
异构处理:增强摩尔定律的策略
更好的应用程序性能:每个人都想要它,而在高性能计算 (HPC) 领域,我们已经习以为常。也许我们甚至有点被宠坏了。毕竟,得益于摩尔定律,我们已经享受了四十年的持续性能提升。
如今,这项原则(预测晶体管密度每 18 个月翻一番)已进入第 40 个年头,并且仍然强劲。但不幸的是,不断增加的晶体管密度不再带来应用程序性能的相应提升。造成这种情况的原因是众所周知的。增加晶体管也会增加线路延迟和速度到内存的问题。更激进的单核设计也必然导致更大的复杂性和热量。最后,标量处理器本身也存在一个根本性的限制:基于串行执行的设计,这使得从应用程序代码中提取更多的指令级并行性 (ILP) 变得极其困难。
如果这些问题曾经只是少数高端用户的担忧,那么现在已经不再是了。越来越明显的是,重大的性能提升可能会对几乎每个科学领域产生深远的影响。总统信息技术咨询委员会挑战 HPC 研究人员到 2010 年在实际应用中实现持续的千万亿次浮点运算,并指出万万亿次浮点运算系统对于改进天气和气候预报、制造业、药物开发和其他战略应用至关重要。Petaflops II 等会议上的行业专家正在要求改进一系列应用,包括碰撞测试、先进的飞机和航天器设计、经济建模以及对抗流行病和生物恐怖主义。
HPC 社区正在通过开发新的策略来增强摩尔定律,并探索创新的 HPC 架构,以绕过传统系统的局限性来做出回应。这些策略包括
多核系统,它在一个芯片上使用两个或多个内核,以继续提供稳定的性能提升。
专用处理器,在传统通用处理器表现不佳的领域提供增强的性能。
异构计算架构,其中传统处理器和专用处理器协同工作。
这些策略中的每一种都可能带来显着的性能提升。在 Cray,我们正在探索所有这三种策略。但从长远来看,我们相信异构计算具有巨大的潜力,可以超越人们对摩尔定律的预期来加速应用程序,同时克服许多可能限制传统架构的障碍。作为 DARPA 高生产力计算系统计划的参与者,我们预计异构处理将在未来几年变得至关重要。
在一个芯片上放置多个内核是在摩尔定律的框架下实现持续性能提升的最快方法。多核处理器的一个众所周知的例子是双核 AMD Opteron。
Cray 和其他 HPC 制造商已经接受了这种模式。今天,Cray 正在交付双核系统,并期望在未来利用更多的内核。该策略在降低每个处理器的功耗和热量的同时,立即将计算密度提高一倍。
对于许多应用程序(尤其是那些需要大量浮点运算的应用程序),多核处理将在可预见的未来提供性能提升,并且该模型很可能成为摩尔定律得以维持的主要工具。然而,对于某些应用程序(特别是那些依赖于大量位操作、排序和信号处理的应用程序,例如数据库搜索、音频/视频/图像处理以及加密/解密),摩尔定律可能还不够。只有通过处理速度比当今(或在不久的将来可能通过传统处理器获得的)快几个数量级,才能实现这些应用程序的重大进步。因此,HPC 研究人员正在探索替代模型。
近年来,基于商品处理器集群的架构在 HPC 领域超越了高端专用系统,这归功于它们的低成本和许多应用程序的可靠性能。但是,随着一些用户开始遇到标量处理的固有局限性,我们开始看到这种趋势的逆转。这种复兴的例子包括
向量处理器:向量处理器通过有效地流水线化对大数据流的相同计算来提高计算性能,从而消除了传统处理器的指令发布速率限制。
多线程处理器:HPC 内存速度的增长速度仅为处理器速度增长速度的一小部分,这导致了性能瓶颈,因为串行处理器需要等待内存。结合了多线程处理器的系统(例如 IBM 的同步多线程处理器和英特尔的超线程技术)通过修改处理器架构以同时执行多个线程,同时共享内存和带宽资源来解决此问题。Cray 的多线程架构更进一步,允许数十个活动线程同时运行,充分利用内存带宽。
数字信号处理器 (DSP):DSP 针对处理连续信号进行了优化,使其非常适用于音频、视频和雷达应用。它们的低功耗也使这些处理器非常适合用于等离子电视、手机和其他嵌入式设备。
专用协处理器:诸如 Clearspeed Technology 开发的浮点加速器和 n 体加速器 GRAPE 等协处理器,使用独特的阵列处理器架构,每个芯片提供大量的浮点组件(乘法/加法单元)。它们可以在数学密集型函数(例如矩阵乘法或求逆或求解 n 体问题)上提供明显的改进。
在某些操作中,这些处理器可以提供比通用处理器好得多的性能。向量处理器和多线程处理器也具有延迟容忍性,即使在允许大量内存引用同时进行的情况下,也可以继续执行指令。这些增强功能可以显着提高应用程序性能,同时减少传统缓存策略所需的芯片上的互缓存通信负担和实际面积。
然而,正如传统部署的专用处理器一样,它们也有严重的局限性。首先,尽管它们可以为某些操作提供出色的加速,但它们通常比商品处理器运行标量代码的速度慢得多——而现实世界中使用的大多数软件至少使用一些标量代码。为了解决这个问题,这些处理器传统上是通过 PCI 总线(基本上是作为外围设备)集成到更传统的系统中的。这种不足的通信带宽严重限制了可以实现的加速。(将结果返回到传统系统实际上可能比计算本身花费更多的时间。)处理器制造也存在严峻的经济现实。除非处理器具有完善的市场利基,可以支持商品生产(例如 DSP 在消费电子产品中的适用性),否则很少有制造商愿意承担将新设计推向市场的巨额成本。
这些问题正促使 Cray 和其他公司探索替代模型。
异构计算是在单个工作流程中部署多种类型的处理元件的策略,并允许每个元件执行最适合它的任务。该模型可以利用上述专用处理器(以及其他处理器)来加速某些操作,速度比标量处理器快 100 倍,同时扩展传统微处理器架构的适用性。由于许多 HPC 应用程序既包含可以从加速中受益的代码,又包含更适合传统处理的代码,因此没有一种类型的处理器最适合所有计算。异构处理允许在给定应用程序中为每个操作选择正确的处理器类型。
传统上,异构架构的广泛采用存在两个主要障碍:跨多个处理器分配工作负载所需的编程复杂性,以及如果这些处理器类型不同,则需要额外的努力。这些问题可能相当大,并且异构方法的任何潜在优势都必须与克服这些问题所需的成本和资源进行权衡。但是今天,多核系统的兴起已经造成了技术上的不连续性,这将影响程序员看待 HPC 软件的方式,并为新的编程策略和环境打开大门。随着软件设计人员越来越习惯于为多个处理器编程,他们可能会更愿意考虑其他类型的架构,包括异构系统。并且现在正在涌现几个新的异构系统。
例如,Cray X1E 超级计算机结合了向量处理和标量处理,以及一个专门的编译器,可以自动在处理器之间分配工作负载。在新的 Cell 处理器架构(由 IBM、索尼和东芝设计,旨在加速新 Playstation 3 上的游戏应用)中,传统处理器将计算密集型任务卸载到可以直接访问内存的协同处理元件。但是,当今涌现的最令人兴奋的异构计算领域之一是采用现场可编程门阵列或 FPGA。
FPGA 是硬件可重构设备,程序员可以反复重新设计它们,以更有效地解决特定类型的问题。FPGA 作为可编程逻辑设备已使用十多年,但现在作为可重构协处理器正引起更强烈的兴趣。最近在美国和国外举行了几次关于 FPGA 的开创性会议,俄亥俄州超级计算机中心最近成立了 OpenFPGA (www.openfpga.org) 倡议,以加速 FPGA 在 HPC 和企业环境中的应用。
这种热情是有原因的:在某些类型的应用程序上,FPGA 可以比传统处理器提供数量级的改进。FPGA 允许设计人员为给定的应用程序创建自定义指令集,并将数百甚至数千个处理元件同时应用于一个操作。对于需要大量位操作、加法、乘法、比较、卷积或变换的应用程序,FPGA 可以一次在数千个数据片段上执行这些指令,与传统处理器相比,控制开销和功耗更低。
FPGA 在广泛采用方面也有其历史性障碍。首先,它们传统上是通过 PCI 总线集成到传统系统中的,这限制了它们的有效性,就像上述专用处理器一样。更重要的是,使软件能够与 FPGA 互操作极其困难,因为 FPGA 必须使用硬件描述语言 (HDL) 进行编程。尽管这些语言对于电子设计人员来说很常见,但对于大多数 HPC 系统设计人员、软件程序员和用户来说,它们是完全陌生的。如今,允许软件设计人员以熟悉的方式为 FPGA 编程的工具才刚刚开始出现。用户也在等待将现有标量代码移植到异构 FPGA 协处理器系统的工具。然而,Cray 和其他公司正在努力消除这些问题。
例如,Cray XD1(首批将 FPGA 用作用户可编程加速器的商用 HPC 系统之一)通过将 FPGA 直接集成到互连中并将 FPGA 紧密集成到系统的 HPC 优化 Linux 操作系统中,消除了许多性能限制。新的工具还允许用户使用更高级别的 C 类型语言为 FPGA 协处理器系统编程。这些工具包括 Celoxica DK Design Suite(一个正在与 Cray XD1 集成的 C 到 FPGA 编译器)、Impulse C、Mitrion C 和 Matlab 的 Simulink-to-FPGA,后者提供了一种基于模型的设计方法。
最终,随着包含 FPGA 的异构系统变得越来越广泛使用,我们相信它们将允许用户比近期通过摩尔定律提供的任何东西更快地解决某些类型的问题,甚至支持一些以前不可能的应用。(有关 FPGA 协处理器系统的潜力的示例,请参阅关于 Smith-Waterman 生物信息学应用的侧边栏。)
Smith-Waterman:异构计算的 FPGA 协处理器方法示例
基因组学的新技术可以从少量测试中提供数百万个 DNA 片段,但将大量的原始数据转化为有意义的结果可能是一个漫长而艰巨的过程。基因通常表示为核苷酸的有序序列。(类似地,蛋白质序列是氨基酸的字符串。)研究人员可以仅从基因和蛋白质的序列中推断出大量信息,并通过将样本序列与已分类的序列进行比较来回答诸如不同物种中基因的相似性等问题。然而,为此,准确确定两个序列之间相似性的方法至关重要。
Smith-Waterman 是用于完成此任务的最强大的算法(Temple F. Smith 和 Michael S. Waterman,“Common Molecular Subsequences 的识别”,J. Mol. Biol., 147:195—197, 1981)。但是所涉及的数学运算对于商品处理器来说很困难,并且传统系统提供的性能极差。通过使用 Cray XD1(一种将标量处理与 FPGA 协处理器相结合的异构系统)来解决这个问题,研究人员可以加速 Smith-Waterman 并获得比传统系统快 40 倍的结果。
Smith-Waterman 的特性
Smith-Waterman 算法将样本 DNA 或蛋白质与现有数据库进行比较。由于样本和数据库都可能存在缺失或添加字符形式的错误——并且由于几个字符的变异可能表示重大的生物学差异——因此需要高度准确的匹配过程。
基因序列包含四个字母(G、C、A 和 T),代表四种核苷酸,蛋白质序列包含 20 个氨基酸字符。由于序列是有序字符串,因此准确的比较必须确定两个字符串是否对齐,以及它们共享的字母。(例如,在简单的英语中,STOP 和 POTS 共享相同的字母,但不能令人满意地对齐,而 POTS 和 POINTS 可以,如果在 POTS 中的 O 和 T 之间创建间隙。)Smith-Waterman 使用“动态编程”来找到最佳对齐方式。这需要大量的简单并行计算以及大量的位操作,而商品标量处理器在这些操作中效率极低。
运行 Smith-Waterman 的传统处理器需要数千个独特的步骤来比较每个数据片段。用于执行实际比较的指令数量仅占用于确定下一个比较点和周围逻辑的指令数量的一小部分。事实上,标量处理器可能每 100 条指令中只用一条指令进行比较——效率率仅为 1%。
使用 FPGA 协处理器的 HPC 系统可以提供几个优势来加速此算法。首先,与旨在支持多种不同类型代码的通用处理器不同,FPGA 允许使用与应用程序紧密相关的自定义指令集。FPGA 还提供大量的固有并行性,并且可以被编程为并排构建数千个比较单元,并在每个时钟周期执行数千次比较。此外,硬件计算在位操作方面本质上比软件更有效。
Cray XD1 方法
为了充分理解 Cray XD1 如何加速 Smith-Waterman,有必要了解系统独特的 FPGA 协处理器架构(图 1)以及应用程序本身的功能。

图 1. Cray XD1 系统架构
Smith-Waterman 通过首先创建一个评分矩阵并根据上方和左侧单元格的值计算每个单元格来制定匹配项。一旦创建了这个矩阵,该算法就会计算一个最大分数,沿导致该分数的路径回溯,并交付最终的对齐方式(图 2 和图 3)。
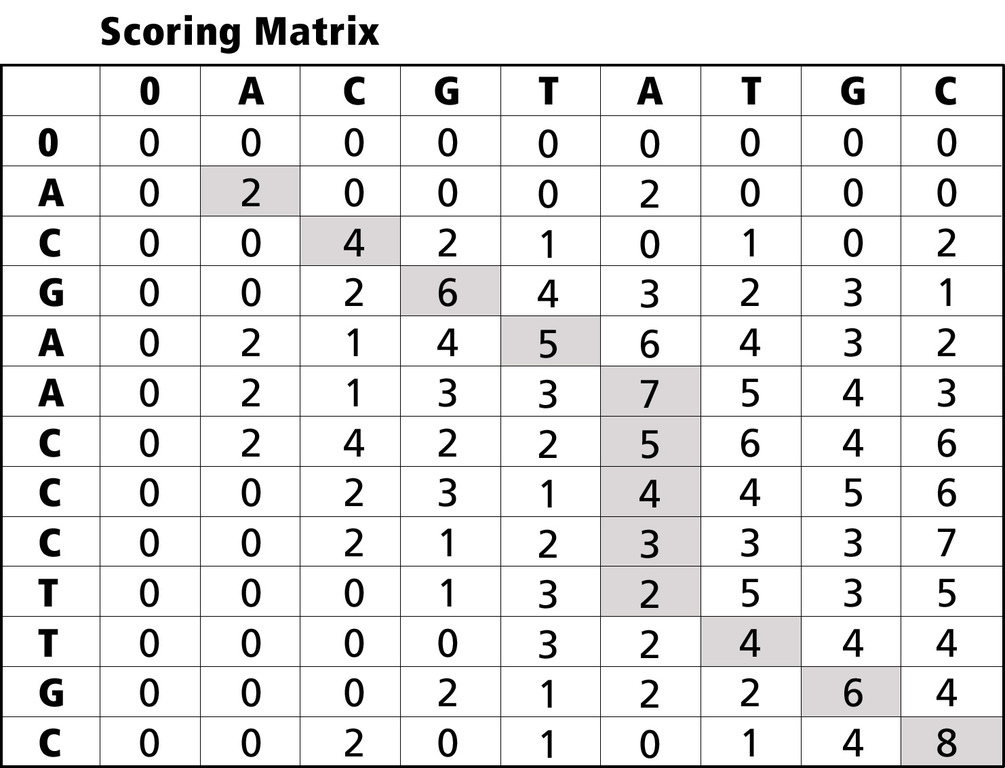
图 2. 评分矩阵

图 3. Smith-Waterman 公式
为了加速此操作,Cray XD1 在系统的 FPGA 和 Opteron 处理器之间划分算法。系统使用 FPGA 填充评分矩阵(涉及并行计算),并将回溯信息发送回 Opteron 以重新生成矩阵(串行操作)。实际上,系统的 HPC 优化 Linux 操作系统仅为 Smith-Waterman 应用程序的内核调用 FPGA。但是,FPGA 协处理器提供的大量并行性使结果比传统 HPC 架构快 25 到 40 倍。以下是系统与 FPGA 交互的示例
/* Tilt the arrays by copying them to the FPGA. */
static void tilt (int fp_id, u_64 *trans_matrix, int row_len)
{
int i = 0;
u_64 status = 0;
/* Initialize the FPGA to accept a new stream of arrays. */
fpga_wrt_appif_val (fp_id, TILT_START, TILT_APP_CFG, TYPE_VAL, &e);
/* Copy the matrix to the FPGA. */
memcpy((char *) fpga_ptr, (char *) trans_matrix,
row_len*sizeof(u_64));
/* Poll to see if the FPGA has completed tilting the arays. */
while (1) {
fpga_rd_appif_val (fp_id, &status, TILT_APP_STAT, &e);
if (status & TILT_DONE) break;
}
/* When the FPGA has finished, all the transposed data will have */
/* been written by the FPGA to the transfer region of DRAM. */
/* Copy the data from the transfer region back to the array. */
// for(i=0;i<row_len;i++) {
// trans_matrix[i] = dram_ptr[i];
//}
return;
}
Cray XD1 异构架构的优势
借助 Cray XD1 提供的应用程序加速,用户可以使用可用的最佳算法获得更及时的结果,而不是满足于提供不太准确的解决方案但速度更快的工具。而且,由于系统仅将 FPGA 协处理器用于 Smith-Waterman 的内核,因此可以随着应用程序其余部分的演进而轻松更新它。此外,与研究人员可用的专用硬件解决方案不同,Cray XD1 是一个真正的通用 HPC 系统。它不仅限于运行单个代码,而且可以像 Smith-Waterman 一样轻松地应用于其他生物信息学应用。简而言之,Cray XD1 为在关键生命科学应用中提供前所未有的性能提供了一种有效、经济实惠且受投资保护的解决方案。
Amar Shan 是全球超级计算机领导者 Cray Inc. 的高级产品经理。Shan 于 2004 年加入 Cray,当时 Cray 收购了 OctigaBay Systems Corporation,负责为 Cray 的下一代产品和 Cray XD1 高性能计算 (HPC) 系统(唯一专为 HPC 应用设计的 Linux/Opteron 系统)设定产品方向。Shan 拥有滑铁卢大学人工智能应用科学硕士学位和不列颠哥伦比亚大学电气工程和计算机科学应用科学学士学位。
