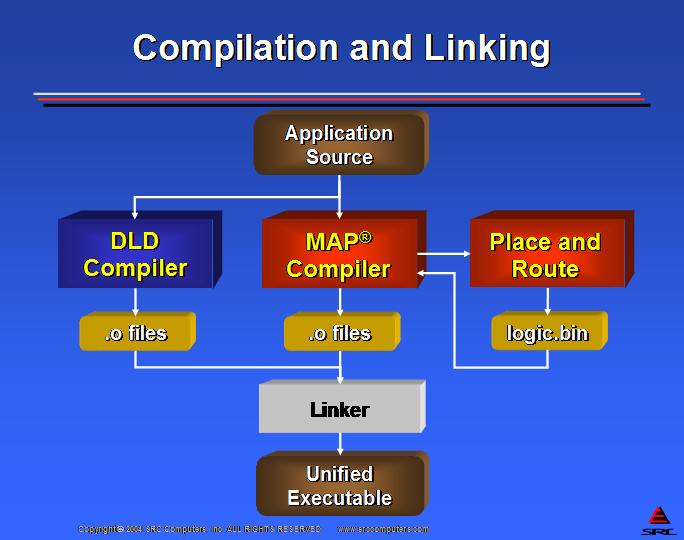
图 7. Carte 编译
Linux 在开源运动中发挥了主导作用并从中受益匪浅,在开源运动中,一大批敬业的软件开发人员以商业组织无法比拟的速度、质量和创新水平创建、修改和改进了 Linux 内核和 OS。可重构计算有可能在硬件设计中实现这种创新和技术进步。本文的大部分内容都在解释应用程序程序员编写代码并使用标准编程方法来创建特定于应用程序的硬件的概念,而无需硬件设计知识。但是,在 RC 中,应用程序程序员创建的生成硬件的构建块是功能单元。功能单元是基本的计算单元,例如加法器、浮点乘法器或三角函数。功能单元也可以是专用高性能单元,例如三重 DES 函数,或非标准精度算术单元,例如 24 位 IEEE 浮点运算符。
功能单元由逻辑设计师创建。RC 编译器(例如 SRC 的 Carte MAP 编译器)能够允许将客户提供的功能单元添加到编译器支持的标准操作集中。当向应用程序程序员提供新的和新颖的功能单元时,可以实现更高的性能水平。
正是在功能单元的创新硬件设计创建和共享中,开源硬件运动可以为计算科学带来实质性进步。在开源领域看到的创新和生产力可以作为开源硬件进行复制。
RC 为更多有创意的设计师提供了创建可供应用程序开发人员使用的新颖硬件的途径。通过 Opencores.org 等组织,可以共享和改进功能单元设计。由于开源软件,计算科学领域取得了重大进展,通过专注于开源硬件的运动也很容易看到这一点。
为了展示 DEL 处理器的性能优势,本文提供了一个字符串匹配示例。这些示例的代码可在 Linux Journal FTP 站点上找到—请参阅在线资源。此示例来自 Christian Charras 和 Thierry Lecroq 的网站,NIST 算法和数据结构词典引用了该网站。为了进行比较,为 2.8GHz 英特尔 Xeon 通过英特尔的 Linux 版 C++ 8.0 编译器实现了 Brute Force 和 Boyer-Moore 字符串匹配算法。Brute Force 算法是使用 Carte 1.8 编程环境为 SRC 系统实现的。Brute Force 算法是模式和文本字符串之间直接的字符到字符比较。Boyer-Moore 被认为是最高效的字符串匹配算法。该示例采用随机生成的 20MB 文本字符串,并搜索六个和十个随机生成的模式。编译使用 -O3 优化设置完成,性能比较如表 1 所示。向测试中添加四个额外的搜索模式会增加微处理器时间,但由于流水线逻辑,对 MAP 执行时间没有影响。虽然 Xeon 以 2.8GHz 运行,而 MAP 以 100MHz 运行,但 DEL 中看到的并行性可以在 MAP 中实现 99 倍的性能优势。此示例需要 MAP 中一个 FPGA 的 60%。双芯片编译将提供超过 200 倍的性能。
表 1. 字符串匹配性能
| 实现 | 文本大小 | 模式 | 搜索时间 | 加速 |
|---|---|---|---|---|
| Brute Force (Xeon) | 20MB | 6 | 0.827 秒 | 1.00× |
| Boyer-Moore (Xeon) | 20MB | 6 | 0.597 秒 | 1.38× |
| Brute Force (MAP) | 20MB | 6 | 0.0143 秒 | 57.75× |
| Brute Force (Xeon) | 20MB | 10 | 1.398 秒 | 1.00× |
| Boyer-Moore (Xeon) | 20MB | 10 | 1.051 | 1.33× |
| Brute Force (MAP) | 20MB | 10 | 0.0141 秒 | 98.81× |
为了演示在流水线循环中添加额外计算的影响,以及引入自定义功能单元的能力,进行了第二个性能比较,其中将 DES 加密的字符串传递到搜索例程。必须先解密字符串,然后才能搜索。在 MAP 实现的情况下,引入了 DES 流水线功能单元。Verilog 定义是从 Opencores.org 获得的,并引入到搜索循环中。由于循环是流水线的,因此它继续每个时钟周期交付一组结果。因此,包括 DES 解密的 20MB 文本搜索的经过时间与单独搜索的时间相同。这导致了比微处理器实现高出 232 倍的惊人加速。十模式 MAP 示例仅使用 FPGA 的 74%,因此 MAP 的双芯片编译将产生 460 倍。
表 2. 搜索加密字符串的性能
| 实现 | 文本大小 | 模式 | 搜索时间 | 加速 |
|---|---|---|---|---|
| DES-Brute Force (Xeon) | 20MB | 6 | 2.77 秒 | 1.00× |
| DES-Boyer-Moor (Xeon) | 20MB | 6 | 2.63 秒 | 1.05× |
| DES- Brute Force (MAP) | 20MB | 6 | 0.0143 秒 | 193.09× |
| DES-Brute Force (Xeon) | 20MB | 10 | 3.31 秒 | 1.00× |
| DES-Boyer-Moor (Xeon) | 20MB | 10 | 3.11 秒 | 1.06× |
| DES- Brute Force (MAP) | 20MB | 10 | 0.0143 秒 | 231.76× |
在 Xeon 上实现的 DES 的情况下,该代码是 Minnesota Supercomputer Center 的 Stuart Levy 编写的优化代码。
本文解释了可重构计算,展示了可以实现的方法和结果的示例。可以证明显着的性能提升。目前,RC 对计算科学有很多贡献,但未来将取得远远超出微处理器世界中摩尔定律增益的进步。今天的程序员可以使用熟悉的编程模型访问 RC,并提供了一个框架,更大的硬件设计师群体可以在其中通过开源创造力和生产力对高性能计算产生影响。
RC 已经酝酿了很长时间,但是支持软件和硬件技术已经为 RC 成为从嵌入式处理器到 Peta 级超级计算机的每台计算机的一部分奠定了基础。
本文的资源: /article/7867。
Dan Poznanovic (poz@srccomp.com) 是 SRC Computers, Inc. 的软件开发副总裁,自 1987 年最初加入 Cray Research, Inc. 以来一直从事高性能计算领域。
