
现代微处理器中的内存排序,第一部分
自 2.0 内核版本发布以来,Linux 已经支持了大量基于各种 CPU 的 SMP 系统。Linux 在抽象这些 CPU 之间的差异方面做得非常出色,即使在内核代码中也是如此。本文概述了一个重要的差异:CPU 如何允许在 SMP 系统中重新排序内存访问。
内存访问是 CPU 运算中最慢的操作之一,这是因为摩尔定律提高 CPU 指令性能的速度远高于提高内存性能的速度。这种性能提升的差异意味着,与简单的寄存器到寄存器指令相比,内存操作变得越来越昂贵。现代 CPU 配备了越来越大的缓存,以减少这些昂贵内存访问的开销。
这些缓存可以被认为是简单的硬件哈希表,具有固定大小的桶且没有链接,如图 1 所示。此缓存有 16 行和两条路,总共有 32 个条目,每个条目包含一个 256 字节的缓存行,这是一个 256 字节对齐的内存块。此缓存行大小有点大,但它使十六进制算术更加简单。在硬件术语中,这是一个双路组相联缓存。它类似于一个具有 16 个桶的软件哈希表,其中每个桶的哈希链最多限制为两个元素。由于此缓存是在硬件中实现的,因此哈希函数非常简单:从内存地址中提取四个位。
在图 1 中,每个框对应于一个可以包含 256 字节缓存行的缓存条目。但是,缓存条目可以是空的,如图中的空框所示。其余的框都标记了它们包含的缓存行的内存地址。由于缓存行必须是 256 字节对齐的,因此每个地址的低八位都为零。硬件哈希函数的选择意味着接下来的四个高位与行号匹配。
图 1 中描述的情况可能会在程序代码位于地址 0x43210E00 到 0x43210EFF 之间,并且该程序从 0x12345000 到 0x12345EFF 顺序访问数据时出现。假设程序现在要访问位置 0x12345F00。此位置哈希到行 0xF,并且此行的两条路都为空,因此可以容纳相应的 256 字节行。如果程序要访问位置 0x1233000,它哈希到行 0x0,则相应的 256 字节缓存行可以容纳在路 1 中。但是,如果程序要访问位置 0x1233E00,它哈希到行 0xE,则必须从缓存中逐出一个现有行,以便为新的缓存行腾出空间。关于硬件缓存的这些背景知识使我们能够了解 CPU 为什么要重新排序内存访问。
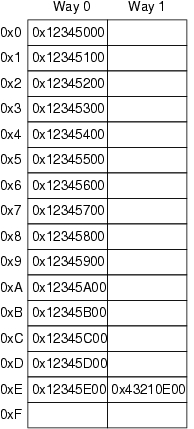
图 1. 具有 16 行和每行两个条目的缓存的 CPU 缓存结构
简而言之,性能! CPU 变得如此之快,以至于大型兆兆字节缓存无法跟上它们的速度。因此,缓存通常被划分为几乎独立的库,如图 2 所示。这允许每个库并行运行,从而更好地跟上 CPU 的速度。内存通常按地址在缓存库之间划分。例如,所有偶数编号的缓存行可能由库 0 处理,而所有奇数编号的缓存行可能由库 1 处理。
然而,这种硬件并行性有一个阴暗面:内存操作现在可以乱序完成,这可能会导致一些混乱,如图 3 所示。CPU 0 可能首先写入位置 0x12345000(偶数编号的缓存行),然后写入位置 0x12345100(奇数编号的缓存行)。如果库 0 正忙于较早的请求,但库 1 处于空闲状态,则在第二次写入之后,CPU 1 可以看到第一次写入。换句话说,CPU 1 认为写入是乱序的。读取可以以类似的方式重新排序。这种重新排序可能导致许多教科书式的并行算法失败。

图 2. 硬件并行性将一个大型缓存划分为多个库。
少数机器提供顺序一致性,其中所有操作都按照代码指定的顺序发生,并且所有 CPU 对这些操作的视图都与组合操作的全局排序一致。顺序一致性系统具有一些不错的特性,但高性能往往不是其中之一。对全局排序的需求严重限制了硬件利用并行性的能力,因此,商品 CPU 和系统不提供顺序一致性。
在这些系统中,必须考虑三种排序
程序顺序:内存操作在给定 CPU 上运行的代码中指定的顺序。
执行顺序:单个内存引用指令在给定 CPU 上执行的顺序。由于编译器和 CPU 实现优化,执行顺序可能与程序顺序不同。
感知顺序:给定 CPU 感知自身和其他 CPU 的内存操作的顺序。由于缓存、互连和内存系统优化,感知顺序可能与执行顺序不同。不同的 CPU 很可能认为相同的内存操作以不同的顺序发生。

图 3. CPU 可以乱序执行操作。
流行的内存一致性模型包括 x86 的进程一致性,其中来自给定 CPU 的写入对所有 CPU 都是按顺序可见的,以及弱一致性,它允许任意重新排序,但仅受显式内存屏障指令的限制。有关内存一致性模型的更多信息,请参阅 Gharachorloo 的详尽技术报告,该报告在在线资源中列出。
当谈到内存排序在不同 CPU 上的工作方式时,有好消息也有坏消息。坏消息是每个 CPU 的内存排序都略有不同。好消息是您可以指望以下几点
给定 CPU 始终认为其自身的内存操作以程序顺序发生。也就是说,内存重排序问题仅在 CPU 观察其他 CPU 的内存操作时才会出现。
仅当操作访问与存储不同的位置时,操作才会与存储重新排序。
对齐的简单加载和存储是原子的。
Linux 内核同步原语包含任何所需的内存屏障,这是使用这些原语的一个很好的理由。
最重要的差异在表 1 中列出。有关特定 CPU 功能的更详细描述将在以后的文章中介绍。括号中的 CPU 名称表示架构上允许但在实践中很少使用的模式。标有 Y 的单元格表示弱内存排序;Y 越多,重新排序的可能性就越大。一般来说,将 SMP 代码从具有许多 Y 的 CPU 移植到具有较少 Y 的 CPU 更容易,尽管结果可能会有所不同。但是,使用标准同步原语(自旋锁、信号量、RCU)的代码不需要显式内存屏障,因为这些原语中已经存在任何必需的屏障。只有绕过这些同步原语的棘手代码才需要屏障。重要的是要注意,大多数原子操作,例如 atomic_inc() 和 atomic_add(),都不包含任何内存屏障。
在表 1 中,前四列指示给定 CPU 是否允许重新排序加载和存储的四种可能组合。接下来的两列指示给定 CPU 是否允许使用原子指令重新排序加载和存储。仅使用八个 CPU,我们就有了五种不同的加载-存储重新排序组合和四种可能的原子指令重新排序中的三种。
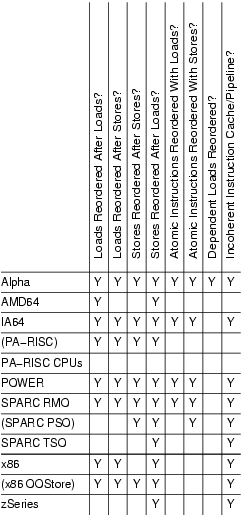
表 1. 内存排序总结
倒数第二列“依赖读取重新排序”需要一些解释,这将在本系列的第二部分中进行。简短的版本是 Alpha 要求读者以及链接数据结构的更新者使用内存屏障。是的,这确实意味着 Alpha 实际上可以在获取指针本身之前获取指针指向的数据——这很奇怪但却是事实。如果您认为我在编造这个,请参阅制造商网站上的“Ask the Wizard”专栏,该专栏在资源中列出。这种极弱内存模型的好处是 Alpha 可以使用更简单的缓存硬件,这反过来又允许 Alpha 全盛时期更高的时钟频率。
表 1 中的最后一列指示给定 CPU 是否具有不连贯的指令缓存和流水线。此类 CPU 要求为自修改代码执行特殊指令。在没有这些指令的情况下,CPU 可能会执行旧版本的代码而不是新版本的代码。这可能看起来并不重要——毕竟,现在谁还编写自修改代码?答案是每个 JIT 都在这样做。此类 CPU 的 JIT 代码生成器的编写者必须特别注意在尝试执行任何新生成的代码之前刷新指令缓存和流水线。这些 CPU 还要求 exec() 和 page-fault 代码在尝试执行刚刚读入内存的任何二进制文件之前刷新指令缓存和流水线,以免 CPU 最终执行受影响页面的先前内容。
Linux 的一大优势是它可以运行在各种不同的 CPU 上。不幸的是,正如我们所看到的,这些 CPU 具有各种各样的内存一致性模型。那么,可移植内核应该怎么做呢?
Linux 提供了一组精心选择的内存屏障原语,如下所示
smp_mb():“内存屏障”,用于对加载和存储进行排序。这意味着在内存屏障之前的加载和存储在内存屏障之后的任何加载和存储之前提交到内存。
smp_rmb():“读取内存屏障”,仅对加载进行排序。
smp_wmb():“写入内存屏障”,仅对存储进行排序。
smp_read_barrier_depends():强制对依赖于先前操作的后续操作进行排序。此原语在除 Alpha 之外的所有平台上都是空操作。
smp_mb()、smp_rmb() 和 smp_wmb() 原语还强制编译器避免任何会产生跨屏障重新排序内存优化的效果的优化。smp_read_barrier_depends() 原语也必须这样做,但仅在 Alpha CPU 上。
这些原语仅在 SMP 内核中生成代码;但是,每个原语也都有一个 UP 版本——mb()、rmb()、wmb() 和 read_barrier_depends()——即使在 UP 内核中也会生成内存屏障。在大多数情况下,应使用 smp_ 版本。但是,后一种原语在编写驱动程序时很有用,因为即使在 UP 内核中,内存映射 I/O 访问也必须保持有序。在没有内存屏障指令的情况下,CPU 和编译器都会很高兴地重新排列这些访问。往好了说,这会使设备行为异常;往坏了说,它会使您的内核崩溃,或者在某些情况下,甚至会损坏您的硬件。
因此,大多数内核程序员无需担心每个 CPU 的内存屏障特性,只要他们坚持使用这些内存屏障接口即可。如果您深入研究给定 CPU 的特定于架构的代码,那么当然,一切都无法保证了。
但情况会更好。Linux 的所有锁定原语,包括自旋锁、读写锁、信号量和读取-复制更新 (RCU),都包含任何所需的屏障原语。因此,如果您正在使用使用这些原语的代码,您甚至无需担心 Linux 的内存排序原语。也就是说,深入了解每个 CPU 的内存一致性模型在调试时可能会有所帮助,更不用说编写特定于架构的代码或同步原语了。
此外,他们说少量的知识是危险的。想象一下,如果您掌握了大量的知识,可能会造成多大的破坏!对于那些想要更多地了解各个 CPU 的内存一致性模型的人,下一篇文章将介绍最流行和最著名的 CPU 的模型。
如前所述,好消息是 Linux 的内存排序原语和同步原语使大多数 Linux 内核黑客无需担心内存屏障。考虑到 Linux 支持的大量 CPU 和系统以及由此产生的各种内存一致性模型,这尤其是一个好消息。但是,有时了解内存屏障可能会有所帮助,我希望本文能很好地介绍它们。
我感谢许多 CPU 架构师耐心解释其 CPU 的指令和内存重排序功能,特别是 Wayne Cardoza、Ed Silha、Anton Blanchard、Tim Slegel、Juergen Probst、Ingo Adlung 和 Ravi Arimilli。特别感谢 Wayne 耐心解释 Alpha 的依赖加载重排序,我曾非常强烈地抵制学习这一课!
这项工作代表作者的观点,不一定代表 IBM 的观点。IBM、zSeries 和 Power PC 是 International Business Machines Corporation 在美国、其他国家或地区的商标或注册商标。Linux 是 Linus Torvalds 的注册商标。i386 是 Intel Corporation 或其在美国、其他国家或地区的分公司的商标。其他公司、产品和服务名称可能是这些公司的商标或服务标志。版权所有 (c) 2005 IBM Corporation。
本文的资源: /article/8331。
Paul E. McKenney 是 IBM Linux 技术中心的杰出工程师。他从事 NUMA 和 SMP 算法的研究,特别是 RCU 的研究时间比他愿意承认的要长。在业余时间,他慢跑并维持着通常的家庭主妇和孩子的生活习惯。
