
嵌入 db4o 面向对象数据库
db4o 是 db4objects 提供的开源面向对象数据库。它是可嵌入的,因为整个 db4o 引擎都以单个库的形式提供,可以链接到您的应用程序中。db4o 有 Java 和 .NET/Mono 版本。因此,它是用 Java 或 .NET 框架编写的 Linux 应用程序的理想 OODBM 引擎。在本文中,提供的示例是用 C# 编写的,并在 Ubuntu Linux 系统上运行的 Mono 中进行了测试。(我们还在 Monoppix 系统上运行了这些应用程序。)
除了是一个开源库(因此您可以立即下载并开始试验其功能)之外,db4o 的另一个突出特点是其简洁、易于理解的 API。在大多数情况下,您将使用一组九个基本调用中的方法。此外,该库的内存占用量不大,使其成为资源受限的应用程序的理想选择(尽管 db4o 绝不是不能胜任企业级工作的)。
尽管 db4o 占用空间小且编程接口简单,但它提供了您期望从商业数据库引擎获得的所有功能:它允许多用户访问,数据库上的任何访问都以事务形式不可见地包装,并且所有操作都遵循 ACID 原则(原子性、一致性、隔离性和持久性)。
与某些面向对象和对象关系数据库系统不同,db4o 不要求您通过检测预编译或后编译步骤来传递代码。也不必使要持久化的对象的类派生自特殊的持久性感知超类。db4o 很高兴与普通对象一起工作,您无需在将对象存储到 db4o 数据库之前告知其结构。
正如我们希望展示的那样,这为我们提供了一些意想不到的功能。
假设我们的应用程序是一个字典——经典意义上的字典。也就是说,该应用程序操作一个存储单词及其定义的数据库。在这样的应用程序中,我们可以定义一个类来对字典条目进行建模,如下所示
/*
* DictEntry
*/
using System;
using System.Collections;
namespace PersistentTrees
{
/// <summary>
/// DictEntry class
/// A dictionary entry
/// </summary>
public class DictEntry
{
private string theWord;
private string pronunciation;
private ArrayList definitions;
public DictEntry()
{
}
// Create a new Dictionary Entry
public DictEntry(string _theWord,
string _pronunciation)
{ theWord = _theWord;
pronunciation = _pronunciation;
definitions = new ArrayList();
}
// Add a definition to this entry
// Note that we do not check for duplicates
public void add(Defn _definition)
{
definitions.Add(_definition);
}
// Retrieve the number of definitions
public int numberOfDefs()
{
return definitions.Count;
}
// Clear the definitions array
public void clearDefs()
{
definitions.Clear();
definitions.TrimToSize();
}
// Properties
public string TheWord
{
get { return theWord; }
set { theWord = value; }
}
public string Pronunciation
{
get { return pronunciation; }
set { pronunciation = value; }
}
// Get reference to the definitions
public ArrayList getDefinitions()
{
return definitions;
}
}
}
一个 DictEntry 对象由三个元素组成:单词本身、其发音和定义列表。同时,描述定义对象的类可能如下所示
/*
* Defn
*
*/
using System;
namespace PersistentTrees
{
/// <summary>
/// Description of Class1.
/// </summary>
public class Defn
{
public static int NOUN = 1;
public static int PRONOUN = 2;
public static int VERB = 3;
public static int ADJECTIVE = 4;
public static int ADVERB = 5;
public static int CONJUNCTION = 6;
public static int PARTICIPLE = 7;
public static int GERUND = 8;
private int pos;
private string definition;
public Defn(int _pos,
string _definition)
{
pos = _pos;
definition = _definition;
}
// Properties
public int POS
{
get { return pos; }
set { pos = value; }
}
public string Definition
{
get { return definition; }
set { definition = value; }
}
}
}
因此,一个 Defn 对象包含一个整数成员,指示词性和一个字符串成员,其中包含定义的文本。这种结构允许我们将多个定义与字典中的单个条目关联起来。
将此类条目存储到 db4o 数据库中非常简单。假设我们要将单词 float 添加到我们的字典中,并为其提供三个定义
Defn _float1 = new Defn(VERB, "To stay on top of a liquid.");
Defn _float2 = new Defn(VERB, "To cause to float.");
Defn _float3 = new Defn(NOUN, "Anything that stays on top of water.");
DictEntry _float = new DictEntry("float", "flote");
_float.add(_float1);
_float.add(_float2);
_float.add(_float3);
此时,我们有一个 DictEntry 对象 _float,其定义列表包含三个项目。
首先,我们打开数据库本身。db4o 数据库由 ObjectContainer 对象建模,我们可以使用以下命令打开(或创建,如果不存在)ObjectContainer
ObjectCointainer db = Db4o.openFile("<filename>");
其中 <filename> 是保存 ObjectContainer 持久内容的文件的路径。您可以使用 set() 方法将对象放入 ObjectContainer 中。因此,我们可以使用以下命令存储我们的新定义
db.set(_float);
信不信由你,这几乎是您需要了解的关于 set() 方法的全部内容。这一个调用不仅存储了 _float DictEntry 对象,还存储了它包含的所有 Defn 对象。当您调用 db4o 的 set() 方法时,db4o 引擎会不可见地遍历对象的引用,自动持久化所有子对象。只需将复杂对象树的根对象传递给 set(),整个 shebang 就会一次性存储。您不必告诉 db4o 您的对象的结构;它会自动发现它。
要从 ObjectContainer 中检索对象,我们在 db4o 的 QBE(按示例查询)机制的帮助下找到它。QBE 风格的查询由示例或模板对象引导。更具体地说,您可以通过创建模板对象、使用您想要匹配的值填充其字段、向查询系统显示模板对象并说“看到这个了吗?去获取所有看起来像这个的对象”来执行查询。
因此,假设您想要检索 float 的定义,该过程看起来像这样
// Create template
DictEntry DTemplate = new DictEntry("float", "");
// Execute QBE
ObjectSet results = db.get(DTemplate);
// Iterate through results set
while(results.hasNext())
{
DictEntry _entry = (DictEntry)results.next();
... process the DictEntry object ...
}
首先,我们创建模板对象,用我们感兴趣的值填充我们想要匹配的字段。不应参与查询的字段用零、空字符串或 null 填充——具体取决于数据类型。(在上面的示例中,我们只是在字典中查找单词 float。我们在模板对象构造函数的发音字段中放置了一个空字符串,因为发音与查询无关。)
然后,我们通过调用 ObjectContainer 的 get() 方法来执行查询,并将模板对象作为单个参数传入。查询返回一个 ObjectSet,我们可以通过它迭代来检索匹配结果。
此时,我们可以轻松地创建一个数据库,用单词和定义填充它,并使用 db4o 的 QBE 机制检索它们。但是,如果我们想试验不同的索引驱动的检索机制怎么办?由于数据库保留了持久对象之间的关系,我们可以创建自定义索引和导航结构,将它们也放入数据库中,并将我们的数据对象“连接”到这些结构中。
我们通过创建两个不同的索引方案来说明这有多么简单。
首先,我们创建一个二叉树。树的每个节点都携带一个键/数据对作为其有效负载。键将是字典中的文本单词,关联的数据项将是对数据库中 DictEntry 对象的引用。因此,我们可以从数据库中获取二叉树,执行字典中特定单词的搜索,并获取匹配的 DictEntry 对象(如果找到)。
二叉树的架构和行为是众所周知的,因此我们在此不再赘述。(事实上,许多框架现在将它们作为标准数据结构提供。我们创建了一个显式的,以展示它可以多么容易地存储在数据库中。)我们的实现出现在清单 1 中。它是基本的,仅支持插入和搜索。它不保证平衡树,但它用于说明目的。定义二叉树中节点结构的 TreeNode 类出现在清单 2 中。(注意,我们稍后将解释清单 1 中对 db.activate() 的调用的目的。)
清单 1. 二叉树
/*
* Binary Tree
*/
using System;
using com.db4o;
namespace PersistentTrees
{
/// <summary>
/// Description of BinaryTree.
/// </summary>
public class BinaryTree
{
// The tree's root
private TreeNode root;
public BinaryTree()
{
root = null;
}
public static BinaryTree nullfactory()
{
return(new BinaryTree());
}
// insert
// Add key to tree with associated object reference
public void insert(string _key, Object _data)
{
// Use recursion for this
root = insert(root, _key, _data);
}
// insert
// This is worker method for inserting key and data
// Insert _key into subtree t with _data associated
private TreeNode insert(TreeNode t, string _key, Object_data)
{
// If this subtree is empty, build a new node
if(t == null)
t = new TreeNode(_key, _data);
else
if(_key.CompareTo(t.Key)<=0)
t.Left = insert(t.Left,_key,_data);
else
t.Right = insert(t.Right,_key,_data);
return(t);
}
// search
// Search for a key in the tree.
// Return the array from the TreeNode if found, null if
// not
// db is the ObjectContainer holding the tree.
public Object[] search(string _key,
ObjectContainer db)
{
TreeNode t = search(root, _key, db);
if(t==null) return(null); // Not found
db.activate(t,4); // Activate to get data
return(t.getData());
}
// search
// This is the worker method for searching.
private TreeNode search(TreeNode t,
string _key,
ObjectContainer db)
{
// Empty tree?
if(t==null) return(null);
if(_key.CompareTo(t.Key)==0) return(t);
if(_key.CompareTo(t.Key)<0)
{
db.activate(t.Left,2);
return(t = search(t.Left,_key,db));
}
db.activate(t.Right,2);
return(t = search(t.Right,_key,db));
}
}
}
清单 2. TreeNode 类
/*
* TreeNode
*/
using System;
namespace PersistentTrees
{
/// <summary>
/// Description of TreeNode.
/// </summary>
public class TreeNode
{
public TreeNode()
{
}
private TreeNode left; // Left child
private TreeNode right; // Right child
private string key; // Key for this node
private Object[] data; // Data associated with key
// Create a new TreeNode, loaded with
// key and data.
public TreeNode(string _key, Object _data)
{
left = null;
right = null;
key = _key;
data = new Object[1];
data[0] = _data;
}
// addData
// Adds new data item to an existing node.
// The array is extended.
public void addData(Object _data)
{
Object[] newdata = new Object[data.Length+1];
Array.Copy(data,0,newdata,0,data.Length);
newdata[data.Length]=_data;
data = newdata;
}
// Property access
public TreeNode Left
{
get { return left; }
set { left = value; }
}
public TreeNode Right
{
get { return right; }
set { right = value; }
}
public string Key
{
get { return key; }
set { key = value; }
}
public Object[] getData()
{
return data;
}
}
}
接下来,我创建一个 trie,这是一种专门用于搜索文本单词的索引数据结构。它构建为一系列按级别排列的节点——每个级别包含一组字符和关联的指针,使得最顶层(或根)级别上的字符对应于单词的第一个字符位置中的字母;第二级中的字符对应于第二个字符位置中的字母,依此类推。与每个字符关联的引用用于像线上的珠子一样“串联”字符,以便从根向下到树的线程拼出正在搜索的单词。
如果这难以可视化,图 1 中的插图应该有所帮助。
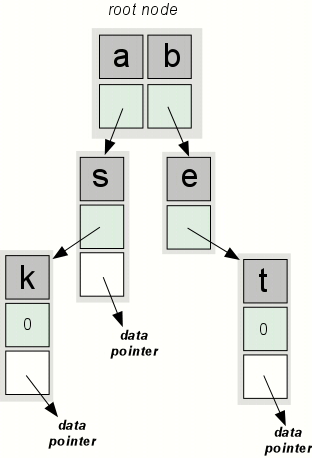
图 1. trie。在 trie 索引中,单词中的单个字符存储在不同的节点级别。这个特定的 trie 包含三个单词:as、ask 和 bet。数据指针实际上是对与相应单词关联的 DictEntry 对象的引用。
将新单词插入到 trie 中相对简单。从第一个匹配字符开始,您检查根节点以查看该字符是否存在。如果不存在,则添加它,从那时起,算法在处理目标单词时插入新节点(每个节点都用后续字母初始化)。如果字符确实存在,则算法遵循关联的指针到下一级,并重复检查过程。最终,您已经考虑了单词中的每个字符,并且您所在的节点是您附加数据引用的节点。
搜索 trie 也同样简单。从根开始,查找第一个字符。如果找到该字符,则遵循关联的引用到下一个节点;否则,返回“未找到”错误。否则,移动到下一个字符,重复,如果您完成了整个单词,则与终端字符关联的数据节点指向 DictEntry 对象。
trie 的代码如清单 3 所示。
清单 3. Trie
/*
* Trie
*/
using System;
using com.db4o;
namespace PersistentTrees
{
/// <summary>
/// Description of Trie.
/// </summary>
/// trie class
public class Trie
{
private TriePnode root; // Root of Trie
// Constructor
public Trie()
{
root = null;
}
// insert
// Insert a key/data pair into the tree.
// Allows duplicates
public void insert(string key, // Key to insert
Object data) // Data assoc. with key
{
TriePnode t = root;
TriePnode parent = null;
int index=0;
int slen = key.Length;
for(int i=0; i< slen; i++)
{
char c = key[i];
// If a node doesn't exist -- create it
if(t == null) t = new TriePnode();
// If this is the first node of the tree,
// it is the
// root. Otherwise, it is stored in the
// pnodes array
// of the parent
if(i==0)
root = t;
else
parent.setPnodePointer(index, t);
// If the character is not on the node,
// add it
if((index=t.isCharOnNode(c))==-1)
index = t.addKeyChar(c);
if(i == slen-1) break;
parent = t;
t = t.getPnodePointer(index);
}
// Finally, add the data item
t.addData(index, data);
}
// search
// Searches for a string in the trie.
// If found, returns the Object[] data array associated.
// Else, returns null
// db is the ObjectContainer holding the trie
public Object[] search(string _key,
ObjectContainer db)
{
TriePnode t;
char c;
int index=0;
// Empty trie?
if((t=root)==null) return(null);
int slen = _key.Length;
for(int i=0; i<slen; i++)
{
c = _key[i];
if((index=t.isCharOnNode(c))==-1)return(null);
if(i==slen-1) break;
db.activate(t,2);
t = t.getPnodePointer(index);
}
// Get the data
db.activate(t,3);
return(t.getDnodePointers(index).getData());
}
}
}
正如用于插入和搜索二叉树和 trie 的代码所说明的那样,我们可以像处理纯内存对象一样处理数据库对象。具体来说,我们可以通过简单地将其对象引用存储在数据引用元素中来将对象附加到索引。
此外,由于数据库不区分索引对象和数据对象,因此我们无需创建单独的索引和数据文件。这使所有内容都集中在一个位置,实际上比人们最初想象的更有优势。
用于读取包含单词和定义的文本文件、创建 DictEntry 对象并将它们存储在数据库中,以及构建二叉树和 trie 索引 并 将 DictEntry 对象附加到它们的代码如下所示
string theword;
string pronunciation;
int numdefs;
int partofspeech;
string definition;
DictEntry _dictEntry;
// Open a streamreader for the text file
FileInfo sourceFile = new FileInfo(textFilePath);
reader = sourceFile.OpenText();
// Open/create the database file
ObjectContainer db = Db4o.openFile(databaseFilePath);
// Create an empty Binary tree, and an empty trie
BinaryTree mybintree = new BinaryTree();
Trie mytrie = new Trie();
// Sit in an endless loop, reading text,
// building objects, and putting those objects
// in the database
while(true)
{
// Read a word.
// If we read a "#", then we're done.
theword = ReadWord();
if(theword.Equals("#")) break;
// Read the pronunciation and put
// it in the object
pronunciation = ReadPronunciation();
_dictEntry = new DictEntry(theword, pronunciation);
// Read the number of definitions
numdefs = ReadNumOfDefs();
// Loop through definitions. For each,
// read the part of speech and the
// definition, add it to the definition
// array.
for(int i=0; i<numdefs; i++)
{
partofspeech = ReadPartOfSpeech();
definition = ReadDef();
Defn def = new Defn(partofspeech, definition);
_dictEntry.add(def);
}
// We've read all of the definitions.
// Put the DictEntry object into the
// database
db.set(_dictEntry);
// Now insert _dictEntry into the binary tree
// and the trie
mybintree.insert(_dictEntry.TheWord, _dictEntry);
mytrie.insert(_dictEntry.TheWord, _dictEntry);
}
// All done.
// Store the binary tree and the trie
db.set(mybintree);
db.set(mytrie);
// Commit everything
db.commit();
当然,这假定了一些用于读取源文件的辅助方法,但逻辑流程仍然很明显。再次注意,我们只需通过对 db.set() 的单个调用存储根来存储每个索引——全部。
从数据库中获取某些内容只是稍微棘手一些。尽管我们希望将持久对象与瞬态对象相同对待,但我们不能。磁盘上的对象必须读取到内存中,这需要显式获取。初始获取当然是对 db.get() 的调用,以找到索引的根。因此,允许我们使用二叉树或 trie 索引搜索单词的代码将如下所示
public static void Main(string[] args)
{
Object[] found;
DictEntry _entry;
// Verify proper number of arguments
if(args.Length !=3)
{
Console.WriteLine("usage: SearchDictDatabase <database> B|T <word>");
Console.WriteLine("<database> = path to db4o database");
Console.WriteLine("B = use binary tree; T = use trie");
Console.WriteLine("<word> = word to search for");
return;
}
// Verify 2nd argument
if("BT".IndexOf(args[1])==-1)
{
Console.WriteLine("2nd argument must be B or T");
return;
}
// Open the database file
ObjectContainer db = Db4o.openFile(args[0]);
if(db!=null) Console.WriteLine("Open OK");
// Switch on the 2nd argument (B or T)
if("BT".IndexOf(args[1])==0)
{ // Search binary tree
// Create an empty binary tree object for the
// search template
BinaryTree btt = new BinaryTree();
ObjectSet result = db.get(btt);
BinaryTree bt = (BinaryTree) result.next();
// Now search for the results
found = bt.search(args[2],db);
}
else
{ // Search trie
// Create an empty trie object fore the search
// template
Trie triet = new Trie();
ObjectSet result = db.get(triet);
Trie mytrie = (Trie) result.next();
// Now search for the results
found = mytrie.search(args[2],db);
}
// Close the database
db.close();
// Was it in the database?
if(found == null)
{
Console.WriteLine("Not found");
return;
}
// Fetch the DictEntry
_entry = (DictEntry)found[0];
... <Do stuff with _entry here> ...
现在我们可以解释清单 1 和 3 的搜索方法中对 db.activate() 的调用的目的。
正如我们解释的那样,当您调用 db.set() 方法时,db4o 引擎会遍历对象树,持久化所有可访问的对象。(这称为通过可达性持久化。)在相反的方向——即调用 db.get() 获取对象——db4o 不会将整个对象树从数据库中拉出来。如果它这样做,那么例如,获取二叉索引的根将导致 db4o 将整个索引,加上所有字典条目,加上所有定义一次性拉入内存——如果我们只想要一个单词,效率不高。
相反,db4o 使用一个称为激活深度的概念。假设我使用 db.get() 调用从 db4o 数据库中将对象 A 获取到内存中。如果我随后调用 db.activate(A,6),则告诉 db4o 也将 A 引用的所有对象获取到内存中,深度最多为 6。因此,散布在二叉树和 trie 类的搜索例程中的 db.activate() 调用确保搜索操作始终拉入足够的索引,以便搜索可以继续进行。(并且,在成功搜索结束时,会获取字典对象。)
OO 数据库为开发人员提供了使用 RDBMS 不易获得的灵活性。特别是,您可以设计复杂、深层的对象结构,将它们持久化到数据库,而无需担心对象模型和关系模型之间的转换。
OO 数据库 db4o 的易于理解的 API 并没有妨碍我们在数据库端与实际数据并排构建索引结构。尽管我们选择的二叉树和 trie 索引很简单,但它们证明了开发人员可以自由地使用任意复杂性的自定义索引和导航结构来扩充数据库。因此,我们可以定制一个组织方案,使其符合应用程序对其数据的要求,并且我们可以使用普通的旧对象——Java 或 Mono/.NET 来设计它。最重要的是,db4o 是开源的,因此没有什么可以阻止您为您的下一个数据库应用程序抓取它。有关 db4o 的更多信息,请访问 www.db4objects.com。
Rick Grehan 的文章曾发表在 Byte、Embedded Systems Journal、JavaPro、InfoWorld、Microprocessor Report 和其他几家期刊上。他是三本书的合著者:一本关于远程过程调用,另一本关于嵌入式系统,第三本关于面向对象的 Java 数据库。目前,他是 Compuware NuMega 实验室的 QA 负责人。

