
使用 LAMP 替换旧数据库
新西兰广播电台是一家公共广播公司,与其他广播公司一样,我们拥有庞大的音乐和音乐节目库。1987 年,我们委托开发了一个名为 BRS 的新型计算机化图书馆编目系统,以帮助广播员存储图书馆数据。
具体来说,BRS 用于存储关于 LP(以及后来的 CD)、磁带、现场音乐会录音、访谈和古典乐谱集的数据。该系统通过哑终端以及后来的 PC 上的终端仿真器进行访问。广播电台的工作人员也使用它来安排和跟踪 Concert FM(公司旗下的古典音乐频道)播放的音乐。
BRS 是 Maxwell Online, Inc. 出售的专有编目应用程序。它在 UNIX 上运行,寿命很长。在其 16 年的生命周期中,它经历了几次硬件升级;在软件方面,为其他类型的数据添加了一些额外的数据库表。尽管有人声称 BRS 无法幸免于 Y2K 问题,但它还是安然度过了,并在 2003 年开始认真讨论替换它的问题。
过去,这种性质的替换项目可能已经外包出去。然而,经验表明,在某些情况下,我们最终会得到一个闭源的定制应用程序,并被锁定在一家公司进行持续的升级和修改。有时,当这些公司停止交易,人员流动时,我们依赖的应用程序就会变成孤儿,数据很难或不可能转移到新的应用程序中。
DIY 项目并非总是合适的,我们仔细权衡了所有问题。考虑到数据和应用程序的关键性质,以及内部技能的可用性,我们认为在这种情况下,自己承担这个项目是合适的。
我们 IT 部门的 Bruce Intemann 是项目负责人,他在一台运行 Red Hat Linux 8、Apache Web 服务器、MySQL 和 PHP (LAMP) 的桌面 PC 上快速构建了一个概念验证。Bruce 能够找出如何以纯文本格式从 BRS 中提取数据,并基于 MySQL 的全文索引构建了一个简单的搜索界面,其中手动转换了一小部分数据。通过标准的 Web 浏览器授予访问权限。
大约在这个时候,我正在为公司的另一个部门完成一个 PHP Web 项目,并主动提出我的技能来支持这个新项目。当要为系统命名时,我认为保留 B 和 R 会很好,因为它们是系统“父母”的首字母。我的妻子想出了 BRAD 这个名字,我们的一位员工决定这个首字母缩写词代表 Bruce 和 Richard 的音频数据库。这个名字就此确定下来。
在概念验证被接受后,我编写了一个简短的 Perl 脚本来解析所有数据(大约 20 万条记录)并将其插入到 MySQL 数据库中。这很复杂,因为几个较小的数据库已合并到主数据库 Works 中,以帮助全局搜索。幸运的是,一个字段用于指示原始数据的位置(来源)。请参阅列表 1 以查看 BRS 数据的示例。
列表 1. BRS 原始文本格式的一条记录
*** BRS DOCUMENT BOUNDARY ***
..Document-Number:
000080019
..TI:
Ode for the centenary of Trinity College Dublin,
Great parent, hail to thee (Z327)
..MA:
Hyperion
..CA:
CDA 66476
..ME:
cd
..RA:
The King's Consort
..CF:
vocal - ode
..CP:
PURCELL
..CD:
Robert King
..SO:
Gillian Fisher, Evelyn Tubb (sopranos), James Bowman, Nigel
Short (counter-tenors), Rogers Covey-Crump (high tenor), John Mark
Ainsley (tenor), Michael George, Charles Pott (basses)
..ST:
T12-21
..AT:
Purcell - Complete odes and welcome songs vol 5
..DU:
002419
..PT:
..RD:
2-4 Jan 1991
..RE:
..AD:
..SR:
..RO:
..CY:
1694
..LI:
Nahum Tate
..OR:
..LN:
..PU:
..RI:
..ED:
..LP:
..LQ:
cp
..LQ:
..NO:
..IS:
..LD:
921012
..LU:
leander
*** BRS DOCUMENT BOUNDARY ***
一旦完整的数据快照传输完毕,我就使用面向对象的 PHP 重写了 Bruce 的代码。我还利用了我在另一个项目中编写的搜索类,对其进行了修改以显示音乐数据而不是新闻报道。
粗略的演示版本部署在开发服务器上,并征求了工作人员的意见。根据他们的反馈,我们决定最好的方法是在现有系统运行的同时,根据工作人员的反馈不断改进系统。开发期间的双重运行确保了工作人员仍然可以访问工作系统,并且还允许比较从两个系统获得的搜索结果。这也让工作人员对使用新系统及其呈现的结果建立了信心。
为了将数据分离到其原始集合中,编写了一个更复杂的脚本来解析数据文件,从 BRS 中取消合并所有原始数据源。这些集合被插入到图 1 所示的单独数据库和表中。公司中的每个部门在 BRAD 中都被视为一个区域,每个数据源都被称为一个区段。任何区域都可以包含指向其他区域中的区段的别名,或者跨任何表列表进行搜索的选项,而不管它们在系统中的位置如何。
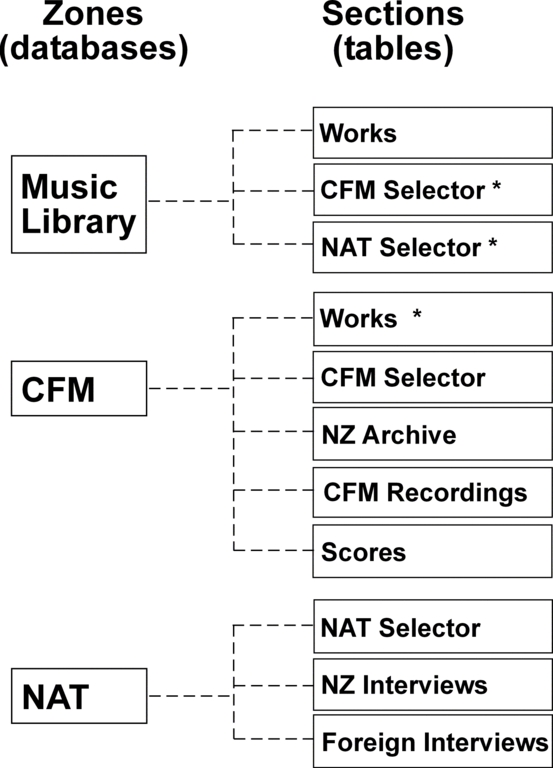
图 1. BRAD 的数据源排列。标有 * 的表表示指向当前区域外部的另一个表的别名。
BRS 数据库是扁平的(非关系型的),并且数据是由不同的人在多年中以不同的格式输入的。当我查看每个快照进入新系统的结果时,我调整了 Perl 脚本以清理一些数据异常,尤其是在日期字段中。例如,记录上次更新的原始文本日期字段过去是手动编辑的——在 BRAD 中,这是一个由系统维护的 datetime 字段。还添加了字段来跟踪创建日期。
BRAD 构建在运行 LAMP 的服务器上,因此我们应该在其开发中使用开源 PHP 类似乎是显而易见的。PHP 扩展和应用程序仓库 (PEAR) 模块用于数据库访问、表单生成和处理以及基本错误处理。修改了现有的错误类,以警告错误,但向用户隐藏完整消息。
每当我需要特定功能时,我都会先寻找开源模块,然后再编写自己的模块。这样做大大加快了开发周期(有关 BRAD 中使用的模块列表,请参见表 1)。
由于 BRS 系统已经存在很长时间了,工作人员已经将其使用完善到很高的程度。BRS 确实具有强大而快速的搜索功能。它能够在用户指定的所有字段或任何字段中搜索特定单词。然而,必须克服一些怪癖,例如停用词,即未编入索引的词。这些词包括一些音乐团体的完整名称,“The Who”就是一个例子。在这种特殊情况下,要查找 The Who 的项目,您必须了解该团体的其他信息,例如其中一位成员(Pete Townsend)或他们创作的作品(Tommy)。这两种方法都不总是可靠的。
有时出乎意料的行为和使用命令行界面的困难意味着大多数工作人员都使用音乐图书管理员来查找项目,只需提交一份手写的请求列表即可。新系统的期望之一是具有同等或更好的搜索能力以及任何经过最少培训的人都可以使用的简化界面。
BRS 最强大的功能之一是您可以将搜索词限制在某些字段,例如
Mozart.cp. piano
将返回作曲家 (cp) 字段中包含 Mozart 且任何字段中包含 piano 的任何内容。我们决定在 BRAD 中保留这种语法,以便高级用户仍然可以进行他们习惯进行的搜索类型。我们计划为 BRAD 添加一个高级搜索页面;然而,事实证明这种语法非常灵活,以至于我们不需要它。
我们在项目中面临了几个挑战。其中大多数与修改 MySQL 的默认行为以满足我们的要求有关。第一个挑战是删除所有停用词——MySQL 由于假定它们在数据中很常见而未编入索引的单词列表。在我们的情况下,每个单词都被认为是重要的。
在 MySQL 中,删除停用词只需在将任何内容添加到数据库之前,将以下行添加到 MySQL 配置文件中即可
ft_stopword_file = ""
第二个挑战是允许搜索小于 MySQL 通常使用的四个字符限制的单词。BRS 系统对每个单词进行索引,无论大小,除了那些列为停用词的单词,删除所有停用词将使任何搜索结果更符合输入的词条。
这个问题通过做两件事来解决。首先,我们将索引词大小减少到三个字符,方法是将以下内容添加到配置文件中
set-variable = ft_min_word_len=3
由于数据量,这些设置被认为是可接受的性能权衡。
我们做的第二件事是实现一个智能查询引擎,该引擎在将查询发送到 MySQL 之前,会根据搜索词中最短的单词来调整查询。这允许进行全文搜索,而与任何搜索词的长度无关。
最后一个挑战是使所有搜索默认情况下都是 AND 搜索。MySQL 的布尔全文模式在未使用修饰符时是 OR 搜索。您通常会在每个词条前添加一个 + 以使其成为 AND 搜索。查询引擎被构建为在没有其他修饰符时自动添加 +。
BRAD 的核心是词条解析器和查询编译器。词条解析器接受查询,将其分解并将组件放入数组中。该数组包含一个 MySQL 修饰符 +, -, <, >, ~;一个原子,即查询字符串的一部分——单词或短语;以及一个可选的字段名称。
当没有修饰符时,词条解析器会自动向每个原子添加 +,使所有搜索默认情况下都是 AND 搜索。这是一件好事,因为用户期望搜索引擎就是这样工作的——您添加的词条越多,搜索就越精确。
可选字段用于支持高级搜索,当特定字段中需要特定单词时。在 BRAD 中,我们保留了 . 字段搜索运算符。
当进行正常搜索时,查询编译器会查询搜索范围内的每个表,并返回每个表的全文字段列表。这些用于编译跨越所有全文字段的查询。
查询编译器可以管理全文通用词条和非全文、特定字段词条的混合。查询编译器允许几乎无限地扩展 BRAD 的数据源,并允许生成的查询动态适应——消除了为每个代表数据库中真实对象的对象类使用静态查询样板的需要。
一个标准的 Web 页面表单允许用户控制搜索的所有方面(图 2)。用户可以选择任意数量的区域或表。这些可以自定义以满足公司和用户的需求。

图 2. BRAD 搜索界面说明(参见表 2)
表 2. 搜索界面中的字段
| 1a:搜索区域 | 这是输入搜索词条的位置。 |
| 1b:搜索按钮 | 按此按钮进行搜索。 |
| 2a:过去的搜索 | 打开一个区域,显示过去进行的搜索。可以单击此列表中的项目以再次进行搜索。 |
| 2b:最新 | 显示 Works、CFMS 和 NATS 数据源中的最新条目。每个数据源限制为 250 个,并按最新条目在最顶端排序。 |
| 2c:更少 | 此链接(以及下一行上的链接)在“更多”和“更少”之间切换,并减少或增加显示的 BRAD 搜索选项的数量。 |
| 3a:区域 | BRAD 将其数据划分为与公司不同部门相关的区域。每个区域都有许多不同的数据源。区域选择器允许您选择要搜索的公司区域。 |
| 3b:在 | 此选择器允许您确定将搜索区域中的哪些数据。您通常可以搜索区域中的所有数据,或者仅搜索一种类型的数据。 |
| 4:排序方式 | |
| 5:媒体 | 您可以要求 BRAD 仅搜索存储在某些类型的媒体上的记录。 |
| 6:计数 | 每页显示的项目数。 |
| 7:显示模式 | 显示模式与旧的 BRS 系统相关,并允许用户为搜索结果选择不同的摘要。显示模式可以自定义,因此如果用户需要特殊格式,可以添加。 |
| 8:显示结果 | 在选项卡中或作为列表。BRAD 的正常模式在选项卡式界面下显示每个搜索的结果。在列表模式下,它在单独的标题下打印列表。列表模式可用于制作列表以进行打印或粘贴到电子邮件中。 |
| 9:在以下位置显示详细信息 | 此选择器允许用户选择是在新窗口还是当前浏览器窗口中查看完整记录数据(通过单击项目的链接)。 |
BRAD 的编写目的是在所有方面都具有可扩展性。数据搜索可以扩展到任何类型的数据,并且可以将特定类型的搜索应用于该数据。
我们公司存在的问题之一是在不同的任务中使用不同的数据库应用程序,不同的数据分散在多个应用程序中。我们的两个广播网络使用一个名为 Selector 的应用程序来安排音乐节目的播出。一个数据库包含大约 10,000 首音乐曲目,用于国家广播电台,而 5 个数据库中包含 100,000 首音乐曲目,用于 Concert FM。由于 Selector 可以处理的数据大小有限制,因此 Concert FM 使用了 5 个数据库。
如果工作人员想要搜索一段音乐,他们必须转到三个应用程序中的每一个:BRS、国家广播电台 Selector 和 Concert FM Selector。没有办法一次搜索所有这些。
幸运的是,Selector 有一个以 XML 格式导出数据的实用程序。尽管没有关于此的文档,也无法获得任何文档,但 Bruce 还是能够确定如何运行导出实用程序并将数据从 Windows 工作站通过 FTP 传输到 BRAD 服务器。这每天早上完成,并且在 BRAD 上运行一个 Perl 脚本来导入所有数据。五个 Concert FM 数据库合并到一个表中,因为所有数据都是唯一的。
扩展了原始搜索模块以搜索多个表并返回结果,而与字段的数量或类型无关。结果以选项卡式方式显示(图 3)。

图 3. 截断的结果页面
您可以看到 Works 表中的第一个结果。另一个非活动选项卡显示 CFM Selector 表中的结果数。根据搜索范围和结果,可能会显示任意数量的选项卡。制作人现在可以从一个简单的界面搜索任何音乐数据。
自第一个 Alpha 版本发布以来,应工作人员的要求添加了许多其他新功能。其中包括搜索历史记录和购物车。购物车可以容纳来自任何表的项目。购物车可以保存和恢复,一旦创建,购物车编号也可以通过电子邮件发送给图书管理员。这节省了工作人员打印或通过电子邮件发送整个材料列表的麻烦——他们只需通过电子邮件发送购物车编号即可。
最近添加的功能是别名搜索。别名替换了一组更复杂的词条,这些词条可能会经常使用。这方面的一个例子是搜索新西兰内容——包含新西兰艺术家或由新西兰人创作的音乐。这很有用,因为我们对两个网络都有自我施加的新西兰音乐配额。
经过多年的数据输入和人员变动,在主 Works 数据库中使用了不同的字段和标识符来指示新西兰状态。新西兰音乐别名会自动将所需的词条和字段添加到查询中,作为 OR 搜索。这是通过在词条解析器之上构建一个新类并使用它从查询中提取任何别名来实现的。然后,解析器将所需的参数添加到查询编译器维护的查询堆栈中。以下是一些 BRAD 别名示例。查询
Mozart @nza
为我们提供了 Mozart 和任何新西兰内容字段为 true 的内容。实际查询如下所示
SELECT * FROM brs.works WHERE (cf REGEXP '[[:<:]]local[[:>:]]' OR cf
REGEXP '[[:<:]]nz[[:>:]]' OR lq REGEXP '[[:<:]]nz[[:>:]]') AND MATCH
ti,ra,cf,cd,cp,so,at,notes,lq AGAINST ('+Mozart' IN BOOLEAN MODE) ORDER BY ti asc LIMIT 1000
还添加了时长搜索,以便制作人可以查找特定范围内的素材——通常需要查找持续时间大致已知的特定作曲家的音乐。在 BRAD 中,方括号中的数字被视为时长查询。BRAD 可以进行近似搜索或在时长范围内进行搜索。请参阅侧边栏中的一些示例。
BRAD 时长示例
小于
brahms [<20]
介于(您还可以指定时间范围)。以下内容查找包含 mozart 且介于 20 分 30 秒和 30 分 15 秒之间的任何内容
mozart [20:30-30:15]
近似匹配——以下内容查找您指定的时间加减 10%;c 是 circa 的缩写
mozart [ c 24 ]
您还可以添加时间范围。以下输入检索长度为 24 分钟的项目,加减 1 分钟
mozart [ c 24 r 1 ]
复杂时长搜索——以下内容搜索作曲家为 Beethoven 且持续时间在 20 到 22 分钟之间的作品
beethoven.cp [20-22]
为上次搜索编译的查询
SELECT * FROM cfm.cfms WHERE (du <= 1320)
AND (du >= 1200)
AND MATCH ti,ca,ma, ra,cd,cp,so,at,notes AGAINST
('+beethoven' IN BOOLEAN MODE)
AND MATCH cp AGAINST ('+beethoven' IN BOOLEAN MODE)
ORDER BY ti asc LIMIT 1000
前面提到的 Concert FM Selector 数据已为所有数据正确设置了新西兰艺术家和时长字段,因此这些别名可以可靠地用于整个数据集。由于 Works 数据中项目类型混杂,因此仅搜索具有有效时长的项目。过去,根本不可能在 Works 中进行任何时长搜索,因此这是一个改进。
这个项目使我们能够替换关键的 Radio NZ 编目系统,并以较低的总拥有成本为员工提供增强的功能。它还为新的和旧的数据提供了存储平台。
将来,节目制作人可能会对作曲家或艺术家进行一次搜索,并获得一整套结果,其中包括音乐曲目、访谈和档案材料。它甚至可以指示此人姓名的正确发音并提供其电话号码。
当我们发现 BRAD 的更多用途时,它可能会继续成为一个进行中的工作。这是 DIY-IT 的好处之一——系统是我们的,我们可以根据需要随时扩展或修改它。
Richard Hulse 是新西兰广播电台的高级录音工程师,目前正在从事多个 IT 项目,包括改进新西兰广播电台网站 (www.radionz.co.nz)。

