
构建生物信息学超级计算集群
生物信息学是一个日益重要的科学学科,涉及 DNA 和蛋白质序列的分析。“基本局部比对搜索工具”(BLAST)由美国国家生物技术信息中心(NCBI)开发,旨在帮助科学家分析这些序列。该工具的公共版本可在 Web 上或通过下载获得。由于 BLAST 网站是一个非常受欢迎的工具,其性能充其量只能说是不稳定的。南达科他大学(USD)计算机科学生物信息学小组决定通过结合免费提供的软件,在 Linux 集群上实现 BLAST 工具的并行版本。BLAST 集群由注定要报废的旧台式 PC 组成,通过为小范围的研究人员提供最新的数据库来改进搜索。
我们的集群项目始于开放源代码集群应用程序资源(OSCAR)的实施。OSCAR 由开放集群组开发,旨在通过在一个软件包中提供创建 Linux 集群所需的所有必要软件来改进集群计算。OSCAR 帮助自动化集群软件的安装、维护甚至使用。图形用户界面提供逐步安装指南,并兼作图形维护工具。
WWW BLAST 由 NCBI 创建,为 BLAST 用户提供基于 Web 的前端,是我们为 BLAST 集群选择的 Web 界面。WWW BLAST 可以轻松安装在运行 Web 服务器(如 Apache)的 Linux 机器上。
虽然 WWW BLAST 增强了我们集群的可用性,但 mpiBLAST 增强了性能。mpiBLAST 由洛斯阿拉莫斯国家实验室(LANL)开发,旨在通过并行执行查询来提高 BLAST 的性能。mpiBLAST 基于消息传递接口(MPI),这是一种用于开发并行程序的常用软件工具。mpiBLAST 提供了并行 BLAST 查询所需的所有软件。
基于 Web 的查询表单标志着我们集群上 BLAST 搜索的开始。默认情况下,WWW BLAST 不支持批处理和作业调度。幸运的是,OSCAR 软件包提供了 OpenPBS 和 Maui 来处理作业调度和负载均衡。有了这种支持,集群可以更轻松地处理更大的用户群体。OpenPBS 是一个灵活的批处理排队系统,最初为 NASA 开发。Maui 通过允许更广泛的作业控制和调度策略来扩展 OpenPBS 的功能。
一旦用户提交查询,就会调用 WWW BLAST 提供的 Perl 脚本。此脚本根据查询表单中的参数创建唯一的作业。作业是提交给 OpenPBS 执行的程序或任务。作业提交后,OpenPBS 确定节点可用性并根据调度策略执行作业。此作业启动本地区域多计算机(LAM)软件,这是一个用户级、基于守护程序的运行时环境。LAM 作为 OSCAR 安装的一部分提供,并提供 MPI 程序所需的许多服务。OpenPBS 通过使用 mpirun 命令执行作业,该命令在每个节点上执行查询并收集结果。WWW BLAST 将这些结果传递回浏览器,向用户呈现人性化的报告(图 1)。
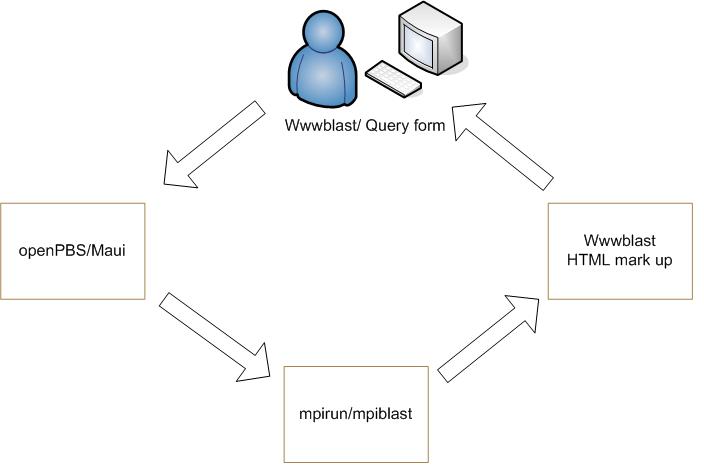
图 1. 当 Web 上收到查询时,WWW BLAST 将作业提交给 OpenPBS。OpenPBS 使用 mpirun 启动作业,WWW BLAST 格式化结果。
实施集群技术以执行并行 BLAST 搜索需要进行一些软件重新配置。我们使用的许多工具都可以在默认安装下工作,但并行 BLAST 集群需要额外的配置才能运行。
集群可以由各种 PC 组成。我们使用的 17 个节点具有 533MHz 英特尔赛扬处理器、256MB 的 RAM 和 15GB 的硬盘空间——按照今天的标准来看,这是相对低端的。对于集群设置而言,对所有节点使用完全相同的硬件设置并非至关重要,但这样做确实减少了安装和维护集群所需的时间和精力。一旦所有硬件准备就绪,您必须选择一台机器作为头节点。如果您不使用相同的机器,则最好使用最强大的机器作为头节点。由于我们使用的所有 PC 都具有完全相同的硬件配置,因此头节点的选择是任意的。
在获得所有必要的 PC 硬件后,您需要选择 Linux 发行版。OSCAR 文档列出了其所有支持的发行版,而 Red Hat 9.0 是我们选择的发行版。安装 Red Hat 非常简单;我们选择了默认选项。由于 OSCAR 软件依赖于特定版本的操作系统软件包,因此一旦安装完成,您就不应安装任何更新。当然,这有很多安全隐患,这就是为什么将集群与 Internet 隔离在防火墙之后非常重要的原因。
在头节点 PC 上安装 Red Hat 后,我们下载了 OSCAR 2.3.1 tarball。请参阅在线资源以获取安装文档。我们将 OSCAR 下载到 root 的主目录中,因为 OSCAR 需要以 root 身份安装。安装 OSCAR 软件就像运行以下命令一样简单
tar -xvfz oscar-2.3.1.tar.gz cd oscar-2.3.1 ./configure make install
安装完成后,我们需要将所有 Red Hat 9.0 RPM 复制到我们头节点 PC 上的 /tftpboot/rpm。OSCAR 安装需要在安装期间从此目录安装某些软件包。我们使用以下命令复制文件
cp /mnt/cdrom/RedHat/RPMS/*.rpm /tftpboot/rpm
复制完所有 RPM 后,即可开始 OSCAR 安装。OSCAR 为安装提供了图形安装向导。替换您的私有网络以太网适配器的名称;我们的是 eth1
cd $OSCAR_HOME ./install_cluster eth1
片刻之后,OSCAR 安装向导开始加载。此向导提供了一个图形用户界面和一个直观的八步流程来完成集群设置(图 2)。我们安装过程中的唯一变化是将默认 MPI 实现设置为 LAM/MPI 而不是 MPICH。我们选择 LAM 是因为它对于 mpiBLAST 的正确执行是必需的。
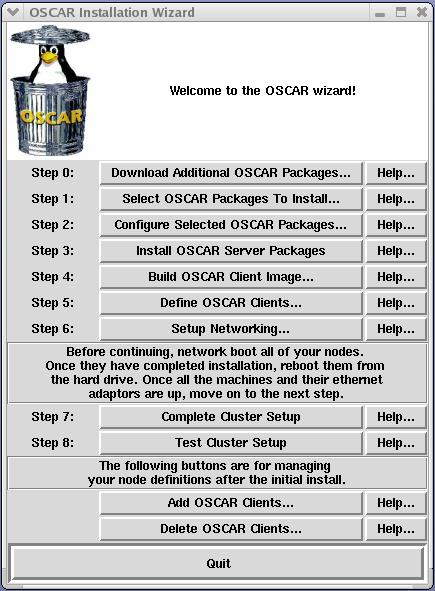
图 2. OSCAR 安装向导允许您部署、配置和测试集群软件。
单击步骤 2“配置选定的 OSCAR 软件包”会显示一个小对话框(图 3)。从那里,您可以选择“环境切换器”按钮,然后选择 LAM 作为安装的默认环境(图 4)。

图 3. 单击“配置...”以将环境更改为 LAM。

图 4. 选择 LAM 作为默认环境。
我们按照 OSCAR 文档中描述的其余步骤构建并安装了节点的磁盘映像。安装并测试完所有节点后,我们下载并安装了 mpiBLAST。
我们下载了 mpiBLAST,并按照 README 文件中提供的文档进行了安装。我们在我们的 $PATH 中为 mpiblast 和 mpirun 创建了符号链接,并且不需要对 mpiBLAST 进行进一步配置。
安装 mpiBLAST 后,我们需要下载一个数据库进行搜索。为了使 mpiBLAST 正常执行,数据库需要采用 FASTA 格式。NCBI 在 NCBI 网站上提供了其所有数据库的索引,该索引列出了一个 FASTA 子目录,其中包含 FASTA 格式的所有数据库。我们将 nr 数据库的副本下载到 /usr/local/mpiBLAST/db/,这是一个在 mpiBLAST 安装期间设置的 NFS 共享文件夹。mpiBLAST 提供了 mpiformatdb 命令,该命令将数据库格式化为段;段的数量取决于集群中的节点数。mpiformatdb 将其创建的段放置在共享目录中。此目录在安装期间在 mpiblast.conf 中定义,并由所有 mpiBLAST 程序使用。以下是格式化数据库的示例
# /usr/local/mpiBLAST/bin/mpiformatdb -N 16 -i nr
在此,-N 指定数据库段的数量——通常是集群中的节点数——-i 指定要格式化的数据库文件的名称。在此示例中,nr 数据库被格式化为 16 个单独的段。mpiformatdb 不会将段复制到节点,因此在每个节点在第一次查询期间复制其数据库段时,会产生大量的开销。每个节点仅复制一次段。如果从节点中删除段,则在下一次查询期间会再次复制该段。
为了简化集群的管理,我们编写了一个脚本来下载最新版本的数据库,使用 mpiformatdb 格式化它,并通过执行简单的 BLAST 查询将其分发到节点。我们计划使用 cron 每周运行此脚本。在我们能够并行执行 BLAST 查询后,我们添加了来自 WWW BLAST 的基于 Web 的前端。
mpiBLAST 提供命令行 BLAST 搜索,并包含两个用于与基于 Web 的前端交互的文件:blast.cgi 和 WWWBlastwrap.pl。这些文件配置为与 WWW BLAST 一起使用。因此,我们的下一步是将 WWW BLAST 下载到 /var/www 目录中,创建 /var/www/blast/ 目录。必须进行一些配置更改,才能使 WWW BLAST 提交 BLAST 搜索以进行并行执行。
WWW BLAST 提供了自己的数据库目录。由于我们使用 mpiBLAST 格式化数据库,因此我们必须将 WWW BLAST 的 db/ 目录指向 mpiBLAST 的目录。然后,我们将 blast/ 中的 db/ 目录设为指向 mpiBLAST 的 db/ 目录的符号链接。
WWW BLAST 提供了一个名为 blast.cgi 的文件,该文件执行 BLAST 查询。mpiBLAST 提供了一个替换的 blast.cgi,它通过 WWWBlastwrap.pl 执行并行 BLAST 查询。WWWBlastwrap.pl 是一个 Perl 脚本,它创建一个查询以供 mpiBLAST 执行。WWWBlastwrap.pl 以另一个 Perl 脚本的形式创建此查询,并使用 Web 表单中的参数填充它。此脚本提交给 OpenPBS。WWWBlastwrap.pl 提供多种功能,包括解析表单的参数、创建要通过 OpenPBS 提交到集群的脚本以进行作业排队和负载均衡,以及以浏览器友好的格式返回 BLAST 搜索结果。
但是,我们需要对 WWWBlastwrap.pl 进行一些更改,以使其在我们环境中正确运行。我们进行的第一个更改是对全局变量 $scratch_space 和 $MPIBLASTCONF。这两个变量在脚本的整个生命周期中使用。$scratch_space 保存包含查询期间使用的临时文件的目录的绝对路径。$MPIBLASTCONF 保存包含 mpiBLAST 配置文件的目录的绝对路径。这两个目录都是在 mpiBLAST 安装期间设置的。我们将这两个变量设置为如下
$scratch_space="/usr/local/mpiBLAST/shared/scratch"; $MPIBLASTCONF="/usr/local/mpiBLAST/etc/mpiblast.conf";
下一个更改涉及对一系列 if 语句的更改。这些语句为 nt、nr 和 pdb 数据库硬编码 NUMPROC 环境变量。由于数据库需要由 mpiBLAST 预先格式化,因此每个查询使用的处理器数量是恒定的。我们将默认数量从 20 更改为 16,这是我们使用的处理器数量
if($data{'DATALIB'} eq "nt"){
$data{'NUMPROC'} = 16;
}
在脚本的更下方,定义了 ValidateFormData 子例程。此子例程确保用户选择了有效的数据库/程序组合,如果未选择有效的组合,则生成 500 服务器错误。我们更改了子例程,以允许 tblastx 程序对 nr 数据库执行查询,方法是进行以下更改
#### BEFORE ####
# Must be applied to a nucleotide database
if($data_ref->{'DATALIB'} ne "nt"){
#### AFTER ####
# Must be applied to a nucleotide database
if($data_ref->{'DATALIB'} ne "nt" ||
$data_ref->{'DATALIB'} ne "nr"){
稍后,脚本为 mpiBLAST 创建一个命令行参数字符串,并将其存储在变量 $c_line 中。我们需要更改传递给 -d 选项的值,该选项告诉 mpiBLAST 要搜索哪个数据库。默认情况下,WWWBlastwrap.pl 将处理器数量连接到数据库名称,并将结果传递给 -d 选项。因此,如果我们的数据库名为 nr 并且我们有 16 个处理器,它将传递 nr16。据推测,这样做是为了允许搜索数据库的多个版本,即用于 16 段数据库的 nr16 和用于 8 段数据库的 nr8。您可以以这种方式命名数据库,也可以修改脚本。由于我们只有一个版本的数据库,因此我们选择修改脚本,从数据库名称中删除处理器数量。代码更改总结如下
#### BEFORE ####
# Create the command line to pass to mpiBlast my
$c_line = "-d $data_ref->{'DATALIB'}" .
"$data_ref->{'NUMPROC'} " .
"-p $data_ref->{'PROGRAM'} " .
#### AFTER ####
# Create the command line to pass to mpiBlast my
$c_line = "-d $data_ref->{'DATALIB'} " .
"-p $data_ref->{'PROGRAM'} " .
在运行测试查询时,我们收到几个lcl|tmpseq_0: 无法打开 BLOSUM62OpenPBS 错误日志中的警告。将环境变量 BLASTMAT 指向 BLAST 矩阵的位置可以消除这些警告,因此我们进行了以下更改
#### BEFORE ####
print SCRIPTFILE '#PBS -e '.
"$data_ref->{'ERROR_LOG_FILE'}\n\n";
print SCRIPTFILE 'if(-e $ENV{PBS_NODEFILE} ){'."\n";
#### AFTER ####
print SCRIPTFILE '#PBS -e '.
"$data_ref->{'ERROR_LOG_FILE'}\n\n";
print SCRIPTFILE '$ENV{BLASTMAT} = '.
'"/usr/local/ncbi/data";'."\n";
print SCRIPTFILE 'if(-e $ENV{PBS_NODEFILE} ){'."\n";
我们在脚本末尾的 HtmlResults 子例程中遇到了最终的更改。将用户定向到结果的代码使用默认基本 URL,这几乎肯定不是您想要的。将基本 URL 更改为指向我们的 Web 服务器允许客户端的 Web 浏览器显示 BLAST 查询的结果
#### BEFORE #### print "Location: https://jojo.lanl.gov/blast/". "BlastResults/$results_file\n\n"; #### AFTER #### print "Location: http://domain_name/BlastResults". "/$results_file\n\n";
与 NCBI 网站相比,我们的本地集群能够搜索更新的数据库,并发用户更少,总体吞吐量时间更好。使用我们的集群和 NCBI 网站进行了简单的挂钟时间试验。我们使用了八个简单的查询,包括蛋白质和 DNA 序列。从 Web 站点提交查询后启动计时器,并在浏览器窗口中显示结果后停止计时器。NCBI 网站上的试验在两周的不同时间进行。所有八次试验取平均值并与集群的时间进行比较。从提交查询到显示结果的时间点计时查询的目的是观察实际用户将花费的时间。平均而言,集群完成查询所需的时间更少。

图 5. 我们的集群由 17 台回收的 PC 组成,提高了用户查询的响应时间。
本文的资源: /article/8140。
Josh Stroschein (jstrosch@usd.edu) 目前正在攻读计算机科学和刑事司法的本科学位。Josh 正在通过 USD 的一项资助从事集群项目。他还为位于南达科他州弗米利恩的 Walton Internet Solutions 工作。
Doug Jennewein (djennewe@usd.edu) 是计算机科学领域的研究分析师,自 1998 年以来一直在 USD 工作。他于 2004 年在 USD 获得计算机科学硕士学位。Doug 的主要研究兴趣是高性能计算。
Joe Reynoldson (jreynold@usd.edu) 是计算机科学系的研究计算经理/讲师,自 1994 年以来一直在 USD 工作。他于 1997 年在 USD 获得计算机科学硕士学位。Joe 教授 Perl、系统管理和 Web 开发方面的课题。
