
现代微处理器中的内存排序,第二部分
本系列的第一部分概述了内存屏障、SMP内核中为什么需要内存屏障以及Linux内核如何处理它们[2005年8月]。 本部分概述了几种更流行的CPU(Alpha、AMD64、IA64、PA-RISC、POWER、SPARC、x86 和 zSeries,又称 IBM 大型机)如何实现内存屏障。表 1 从本系列的第一部分复制于此处,以供参考。
谈论一款已宣布生命周期结束的 CPU 似乎很奇怪,但 Alpha 很有趣,因为它具有最弱的内存排序模型,可以最积极地重新排序内存操作。 因此,它定义了必须在所有 CPU 上运行的 Linux 内核内存排序原语。 因此,理解 Alpha 对于 Linux 内核黑客来说非常重要。
Alpha 与其他 CPU 之间的区别通过清单 1 中显示的代码来说明。 第 9 行的 smp_wmb() 保证第 6-8 行中的元素初始化在第 10 行的元素添加到列表之前执行,以便无锁搜索能够正确工作。 也就是说,它对除 Alpha 之外的所有 CPU 做出此保证。
Alpha 具有极弱的内存排序,因此清单 1 第 20 行的代码可能会看到第 6-8 行初始化之前存在的旧垃圾值。
图 1 显示了这种情况如何在具有分区缓存的高度并行机器上发生,从而使交替的缓存行由缓存的不同分区处理。 假设列表头 head 由缓存库 0 处理,新元素由缓存库 1 处理。 在 Alpha 上,smp_wmb() 保证清单 1 第 6-8 行执行的缓存失效先于第 10 行的缓存失效到达互连。 但是,它绝对不保证新值到达读取 CPU 内核的顺序。 例如,读取 CPU 的缓存库 1 可能很忙,而缓存库 0 处于空闲状态。 这可能会导致新元素的缓存失效被延迟,从而使读取 CPU 获得指向新值的指针,但看到新元素的旧缓存值。
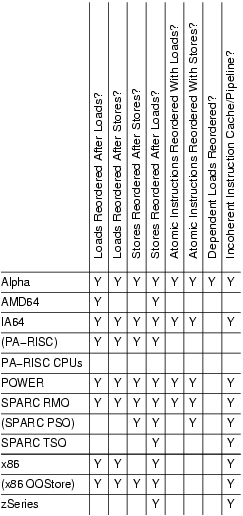
表 1. 内存排序摘要
可以在指针提取和解引用之间放置一个 smp_rmb() 原语。 但是,这会对 x86、IA64、PPC 和 SPARC 等系统施加不必要的开销,这些系统尊重读取端的数据依赖性。 Linux 2.6 内核中添加了一个 smp_read_barrier_depends() 原语,以消除这些系统上的开销。 此原语可以如清单 2 第 19 行所示使用。但是,请注意 RCU 代码应使用 rcu_dereference() 代替。
也可以实现一个软件屏障来代替 smp_wmb(),这将强制所有读取 CPU 按顺序查看写入 CPU 的写入。 但是,Linux 社区认为这种方法对极弱排序的 CPU(例如 Alpha)施加了过度的开销。 此软件屏障可以通过向所有其他 CPU 发送处理器间中断 (IPI) 来实现。 收到此类 IPI 后,CPU 将执行内存屏障指令,实现内存屏障射击。 需要额外的逻辑来避免死锁。 当然,尊重数据依赖性的 CPU 会将此类屏障简单地定义为 smp_wmb()。 也许当 Alpha 逐渐退出历史舞台时,应该重新审视这个决定。
清单 1. 插入和无锁搜索
1 struct el *insert(long key, long data)
2 {
3 struct el *p;
4 p = kmalloc(sizeof(*p), GPF_ATOMIC);
5 spin_lock(&mutex);
6 p->next = head.next;
7 p->key = key;
8 p->data = data;
9 smp_wmb();
10 head.next = p;
11 spin_unlock(&mutex);
12 }
13
14 struct el *search(long key)
15 {
16 struct el *p;
17 p = head.next;
18 while (p != &head) {
19 /* BUG ON ALPHA!!! */
20 if (p->key == key) {
21 return (p);
22 }
23 p = p->next;
24 };
25 return (NULL);
26 }
Linux 内存屏障原语的名称取自 Alpha 指令,因此 smp_mb() 是 mb,smp_rmb() 是 rmb,smp_wmb() 是 wmb。 Alpha 是唯一一个 smp_read_barrier_depends() 是 smp_mb() 而不是空操作的 CPU。 有关 Alpha 的更多详细信息,请参阅在线资源中列出的参考手册。
虽然 AMD64 与 x86 兼容,但它提供了稍微更强的内存一致性模型,因为它不会将存储重新排序到加载之前。 毕竟,加载速度很慢且无法缓冲,那么为什么要将存储重新排序到加载之前呢? 虽然理论上可以创建一个在某些 x86 CPU 上运行但在 AMD64 上由于内存一致性模型的这种差异而失败的并行程序,但在实践中,这种差异对将代码从 x86 移植到 AMD64 几乎没有影响。
Linux smp_mb() 原语的 AMD64 实现是 mfence,smp_rmb() 是 lfence,smp_wmb() 是 sfence。

图 1. 为什么需要 smp_read_barrier_depends()
IA64 提供了弱一致性模型,因此在没有显式内存屏障指令的情况下,IA64 有权任意重新排序内存引用。 IA64 有一个名为 mf 的内存屏障指令,以及一个半内存屏障修饰符,用于加载和存储其某些原子指令。 acq 修饰符阻止后续的内存引用指令在 acq 之前重新排序,但它允许之前的内存引用指令在 acq 之后重新排序,如图 2 生动地说明的那样。 类似地,rel 修饰符阻止之前的内存引用指令在 rel 之后重新排序,但它允许后续的内存引用指令在 rel 之前重新排序。
这些半内存屏障对于临界区非常有用,因为将操作推入临界区是安全的。 但是,允许它们泄漏出去可能是致命的。
IA64 mf 指令用于 Linux 内核中的 smp_rmb()、smp_mb() 和 smp_wmb() 原语。 哦,尽管长期以来谣言不断,但 mf 助记符确实代表内存屏障。
虽然 PA-RISC 架构允许完全重新排序加载和存储,但实际的 CPU 完全有序运行。 这意味着 Linux 内核的内存排序原语不生成任何代码; 但是,它们使用 GCC 内存属性来禁用编译器优化,否则这些优化会将代码跨内存屏障重新排序。
清单 2. 安全插入和无锁搜索
1 struct el *insert(long key, long data)
2 {
3 struct el *p;
4 p = kmalloc(sizeof(*p), GPF_ATOMIC);
5 spin_lock(&mutex);
6 p->next = head.next;
7 p->key = key;
8 p->data = data;
9 smp_wmb();
10 head.next = p;
11 spin_unlock(&mutex);
12 }
13
14 struct el *search(long key)
15 {
16 struct el *p;
17 p = head.next;
18 while (p != &head) {
19 smp_read_barrier_depends();
20 if (p->key == key) {
21 return (p);
22 }
23 p = p->next;
24 };
25 return (NULL);
26 }
POWER 和 PowerPC CPU 系列具有各种各样的内存屏障指令
sync 使所有之前的指令(不仅是内存引用)看起来在任何后续操作开始之前都已完成。 因此,此指令非常昂贵。
lwsync 或轻量级同步,按顺序排列负载与后续的负载和存储,并且还按顺序排列存储。 但是,它不按顺序排列存储与后续负载。 有趣的是,lwsync 指令强制执行的排序与 zSeries 和 SPARC TSO 一致。
eieio,强制按顺序执行 I/O,以防您想知道,使所有之前的可缓存存储(即正常的内存引用)看起来在所有后续可缓存存储之前都已完成。 它还使所有之前的不可缓存的内存映射 I/O (MMIO) 存储看起来在所有后续不可缓存存储之前都已完成。 但是,对可缓存内存的存储与对不可缓存内存的存储分开排序,例如,这意味着 eieio 不会强制 MMIO 存储先于自旋锁释放。
isync 强制所有之前的指令看起来在任何后续指令开始执行之前都已完成。 这意味着之前的指令必须已取得足够的进展,以至于它们可能生成的任何陷阱要么已经发生,要么保证不会发生。 此外,这些指令的任何副作用(例如,页表更改)都将被后续指令看到。
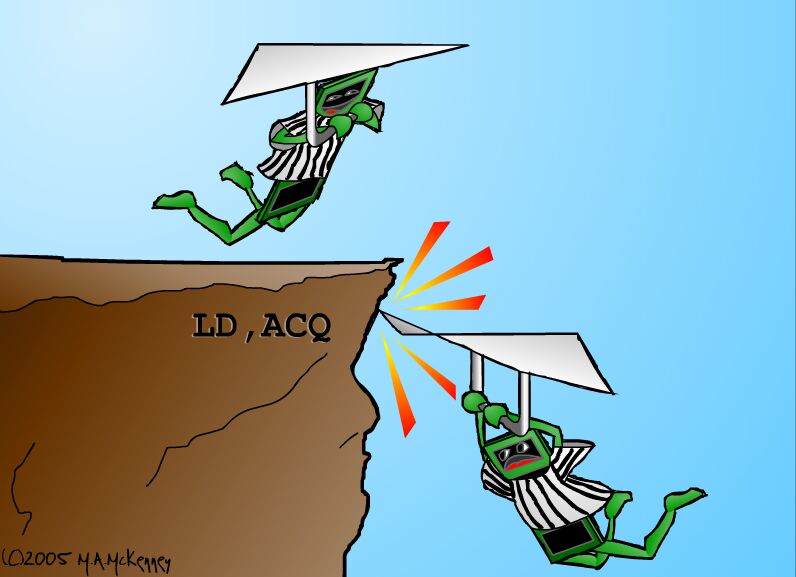
图 2. 半内存屏障
不幸的是,这些指令中没有一个与 Linux 的 wmb() 原语完全一致,后者要求所有存储都按顺序排列。 它不需要 sync 指令的其他高开销操作。 但是别无选择:ppc64 版本的 wmb() 和 mb() 被定义为重量级 sync 指令。 但是,Linux 的 smp_wmb() 原语不能用于 MMIO,因为驱动程序必须小心地在 UP 以及 SMP 内核中按顺序排列 MMIO。 因此,它被定义为更轻量级的 eieio 指令,这可能是唯一具有五个元音助记符的指令。 smp_mb() 原语也被定义为 sync 指令,但 smp_rmb() 和 rmb() 都被定义为更轻量级的 lwsync 指令。
POWER 架构的许多成员都具有不一致的指令缓存,因此对内存的存储不一定反映在指令缓存中。 值得庆幸的是,现在很少有人编写自修改代码,但 JIT 一直在这样做。 此外,从 CPU 的角度来看,重新编译最近运行的程序看起来像自修改代码。 icbi 指令,指令缓存块无效,使指令缓存中指定的缓存行无效,并且可以在这些情况下使用。
SPARC 上的 Solaris 使用全存储顺序 (TSO); 但是,Linux 在宽松内存顺序 (RMO) 模式下运行 SPARC。 SPARC 架构还提供中间的部分存储顺序 (PSO)。 在 RMO 中运行的任何程序也可以在 PSO 或 TSO 中运行。 类似地,在 PSO 中运行的程序也可以在 TSO 中运行。 在另一个方向上移动共享内存并行程序可能需要仔细插入内存屏障; 尽管如前所述,标准使用同步原语的程序无需担心内存屏障。
SPARC 具有灵活的内存屏障指令,允许对排序进行细粒度控制
StoreStore:按顺序排列之前的存储在后续存储之前。 Linux smp_wmb() 原语使用此选项。
LoadStore:按顺序排列之前的加载在后续存储之前。
StoreLoad:按顺序排列之前的存储在后续加载之前。
LoadLoad:按顺序排列之前的加载在后续加载之前。 Linux smp_rmb() 原语使用此选项。
Sync:在开始任何后续操作之前完全完成所有之前的操作。
MemIssue:在后续内存操作之前完成之前的内存操作,这对于某些内存映射 I/O 实例很重要。
Lookaside:与 MemIssue 相同,但仅适用于之前的存储和后续的加载,甚至仅适用于访问相同内存位置的存储和加载。
Linux smp_mb() 原语将前四个选项一起使用,如下所示
membar #LoadLoad | #LoadStore | #StoreStore | #StoreLoad
这完全按顺序排列内存操作。
那么,为什么需要 membar #MemIssue 呢? 因为 membar #StoreLoad 可能允许后续加载从写入缓冲区获取其值,如果写入转到 MMIO 寄存器,这将是灾难性的,因为 MMIO 寄存器会在要读取的值上引起副作用。 相比之下,membar #MemIssue 将等待直到写入缓冲区刷新,然后再允许加载执行,从而确保加载实际上从 MMIO 寄存器获取其值。 驱动程序可以改为使用 membar #Sync,但在不需要更昂贵的 membar #Sync 的附加功能的情况下,首选更轻量级的 membar #MemIssue。
membar #Lookaside 是 membar #MemIssue 的更轻量级版本,当写入给定的 MMIO 寄存器会影响接下来从同一寄存器读取的值时,它很有用。 但是,当写入给定的 MMIO 寄存器会影响接下来从其他 MMIO 寄存器读取的值时,必须使用更重量级的 membar #MemIssue。
目前尚不清楚为什么 SPARC 不将 wmb() 定义为 membar #MemIssue,将 smb_wmb() 定义为 membar #StoreStore,因为当前的定义似乎容易受到某些驱动程序中的错误的影响。 Linux 运行的所有 SPARC CPU 都可能实现比架构允许的更保守的内存排序模型。
SPARC 要求在存储和执行指令之间使用 flush 指令。 这是为了从 SPARC 的指令缓存中刷新该位置的任何先前值。 请注意,flush 接受一个地址,并且仅从指令缓存中刷新该地址。 在 SMP 系统上,所有 CPU 的缓存都会被刷新,但是没有方便的方法来确定异地 CPU 刷新何时完成,尽管有对实现说明的引用。
x86 CPU 提供进程排序,以便所有 CPU 就给定 CPU 对内存的写入顺序达成一致,因此 smp_wmb() 原语对于 CPU 来说是空操作。 但是,需要编译器指令来防止编译器执行优化,否则这些优化会导致跨 smp_wmb() 原语重新排序。
另一方面,x86 CPU 不为加载提供排序保证,因此 smp_mb() 和 smp_rmb() 原语扩展为 lock;addl。 此原子指令充当加载和存储的屏障。 一些 SSE 指令的排序较弱; 例如,clflush 和非临时移动指令。 具有 SSE 的 CPU 可以使用 mfence 作为 smp_mb(),lfence 作为 smp_rmb(),sfence 作为 smp_wmb()。 少数版本的 x86 CPU 具有启用乱序存储的模式位,对于这些 CPU,smp_wmb() 也必须定义为 lock;addl。
虽然许多较旧的 x86 实现无需任何特殊指令即可容纳自修改代码,但较新版本的 x86 架构不再要求 x86 CPU 如此容纳。 有趣的是,这种放松恰好及时地给 JIT 实现者带来了不便。
zSeries 机器构成了 IBM 大型机系列,以前称为 360、370 和 390。 并行性在 zSeries 中出现较晚,但考虑到这些大型机在 1960 年代中期首次出货,这也没什么好说的。 bcr 15,0 指令用于 Linux smp_mb()、smp_rmb() 和 smp_wmb() 原语。 它还具有相对较强的内存排序语义,如表 1 所示。这应该允许 smp_wmb() 原语成为空操作,并且当您阅读本文时,此更改可能已经发生。
与大多数 CPU 一样,zSeries 架构不保证缓存一致的指令流。 因此,自修改代码必须在更新指令和执行指令之间执行序列化指令。 也就是说,许多实际的 zSeries 机器实际上确实在没有序列化指令的情况下容纳自修改代码。 zSeries 指令集提供了一大组序列化指令,包括比较和交换、某些类型的分支(例如,前面提到的 bcr 15,0 指令)和测试和设置等等。
我感谢许多 CPU 架构师耐心解释其 CPU 的指令和内存重新排序功能,特别是 Wayne Cardoza、Ed Silha、Anton Blanchard、Tim Slegel、Juergen Probst、Ingo Adlung 和 Ravi Arimilli。 Wayne 特别值得感谢他在解释 Alpha 相关的负载重新排序方面的耐心,我曾非常强烈地抵制这一课!
这项工作代表了作者的观点,不一定代表 IBM 的观点。 IBM、zSeries 和 PowerPC 是 International Business Machines Corporation 在美国、其他国家或两者的商标或注册商标。 Linux 是 Linus Torvalds 的注册商标。 i386 是 Intel Corporation 或其子公司在美国、其他国家或两者的商标。 其他公司、产品和服务名称可能是此类公司的商标或服务标志。 版权所有 (c) 2005 IBM Corporation。
本文的资源: /article/8406。
Paul E. McKenney 是 IBM Linux 技术中心的杰出工程师。 他从事 NUMA 和 SMP 算法的研究,尤其是 RCU 的研究,时间之久甚至他自己都不愿承认。 在业余时间,他会慢跑并养家糊口。
