
使用 libferris 进行文件系统索引
libferris 项目于 2001 年初启动,旨在创建一个作为共享库运行的虚拟文件系统。 libferris 通过单个文件系统接口呈现许多树状结构。 libferris 在用户地址空间而不是内核中运行,因此可以公开大量树状源。 从 Linux 内核访问这些源将非常困难。 所有文件系统都可以通过 libferris 中的 root:// URI 访问,包括内核 file:// URL、关系数据库、XML 文件和数据库、网络可访问资源(如 HTTP/FTP 服务器)以及其他复合文件(如 db4、tarballs 和 RDF),以及标准内核文件系统(如 ext3 和 XFS)。
为何选择 libferris?
以下是您可能选择 libferris 进行文件系统索引和查询的原因
插件可以提取文件中捕获的文本,用于全文索引。
用于索引的所有数据源的统一接口——例如,以下所有内容都可以使用 libferris 进行索引:SleepyCat dbxml 文件、tarballs 中的文本以及 mbox 文件或关系数据库中的单个消息。
可以对文件中捕获的元数据进行索引和搜索。 例如,可以对音频文件的 ID3 标签进行索引,以提供按艺术家搜索功能。
所有索引插件都具有相同的基本添加/查询命令,因此您可以相当轻松地在索引实现之间切换。
用于文件系统的全文和扩展属性的组合搜索。 ferris-search 工具允许您将多个搜索合并为一个结果集。
能够根据文件曾经拥有的元数据搜索文件。
能够根据监督式机器学习 (SML) 判断搜索文件——用于文件系统的垃圾邮件过滤。 遗憾的是,涵盖 SML 超出了本文的范围。
文件和目录的概念在 libferris 中合并为一个单一的抽象概念。 这允许像 tar 存档这样的东西通过 libferris 隐式地作为文件系统挂载。 在这种情况下,tarball 同时是文件和目录。
扩展属性 (EA) 接口呈现来自多个来源的数据,包括内核的 listxattr(2) 接口、RDF/bdb 存储库和动态提取的值。 动态 EA 的一个例子是图像的宽度。 当读取图像的宽度 EA 时,libferris 使用插件来确定图像文件的宽度。 另一个例子是音频文件的采样率。
表 1. EA 示例
| 名称-扩展名 | 文件的扩展名,例如 tar |
| treeicon | 适用于此文件的图像的 URL。 |
| is-audio-object | MIME 主类型音频。 |
| is-source-object | 此文件的源代码。 |
| is-remote | 此文件对此机器是远程的。 |
| language-human | 此文件的人类语言。 |
| a52-channels | 音频通道数。 |
| year | 包含此音轨的专辑/单曲的发行年份。 |
更多 EA 及其描述列在 libferris 网站上(请参阅在线资源)。
这导致 libferris 可以创建和查询两种不同类型的索引——全文和 EA。 全文索引允许您根据文件包含的单词查找文件。 EA 索引允许您根据文件的元数据查找文件。 解析针对全文或 EA 的查询所需的索引结构差异很大。 例如,全文索引可以存储包含每个单词的文档列表(倒排文件),以解析诸如“查找包含单词 libferris 的所有文档”之类的查询。 EA 索引需要能够处理范围查询,例如“查找上个月修改的所有文件”。
libferris 使用插件来处理这些索引的实现。 对于全文索引,您可以使用以下任意一种或全部:基于倒排文件的内部格式、使用 gcj 编译的 Apache Lucene、支持 ODBC 的关系数据库、Xapian 或 PostgreSQL 中的 TSearch2 模块。 对于 EA 索引,您可以选择基于排序倒排文件的内部设计、LDAP、使用 gcj 编译的 Apache Lucene、支持 ODBC 的关系数据库或使用某些 PGSQL 的本机 PostgreSQL。 对于一般用途,推荐的选择是 Xapian 或 TSearch2 用于全文,PostgreSQL 或 ODBC 用于 EA 索引。
PostgreSQL 模块与 ODBC 的模块类似,但它们使用 PGSQL 和其他 PostgreSQL 特有的功能。 使用 PostgreSQL TSearch2 插件进行全文搜索需要在您的 PostgreSQL 服务器上设置模板数据库。 请参阅在线资源了解详细信息。
所有索引都存在于 libferris 中自己的目录中。 默认的全文和 EA 索引分别位于 ~/.ferris 中的 full-text-index 和 ea-index 中。 索引是使用 ferriscreate 包中的 fcreate 或 gfcreate 创建的。 与 libferris 中的许多工具一样,带有 gf 前缀的工具与带有 f 前缀的工具执行的操作大致相同,但它提供了 GTK+2 界面。 以下部分描述了两种索引类型的创建、填充和查询。
直接开始,我首先在 /tmp 中创建一个全文索引,向其中添加一些文件,然后使用该索引查询文件。 首先,我为新索引创建一个目录,并使用 gfcreate 在该目录中设置新索引
$ mkdir /tmp/text-index $ gfcreate /tmp/text-index
gfcreate 的 GUI 在最左侧的选项卡中显示主要 MIME 类型,并在 misc 选项卡中显示可以创建且被认为与 MIME 不同的内容。 选择 misc 后,所有可用的索引格式都会在第二个级别的选项卡中显示。 在图 1 中,我选择创建一个 Xapian 全文索引,使用英语进行词干提取并忽略单词大小写。
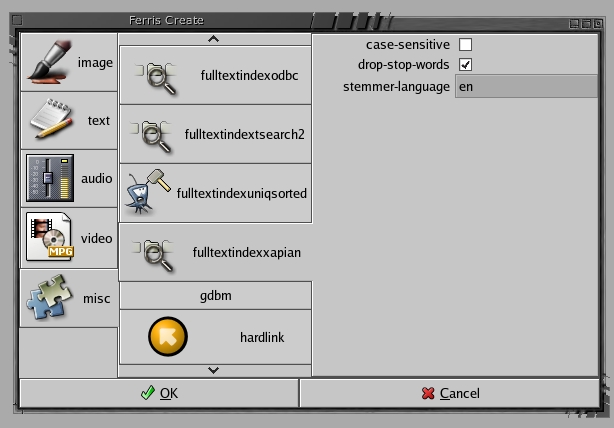
图 1. 使用 gfcreate 创建 Xapian 全文索引
当向全文索引添加文件时,libferris 尝试使用 as-text EA 来获取文件的文本表示形式。 许多插件都已创建,支持 as-text EA; PDF 文件、HTML 文件、man 页面和 djvu 图像都支持 as-text。
可以使用 -P 命令行选项告知 findexadd 和 findexquery 工具要使用的索引。 以下示例使用 Samba 3.0.3 包中的 PDF 文件和 man 页面作为示例输入。 由于路径会因您的 Linux 发行版而异,因此文件的路径前缀已替换为 /.../
$ findexadd -P /tmp/text-index \ /.../samba-3.0.3/docs/Samba-HOWTO-Collection.pdf $ findexquery -P /tmp/text-index samba ID 1 99% [file://.../Samba-HOWTO-Collection.pdf] Found 1 matches at the following locations: file://.../Samba-HOWTO-Collection.pdf $ findexadd -P /tmp/text-index /.../samba.7.gz $ findexquery -P /tmp/text-index smbstatus ID 1 100% [file://.../Samba-HOWTO-Collection.pdf] ID 5 93% [file://.../samba.7.gz] Found 2 matches at the following locations: file://.../Samba-HOWTO-Collection.pdf file://.../samba.7.gz
findexquery 最有趣的选项是 -P,用于设置索引的路径;--ranked 选项,用于执行排名全文查询;以及 --xapian,用于将原始 Xapian 格式查询传递到后端(请参阅资源)。
默认查询格式是布尔值。 在此格式中,所有字母数字单词都在索引中查找,并且有四个布尔运算符以中缀形式使用。 它们是 &(与)、|(或)、!(非)和 -(减)。 排名模式组合所有术语,并返回根据您的查询最有趣的文档列表。 在 Xapian 格式中,libferris 将查询直接传递到后端进行处理; 目前,只有 Xapian 后端可以处理此类查询。
添加到和查询 EA 索引的过程与全文索引的过程非常相似。 EA 索引使用 feaindexadd 和 feaindexquery 命令,这两个命令都接受 -P /索引路径 选项。
EA 索引的总体调整有三个参数。 这些参数可以在创建 EA 索引时设置。 它们与您感兴趣的为文件编制索引的 EA 相关。 例如,您可以创建一个精简的 EA 索引,其中仅包含文件名、大小和一些图像属性,用于图像文件搜索。 您也可以选择忽略一些需要一段时间才能计算或与您的搜索无关的 EA。 例如,如果您不打算使用索引进行完整性检查,则忽略 MD5、SHA-1 和其他校验和可以节省大量时间,因为这些校验和需要读取添加到索引的每个文件的整个文件。
通用 EA 索引参数中的第一个是 max-values-size-to-index 参数,它定义了要添加到任何属性的索引的值的最大字节长度。 大多数 EA 应该是相当短的值,范围小于 100 字节。 默认值是宽松的,允许任何单个 EA 值最多使用 1,024 字节。 另外两个属性是 attributes-not-to-index 和 attributes-not-to-index-regex。 这些属性定义了在向索引添加文件时要忽略的 EA 的名称。 在索引所有 EA 之间存在直接的权衡,这会使添加文件速度变慢,但保留了所有信息以进行查询;或者仅索引 EA 的子集,这会使添加速度更快,但某些查询将无法执行。
not-to-index 参数的默认值应允许文件相当快地添加,但仍然允许索引许多有趣的 EA。 可以通过运行 cc/capplets/index/ferris-capplet-index 工具来覆盖这三个参数的这些默认值,该工具设置新索引创建的默认值,并更改您的 ~/.ferris 索引以用于未来的文件索引。
对于 EA 索引,我们使用 PostgreSQL 数据库来存储索引。 为了无缝创建 EA 索引,在运行 fcreate 工具之前需要一个小的设置步骤。 必须默认启用 PGSQL 语言以用于新数据库。 以 root 身份运行时,以下命令执行此操作
# createlang -d template1 plpgsql
如果您不想更改 template1 数据库,您可以手动创建 PostgreSQL 数据库,为新数据库启用 plpgsql,并将 db-exists=1 附加到下面的 fcreate 命令行。
对于 PostgreSQL EA 索引,您还可以设置 PostgreSQL 数据库使用的用户名、密码、主机、端口和 dbname。 默认情况下 (db-exists=0),具有名称 dbname 的数据库不得存在,并将为此新 EA 索引创建。
对于使用关系数据库作为其实现的 EA 索引,还有另一个可调整的参数,允许您更改某些 EA 在关系数据库中规范化的方式。 再次强调,默认值应该是可以接受的。 我稍后会解释这种权衡。
extra-columns-to-inline-in-docmap 给出了一个 EA 列表,这些 EA 对于搜索非常重要,应该被反规范化到 docmap 表中。 对于几乎每个文件都具有唯一值的 EA,将更有效地内联存储在 docmap 表中。 要以这种方式反规范化 EA,您还必须提供该 EA 的 SQL 类型。
关系数据库中 EA 的规范化
要解析对规范化 EA 的查询,涉及四个表。 docmap 表存储文件的 URL 和一个综合整数键 docid。 attrmap 表存储 EA 的名称并分配一个综合整数键 attrid。 根据值的类型,使用了许多 valuemap 表中的一个,但它们都遵循类似的样式。 例如,strlookup 为 varchar 值分配一个综合整数键 vid。 最后,一个连接表 docattrs 将 docid 与 attrid 和 vid 连接起来,以记录文件具有具有给定值的属性。 因此,要解析查询 (width<=800),如果宽度 EA 是规范化的,则需要查找 attrid 和 vid 以连接到 docattrs 表中,从而生成具有满足查询的宽度的 docid 列表。
规范化的 EA 直接作为列存储到 docmap 表中。 要解析上面的宽度查询,将使用 docmap.width 列上的关系数据库索引来直接查找匹配的 docid。 这种规范化是空间与时间的权衡。 通常,对于您计划经常搜索的 EA,您会考虑内联它们。 许多不属于 stat(2) 调用或被认为非常有趣的 EA 应保留在 attrmap、valuemap 和 docattrs 表中进行索引。
在此示例中,我使用我的用户名和 dbname lj。 下面的第二个命令使用非交互式 fcreate 工具创建 EA 索引。 第三个命令然后将我的共享图像目录中的所有 JPEG 文件添加到该索引。 您还可以将 feaindexadd 与 -d 选项一起使用,以在命令行上显式列出文件路径。 如果没有 -d,feaindexadd 会尝试递归到您提供的路径中
$ mkdir /tmp/ea-index $ fcreate --create-type=eaindexpostgresql \ --target-path=/tmp/ea-index dbname=lj user=ben # if you have setup new db, append db-exists=1 $ find /usr/share/backgrounds/images \ -name "*.jpg" \ | feaindexadd -P /tmp/ea-index --filelist-stdin
我的图像目录包含 42 个 JPEG 图像。 在这里,我查询索引
$ feaindexquery -P /tmp/ea-index '(width>=640)' Found 34 matches at the following locations: file:///usr/share/backgrounds/images/dewdop_leaf.jpg ... $ feaindexquery -P /tmp/ea-index '(size>=100k)' Found 42 matches at the following locations: file:///usr/share/backgrounds/images/dewdop_leaf.jpg ... $ feaindexquery -P /tmp/ea-index \ '(&(width<=800)(size>=100k))' Found 19 matches at the following locations: file:///usr/.../images/space/apollo08_earthrise.jpg ...
EA 索引查询语法基于 RFC 2254 中描述的“LDAP 搜索过滤器的字符串表示形式”。 这是一种简单的语法,提供了一小部分比较运算符来构成 lvalue 运算符 rvalue 术语,以及一种使用布尔与 (&)、或 (|) 和非 (!) 运算组合这些术语的方法。 所有术语都包含在括号中,运算符位于其参数之前。 运算符保持简单:== 表示相等,<= 和 >= 表示值范围,=~ 表示正则表达式匹配。
ODBC(可选)和 PostgreSQL(始终)EA 索引插件允许您在索引中存储文件的多个 EA 版本。 拥有文件的多个元数据版本允许您根据文件曾经拥有的 EA 值查询文件。
要使用此功能,您必须在使用特殊 EA 进行查询时选择一个时间范围来匹配搜索。 时间限制 EA 是 atime、ferris-current-time、multiversion-mtime 和 multiversion-atime。 最后两个 EA 与您要查找的文件的 mtime 和 atime 匹配。 文件的索引数据的 ferris-current-time EA 是索引该文件的时间。 如果未选择时间范围,则在执行查询时,仅考虑每个文件的最新版本元数据。
时间限制可以作为字符串给出,libferris 会尽力推断您的时间字符串的格式。 在 libferris 发行版的 tests/timeparsing 目录中有一个 timeparse 工具,它接受时间值并告诉您 libferris 对您的时间字符串的理解。 有关允许的时间字符串的更多详细信息,请参阅 libferris FAQ 项目(请参阅资源)。
以下基于时间的查询示例查找一年多以前索引的给定宽度范围内的所有图像文件
$ feaindexquery -P /tmp/ea-index \ '(&(width>=1600)(ferris-current-time<=1 year ago))'
如果一个大型图像文件在两年前被索引,随后被缩略图图像替换并重新索引,则上述查询将返回该文件。 这是因为它的元数据版本之一与给定的查询匹配。
通过使用与查询 EA 值相同的接口来处理 EA 查询的时间限制,您可以使用所有标准查询机制来选择您的匹配时间范围。 例如,我可以选择在 2003 年索引的具有给定宽度的文档,或者在上个月修改的具有特定所有者的文档
## note, all one line
$ feaindexquery -P /tmp/ea-index '
(|
(&
(width>=1600)(ferris-current-time>=begin 2003)
(ferris-current-time<=end 2003)
)
(&
(owner-name==sarusama)
(multiversion-mtime>=end last month)
)
)
希望我已经传达了足够的信息,说明 libferris 在其当前 EA 和全文索引实现方面可以提供什么,以引起您的兴趣。 当前的实现是朝着更正式的语义文件系统查询和浏览交互风格迈出的必要一步。
Ben Martin 从事文件管理器工作已有十年以上。 他目前正在攻读博士学位,将语义文件系统与形式概念分析相结合,以改善人机文件系统交互。
